 # ### Google trends chart
#
# 
# ## Data Science
#
# According to https://en.wikipedia.org/wiki/Data_science:
#
# In November 1997, C.F. Jeff Wu gave the inaugural lecture entitled **"Statistics = Data Science?"**[5] for his appointment to the H. C. Carver Professorship at the University of Michigan.[6] In this lecture, he characterized statistical work as a trilogy of **data collection**, **data modeling and analysis**, and **decision making**. In his conclusion, he initiated the modern, non-computer science, usage of the term "data science" and advocated that statistics be renamed data science and statisticians data scientists.[5]
# ## The Github Archive Dataset
#
# https://www.githubarchive.org/
#
# Open-source developers all over the world are working on millions of projects: writing code & documentation, fixing & submitting bugs, and so forth. GitHub Archive is a project to record the public GitHub timeline, archive it, and make it easily accessible for further analysis.
#
# GitHub provides 20+ event types, which range from new commits and fork events, to opening new tickets, commenting, and adding members to a project. These events are aggregated into hourly archives, which you can access with any HTTP client:
#
# * gzipped json files
# * yyyy-mm-dd-HH.json.gz
# In[1]:
import os
import gzip
import ujson as json
directory = 'data/github_archive'
filename = '2015-01-29-16.json.gz'
path = os.path.join(directory, filename)
with gzip.open(path) as f:
events = [json.loads(line) for line in f]
#print json.dumps(events[0], indent=4)
#
# ### Google trends chart
#
# 
# ## Data Science
#
# According to https://en.wikipedia.org/wiki/Data_science:
#
# In November 1997, C.F. Jeff Wu gave the inaugural lecture entitled **"Statistics = Data Science?"**[5] for his appointment to the H. C. Carver Professorship at the University of Michigan.[6] In this lecture, he characterized statistical work as a trilogy of **data collection**, **data modeling and analysis**, and **decision making**. In his conclusion, he initiated the modern, non-computer science, usage of the term "data science" and advocated that statistics be renamed data science and statisticians data scientists.[5]
# ## The Github Archive Dataset
#
# https://www.githubarchive.org/
#
# Open-source developers all over the world are working on millions of projects: writing code & documentation, fixing & submitting bugs, and so forth. GitHub Archive is a project to record the public GitHub timeline, archive it, and make it easily accessible for further analysis.
#
# GitHub provides 20+ event types, which range from new commits and fork events, to opening new tickets, commenting, and adding members to a project. These events are aggregated into hourly archives, which you can access with any HTTP client:
#
# * gzipped json files
# * yyyy-mm-dd-HH.json.gz
# In[1]:
import os
import gzip
import ujson as json
directory = 'data/github_archive'
filename = '2015-01-29-16.json.gz'
path = os.path.join(directory, filename)
with gzip.open(path) as f:
events = [json.loads(line) for line in f]
#print json.dumps(events[0], indent=4)
#
# {
# "payload": {
# "master_branch": "master",
# "ref_type": "branch",
# "ref": "disable_dropdown",
# "description": "OOI UI Source Code",
# "pusher_type": "user"
# },
# "created_at": "2015-01-29T16:00:00Z",
# "actor": {
# "url": "https://api.github.com/users/birdage",
# "login": "birdage",
# "avatar_url": "https://avatars.githubusercontent.com/u/547228?",
# "id": 547228,
# "gravatar_id": ""
# },
# "id": "2545235518",
# "repo": {
# "url": "https://api.github.com/repos/birdage/ooi-ui",
# "id": 23796192,
# "name": "birdage/ooi-ui"
# },
# "type": "CreateEvent",
# "public": true
# }
#
# ### Typical Questions
#
# * How many Github repositories are created per hour/day/month?
# * To which repositories are the most commits are pushed per hour/day/month?
# * Which projects receive the most pull requests?
# * What are the most popular languages on Github?
# ## Example 1 - Number of Repositories Created
# In[2]:
new_repo_count = 0
for event in events:
new_repo_count += \
1 if event['type']=="CreateEvent" else 0
# In[3]:
print new_repo_count
# ## Example 2 - Number of commits pushed per repository
# In[4]:
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
# In[5]:
def print_top_items(dct, N=5):
sorted_items = sorted(
dct.iteritems(), key=lambda t: t[1], reverse=True)
for key, value in sorted_items[:N]:
print "{:40} {}".format(key, value)
print_top_items(repo_commits)
