
Google trends chart¶
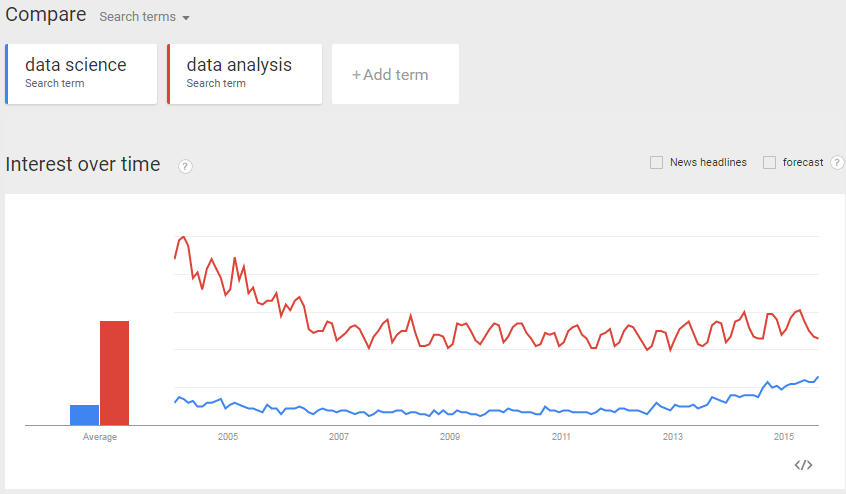
Data Science¶
According to https://en.wikipedia.org/wiki/Data_science:
In November 1997, C.F. Jeff Wu gave the inaugural lecture entitled "Statistics = Data Science?"[5] for his appointment to the H. C. Carver Professorship at the University of Michigan.[6] In this lecture, he characterized statistical work as a trilogy of data collection, data modeling and analysis, and decision making. In his conclusion, he initiated the modern, non-computer science, usage of the term "data science" and advocated that statistics be renamed data science and statisticians data scientists.[5]
The Github Archive Dataset¶
https://www.githubarchive.org/
Open-source developers all over the world are working on millions of projects: writing code & documentation, fixing & submitting bugs, and so forth. GitHub Archive is a project to record the public GitHub timeline, archive it, and make it easily accessible for further analysis.
GitHub provides 20+ event types, which range from new commits and fork events, to opening new tickets, commenting, and adding members to a project. These events are aggregated into hourly archives, which you can access with any HTTP client:
- gzipped json files
- yyyy-mm-dd-HH.json.gz
import os
import gzip
import ujson as json
directory = 'data/github_archive'
filename = '2015-01-29-16.json.gz'
path = os.path.join(directory, filename)
with gzip.open(path) as f:
events = [json.loads(line) for line in f]
#print json.dumps(events[0], indent=4)
{
"payload": {
"master_branch": "master",
"ref_type": "branch",
"ref": "disable_dropdown",
"description": "OOI UI Source Code",
"pusher_type": "user"
},
"created_at": "2015-01-29T16:00:00Z",
"actor": {
"url": "https://api.github.com/users/birdage",
"login": "birdage",
"avatar_url": "https://avatars.githubusercontent.com/u/547228?",
"id": 547228,
"gravatar_id": ""
},
"id": "2545235518",
"repo": {
"url": "https://api.github.com/repos/birdage/ooi-ui",
"id": 23796192,
"name": "birdage/ooi-ui"
},
"type": "CreateEvent",
"public": true
}
Typical Questions¶
- How many Github repositories are created per hour/day/month?
- To which repositories are the most commits are pushed per hour/day/month?
- Which projects receive the most pull requests?
- What are the most popular languages on Github?
Example 1 - Number of Repositories Created¶
new_repo_count = 0
for event in events:
new_repo_count += \
1 if event['type']=="CreateEvent" else 0
print new_repo_count
3516
Example 2 - Number of commits pushed per repository¶
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
def print_top_items(dct, N=5):
sorted_items = sorted(
dct.iteritems(), key=lambda t: t[1], reverse=True)
for key, value in sorted_items[:N]:
print "{:40} {}".format(key, value)
print_top_items(repo_commits)
eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001
The Split-Apply-Combine Pattern¶
Hadley Wickham 
Hadley Wickham, the man who revolutionized R
*If you don’t spend much of your time coding in the open-source statistical programming language R, his name is likely not familiar to you -- but the statistician Hadley Wickham is, in his own words, “nerd famous.” The kind of famous where people at statistics conferences line up for selfies, ask him for autographs, and are generally in awe of him.