# # The Split-Apply-Combine Pattern
#
# ## Hadley Wickham  #
# [Hadley Wickham, the man who revolutionized R](http://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/)
#
# *If you don’t spend much of your time coding in the open-source statistical programming language R,
# his name is likely not familiar to you -- but the statistician Hadley Wickham is,
# in his own words, “nerd famous.” The kind of famous where people at statistics conferences
# line up for selfies, ask him for autographs, and are generally in awe of him.
# In[6]:
from IPython.display import HTML
HTML('')
#
#
# [Hadley Wickham, the man who revolutionized R](http://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/)
#
# *If you don’t spend much of your time coding in the open-source statistical programming language R,
# his name is likely not familiar to you -- but the statistician Hadley Wickham is,
# in his own words, “nerd famous.” The kind of famous where people at statistics conferences
# line up for selfies, ask him for autographs, and are generally in awe of him.
# In[6]:
from IPython.display import HTML
HTML('')
#  #
# * StackOverflow: [split-apply-combine tag](http://stackoverflow.com/tags/split-apply-combine/info)
# * Pandas documentation: [Group By: split-apply-combine](http://pandas.pydata.org/pandas-docs/stable/groupby.html)
# * PyTools documentation: [Split-apply-combine with groupby and reduceby](http://toolz.readthedocs.org/en/latest/streaming-analytics.html#split-apply-combine-with-groupby-and-reduceby)
# * Blaze documentation: [Split-Apply-Combine - Grouping](http://blaze.pydata.org/en/stable/split-apply-combine.html)
# * R plyr: [plyr: Tools for Splitting, Applying and Combining Data](https://cran.r-project.org/web/packages/plyr/index.html)
# * Julia documentation: [The Split-Apply-Combine Strategy](https://dataframesjl.readthedocs.org/en/latest/split_apply_combine.html)
# ## The Basic Pattern
#
# 1. **Split** the data by some **grouping variable**
# 2. **Apply** some function to each group **independently**
# 3. **Combine** the data into some output dataset
# * The **apply** step is usually one of
# * **aggregate**
# * **transform**
# * or **filter**
# ### Example 2 - examined
# In[7]:
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
# This
#
# * filters out only the "PushEvent"s
# * **splits** the dataset by *repository*
# * **sums** the commits for each group
# * **combines** the groups and their sums into a dictionary
# # Pandas - Python Data Analysis Library
#
#
#
# * StackOverflow: [split-apply-combine tag](http://stackoverflow.com/tags/split-apply-combine/info)
# * Pandas documentation: [Group By: split-apply-combine](http://pandas.pydata.org/pandas-docs/stable/groupby.html)
# * PyTools documentation: [Split-apply-combine with groupby and reduceby](http://toolz.readthedocs.org/en/latest/streaming-analytics.html#split-apply-combine-with-groupby-and-reduceby)
# * Blaze documentation: [Split-Apply-Combine - Grouping](http://blaze.pydata.org/en/stable/split-apply-combine.html)
# * R plyr: [plyr: Tools for Splitting, Applying and Combining Data](https://cran.r-project.org/web/packages/plyr/index.html)
# * Julia documentation: [The Split-Apply-Combine Strategy](https://dataframesjl.readthedocs.org/en/latest/split_apply_combine.html)
# ## The Basic Pattern
#
# 1. **Split** the data by some **grouping variable**
# 2. **Apply** some function to each group **independently**
# 3. **Combine** the data into some output dataset
# * The **apply** step is usually one of
# * **aggregate**
# * **transform**
# * or **filter**
# ### Example 2 - examined
# In[7]:
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
# This
#
# * filters out only the "PushEvent"s
# * **splits** the dataset by *repository*
# * **sums** the commits for each group
# * **combines** the groups and their sums into a dictionary
# # Pandas - Python Data Analysis Library
#
# ![]()
 # However ...
# ### Pandas currently only handles in-memory datasets!
# ### So not suitable for big data!
#
#
# However ...
# ### Pandas currently only handles in-memory datasets!
# ### So not suitable for big data!
#
#  # # MapReduce
#
# *"If you want to process Big Data, you need some MapReduce framework like one of the following"*
#
# # MapReduce
#
# *"If you want to process Big Data, you need some MapReduce framework like one of the following"*
#
# ![]() #
# ![]() #
#
 #
# The key to these frameworks is adopting a **functional** [programming] mindset. In Python this means, think **iterators**!
#
# See [The Structure and Interpretation of Computer Programs](https://mitpress.mit.edu/sicp/full-text/book/book.html)
# (the "*Wizard book*")
#
# * in particular [Chapter 2 Building Abstractions with Data](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-13.html#%_chap_2)
# * and [Section 2.2.3 Sequences as Conventional Interfaces](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-15.html#%_sec_2.2.3)
#
# Luckily, the Split-Apply-Combine pattern is well suited to this!
# ## Example 1 - revisited
# In[14]:
new_repo_count = 0
for event in events:
new_repo_count += \
1 if event['type']=="CreateEvent" else 0
print new_repo_count
# In[15]:
reduce(lambda x,y: x+y,
map(lambda ev: 1 if ev['type']=='CreateEvent' else 0,
events))