from IPython.display import HTML
HTML('<iframe src="http://www.jstatsoft.org/v40/i01" width=800 height=400></iframe>')

- StackOverflow: split-apply-combine tag
- Pandas documentation: Group By: split-apply-combine
- PyTools documentation: Split-apply-combine with groupby and reduceby
- Blaze documentation: Split-Apply-Combine - Grouping
- R plyr: plyr: Tools for Splitting, Applying and Combining Data
- Julia documentation: The Split-Apply-Combine Strategy
The Basic Pattern¶
- Split the data by some grouping variable
- Apply some function to each group independently
- Combine the data into some output dataset
- The apply step is usually one of
- aggregate
- transform
- or filter
Example 2 - examined¶
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001
This
- filters out only the "PushEvent"s
- splits the dataset by repository
- sums the commits for each group
- combines the groups and their sums into a dictionary
Pandas - Python Data Analysis Library¶
![]()
- Provides high-performance, easy-to-use data structures and data analysis tools.
- Provides core data structure DataFrame
pandas.DataFrame¶
- Basically in-memory database tables (or spreadsheets!)
- Tabular data that allows for columns of different dtypes
- Labeled rows and columns (index)
- Hierarchical indexing allows for representing Panel data
import numpy as np
import pandas as pd
from collections import namedtuple
GithubEvent = namedtuple('GithubEvent', ['type_', 'user', 'repo', 'created_at', 'commits'])
def make_record(event):
return GithubEvent(
event['type'], event['actor']['login'],
event['repo']['name'], pd.Timestamp(event['created_at']),
event['payload']['size'] if event['type']=='PushEvent' else np.nan
)
df = pd.DataFrame.from_records(
(make_record(ev) for ev in events),
columns=GithubEvent._fields, index='created_at')
df.head()
| type_ | user | repo | commits | |
|---|---|---|---|---|
| created_at | ||||
| 2015-01-29 16:00:00+00:00 | CreateEvent | birdage | birdage/ooi-ui | NaN |
| 2015-01-29 16:00:00+00:00 | PushEvent | ArniR | ArniR/ArniR.github.io | 1 |
| 2015-01-29 16:00:00+00:00 | IssueCommentEvent | CrossEye | ramda/ramda | NaN |
| 2015-01-29 16:00:00+00:00 | PushEvent | yluoyu | yluoyu/demo | 1 |
| 2015-01-29 16:00:00+00:00 | IssueCommentEvent | EJBQ | prmr/JetUML | NaN |
Example 1 (using Pandas) - Number of Repositories Created¶
df[df.type_=='CreateEvent'].head()
| type_ | user | repo | commits | |
|---|---|---|---|---|
| created_at | ||||
| 2015-01-29 16:00:00+00:00 | CreateEvent | birdage | birdage/ooi-ui | NaN |
| 2015-01-29 16:00:02+00:00 | CreateEvent | filipe-maia | Lucas-Andrade/ProjectManager_FLM | NaN |
| 2015-01-29 16:00:02+00:00 | CreateEvent | filipe-maia | Lucas-Andrade/ProjectManager_FLM | NaN |
| 2015-01-29 16:00:02+00:00 | CreateEvent | frewsxcv | frewsxcv/gargoyle | NaN |
| 2015-01-29 16:00:03+00:00 | CreateEvent | schnere | bluevisiontec/GoogleShoppingApi | NaN |
len(df[df.type_=='CreateEvent'])
3516
Example 2 (using Pandas) - Number of commits pushed per repo¶
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001
repo_commits = df[df.type_=='PushEvent'].groupby('repo').commits.sum()
repo_commits.sort(ascending=False)
repo_commits.head(5)
repo eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001 Name: commits, dtype: float64
Example 1 - revisited¶
event_counts = df.groupby('type_').repo.count()
event_counts.sort(ascending=False)
event_counts.head()
type_ PushEvent 15443 IssueCommentEvent 3718 CreateEvent 3516 WatchEvent 2682 PullRequestEvent 1891 Name: repo, dtype: int64
Great for interactive work:
- tab-completion!
- inspect data with
df.head()&df.tail() - quick overview of data ranges with
df.describe()

However ...
Pandas currently only handles in-memory datasets!¶
So not suitable for big data!¶

MapReduce¶
"If you want to process Big Data, you need some MapReduce framework like one of the following"
![]()
![]()

The key to these frameworks is adopting a functional [programming] mindset. In Python this means, think iterators!
See The Structure and Interpretation of Computer Programs (the "Wizard book")
- in particular Chapter 2 Building Abstractions with Data
- and Section 2.2.3 Sequences as Conventional Interfaces
Luckily, the Split-Apply-Combine pattern is well suited to this!
Example 1 - revisited¶
new_repo_count = 0
for event in events:
new_repo_count += \
1 if event['type']=="CreateEvent" else 0
print new_repo_count
3516
reduce(lambda x,y: x+y,
map(lambda ev: 1 if ev['type']=='CreateEvent' else 0,
events))
3516
Would prefer to write
events | map(...) | reduce(...)
Example 1 - pipelined¶
def datapipe(data, *transforms):
for transform in transforms:
data = transform(data)
return data
datapipe(
events,
lambda events: map(lambda ev: 1 if ev['type']=='CreateEvent' else 0, events),
lambda counts: reduce(lambda x,y: x+y, counts)
)
3516
PyToolz¶
Example 1 - pipeline using PyToolz¶
from toolz.curried import pipe, map, reduce
pipe(events,
map(lambda ev: 1 if ev['type']=='CreateEvent' else 0),
reduce(lambda x,y: x+y)
)
3516
Example 2 - pipelined with PyToolz¶
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001
from toolz.curried import filter, reduceby
pipe(events,
filter(lambda ev: ev['type']=='PushEvent'),
reduceby(lambda ev: ev['repo']['name'],
lambda commits, ev: commits+ev['payload']['size'],
init=0),
print_top_items
)
eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001
The Point of Learning Patterns¶
From Cosma Shalizi's Statistical Computing course:
- Distinguish between what you want to do and how you want to do it.
- Focusing on what brings clarity to intentions.
- How also matters, but can obscure the high level problem.
Learn the pattern, recognize the pattern, love the pattern!
Re-use good solutions!
Iteration Considered Unhelpful¶
Could always do the same thing with for loops, but those are
- verbose - lots of "how" obscures the "what"
- painful/error-prone bookkeeping (indices, placeholders, ...)
- clumsy - hard to parallelize
Out-of-core processing - toolz example¶
def count_commits(filename):
import gzip
import json
from toolz.curried import pipe, filter, reduceby
with gzip.open(filename) as f:
repo_commits = pipe(
map(json.loads, f),
filter(lambda ev: ev['type']=='PushEvent'),
reduceby(lambda ev: ev['repo']['name'],
lambda commits, e: commits+e['payload']['size'],
init=0)
)
return repo_commits
print_top_items(count_commits(path))
eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001
import glob
files = glob.glob('C:/ARGO/talks/split-apply-combine/data/github_archive/2015-01-*')
print len(files)
N = 24 #len(files) # 10
744
%%time
from toolz.curried import reduceby
from __builtin__ import map as pmap
repo_commits = \
pipe(pmap(count_commits, files[:N]),
lambda lst: reduce(lambda out, dct: out + dct.items(), lst, []),
reduceby(lambda t: t[0], lambda s,t: s+t[1], init=0)
)
print_top_items(repo_commits)
sakai-mirror/melete 77016 sakai-mirror/mneme 70128 sakai-mirror/ambrosia 18480 jsonn/pkgsrc 17629 devhd/rulus 9890 Wall time: 16.1 s
%%time
# Remember to start the ipcluster!
# ipcluster start -n 4
from IPython.parallel import Client
p = Client()[:]
pmap = p.map_sync
repo_commits = \
pipe(pmap(count_commits, files[:N]),
lambda lst: reduce(lambda out, dct: out + dct.items(), lst, []),
reduceby(lambda t: t[0], lambda s,t: s+t[1], init=0)
)
print_top_items(repo_commits)
sakai-mirror/melete 77016 sakai-mirror/mneme 70128 sakai-mirror/ambrosia 18480 jsonn/pkgsrc 17629 devhd/rulus 9890 Wall time: 5.4 s
Example 2 - using blaze (and pandas)¶
repo_commits = df[df.type_=='PushEvent'].groupby('repo').commits.sum()
repo_commits.sort(ascending=False)
repo_commits.head(5)
repo eberhardt/moodle 3335 sakai-mirror/melete 3209 jfaris/phonegap-facebook-plugin 3201 sakai-mirror/mneme 2922 wolfe-pack/wolfe 2001 Name: commits, dtype: float64
from blaze import Symbol, by
event = Symbol('event', 'var * {created_at: datetime, type_: string, user: string, repo: string, commits: int}')
push_events = event[event.type_=='PushEvent']
repo_commits = by(push_events.repo, commits=push_events.commits.sum())
top_repos = repo_commits.sort('commits', ascending=False).head(5)
from blaze import compute
print compute(top_repos, df)
repo commits 3906 eberhardt/moodle 3335 7476 sakai-mirror/melete 3209 5122 jfaris/phonegap-facebook-plugin 3201 7477 sakai-mirror/mneme 2922 8693 wolfe-pack/wolfe 2001
You can run the same computation on different backends!¶
from odo import odo
uri = 'sqlite:///data/github_archive.sqlite::event'
odo(df, uri)
Table('event', MetaData(bind=Engine(sqlite:///data/github_archive.sqlite)), Column('type_', Text(), table=<event>), Column('user', Text(), table=<event>), Column('repo', Text(), table=<event>), Column('commits', Float(precision=53), table=<event>), schema=None)
from blaze import Data
db = Data(uri)
compute(top_repos, db)
--------------------------------------------------------------------------- NotImplementedError Traceback (most recent call last) <ipython-input-28-e51bb3462e54> in <module>() 1 from blaze import Data 2 db = Data(uri) ----> 3 compute(top_repos, db) C:\Anaconda\lib\site-packages\multipledispatch\dispatcher.pyc in __call__(self, *args, **kwargs) 162 self._cache[types] = func 163 try: --> 164 return func(*args, **kwargs) 165 166 except MDNotImplementedError: C:\Anaconda\lib\site-packages\blaze\compute\core.pyc in compute(expr, o, **kwargs) 68 ts = set([x for x in expr._subterms() if isinstance(x, Symbol)]) 69 if len(ts) == 1: ---> 70 return compute(expr, {first(ts): o}, **kwargs) 71 else: 72 raise ValueError("Give compute dictionary input, got %s" % str(o)) C:\Anaconda\lib\site-packages\multipledispatch\dispatcher.pyc in __call__(self, *args, **kwargs) 162 self._cache[types] = func 163 try: --> 164 return func(*args, **kwargs) 165 166 except MDNotImplementedError: C:\Anaconda\lib\site-packages\blaze\compute\core.pyc in compute(expr, d, **kwargs) 470 d4 = d3 471 --> 472 result = top_then_bottom_then_top_again_etc(expr3, d4, **kwargs) 473 if post_compute_: 474 result = post_compute_(expr3, result, scope=d4) C:\Anaconda\lib\site-packages\blaze\compute\core.pyc in top_then_bottom_then_top_again_etc(expr, scope, **kwargs) 189 raise NotImplementedError("Don't know how to compute:\n" 190 "expr: %s\n" --> 191 "data: %s" % (expr3, scope4)) 192 else: 193 return top_then_bottom_then_top_again_etc(expr3, scope4, **kwargs) NotImplementedError: Don't know how to compute: expr: by(event[event.type_ == 'PushEvent'].repo, commits=sum(event[event.type_ == 'PushEvent'].commits)).sort('commits', ascending=False).head(5) data: {event: type_ user repo \ 0 CreateEvent birdage birdage/ooi-ui 1 PushEvent ArniR ArniR/ArniR.github.io 2 IssueCommentEvent CrossEye ramda/ramda 3 PushEvent yluoyu yluoyu/demo 4 IssueCommentEvent EJBQ prmr/JetUML 5 PushEvent ThibaudL cinemaouvert/OCT 6 WatchEvent ekmartin davecheney/golang-crosscompile 7 WatchEvent davidsanfal docker-library/official-images 8 PushEvent GET-TUDA-CHOPPA gamesbyangelina/whatareyoudoing 9 CreateEvent filipe-maia Lucas-Andrade/ProjectManager_FLM 10 PushEvent tomaszzielinski appsembler/launcher commits 0 NaN 1 1 2 NaN 3 1 4 NaN 5 1 6 NaN 7 NaN 8 1 9 NaN ...}
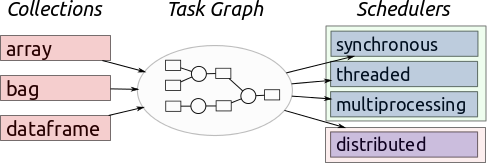
Dask and Castra¶
from castra import Castra
castra = Castra('data/github_archive.castra',
template=df, categories=categories)
castra.extend_sequence(map(to_df, files), freq='1h')
import dask.dataframe as dd
from dask.diagnostics import ProgressBar
pbar = ProgressBar()
pbar.register()
df = dd.from_castra('data/github_archive.castra')
df.head()
df.type.value_counts().nlargest(5).compute()
df[df.type=='PushEvent'].groupby('repo').commits.resample('h', how='count').compute()
So ...¶

... in Python!¶
Thank you!¶
We're hiring!¶
- I'm snth on github
- The Jupyter Notebook is on github: github.com/snth/split-apply-combine
- You can view the slides on nbviewer: slides