# Would prefer to write
#
# events | map(...) | reduce(...)
# ## Example 1 - pipelined
# In[16]:
def datapipe(data, *transforms):
for transform in transforms:
data = transform(data)
return data
datapipe(
events,
lambda events: map(lambda ev: 1 if ev['type']=='CreateEvent' else 0, events),
lambda counts: reduce(lambda x,y: x+y, counts)
)
# ## PyToolz
# ## Example 1 - pipeline using PyToolz
# In[17]:
from toolz.curried import pipe, map, reduce
pipe(events,
map(lambda ev: 1 if ev['type']=='CreateEvent' else 0),
reduce(lambda x,y: x+y)
)
# ## Example 2 - pipelined with PyToolz
# In[18]:
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
# In[19]:
from toolz.curried import filter, reduceby
pipe(events,
filter(lambda ev: ev['type']=='PushEvent'),
reduceby(lambda ev: ev['repo']['name'],
lambda commits, ev: commits+ev['payload']['size'],
init=0),
print_top_items
)
# ### The Point of Learning Patterns
#
# From Cosma Shalizi's [Statistical Computing](http://www.stat.cmu.edu/~cshalizi/statcomp/13/lectures/12/lecture-12.pdf) course:
#
# * Distinguish between **what** you want to do and **how you want to do it**.
# * Focusing on **what** brings clarity to intentions.
# * **How** also matters, but can obscure the high level problem.
#
# Learn the pattern, recognize the pattern, love the pattern!
#
# Re-use *good* solutions!
# ### Iteration Considered Unhelpful
#
# Could always do the same thing with `for` loops, but those are
#
# * *verbose* - lots of "how" obscures the "what"
# * painful/error-prone bookkeeping (indices, placeholders, ...)
# * clumsy - hard to parallelize
# ## Out-of-core processing - toolz example
# In[20]:
def count_commits(filename):
import gzip
import json
from toolz.curried import pipe, filter, reduceby
with gzip.open(filename) as f:
repo_commits = pipe(
map(json.loads, f),
filter(lambda ev: ev['type']=='PushEvent'),
reduceby(lambda ev: ev['repo']['name'],
lambda commits, e: commits+e['payload']['size'],
init=0)
)
return repo_commits
print_top_items(count_commits(path))
# In[21]:
import glob
files = glob.glob('C:/ARGO/talks/split-apply-combine/data/github_archive/2015-01-*')
print len(files)
N = 24 #len(files) # 10
# In[22]:
get_ipython().run_cell_magic('time', '', 'from toolz.curried import reduceby\nfrom __builtin__ import map as pmap\nrepo_commits = \\\n pipe(pmap(count_commits, files[:N]),\n lambda lst: reduce(lambda out, dct: out + dct.items(), lst, []),\n reduceby(lambda t: t[0], lambda s,t: s+t[1], init=0)\n )\nprint_top_items(repo_commits)\n')
# In[23]:
get_ipython().run_cell_magic('time', '', '# Remember to start the ipcluster!\n# ipcluster start -n 4\nfrom IPython.parallel import Client\np = Client()[:]\npmap = p.map_sync\nrepo_commits = \\\n pipe(pmap(count_commits, files[:N]),\n lambda lst: reduce(lambda out, dct: out + dct.items(), lst, []),\n reduceby(lambda t: t[0], lambda s,t: s+t[1], init=0)\n )\nprint_top_items(repo_commits)\n')
# # New tools
#
# ## [Blaze](http://blaze.pydata.org/en/latest/)
#
#
#
# The key to these frameworks is adopting a **functional** [programming] mindset. In Python this means, think **iterators**!
#
# See [The Structure and Interpretation of Computer Programs](https://mitpress.mit.edu/sicp/full-text/book/book.html)
# (the "*Wizard book*")
#
# * in particular [Chapter 2 Building Abstractions with Data](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-13.html#%_chap_2)
# * and [Section 2.2.3 Sequences as Conventional Interfaces](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-15.html#%_sec_2.2.3)
#
# Luckily, the Split-Apply-Combine pattern is well suited to this!
# ## Example 1 - revisited
# In[14]:
new_repo_count = 0
for event in events:
new_repo_count += \
1 if event['type']=="CreateEvent" else 0
print new_repo_count
# In[15]:
reduce(lambda x,y: x+y,
map(lambda ev: 1 if ev['type']=='CreateEvent' else 0,
events))
# Would prefer to write
#
# events | map(...) | reduce(...)
# ## Example 1 - pipelined
# In[16]:
def datapipe(data, *transforms):
for transform in transforms:
data = transform(data)
return data
datapipe(
events,
lambda events: map(lambda ev: 1 if ev['type']=='CreateEvent' else 0, events),
lambda counts: reduce(lambda x,y: x+y, counts)
)
# ## PyToolz
# ## Example 1 - pipeline using PyToolz
# In[17]:
from toolz.curried import pipe, map, reduce
pipe(events,
map(lambda ev: 1 if ev['type']=='CreateEvent' else 0),
reduce(lambda x,y: x+y)
)
# ## Example 2 - pipelined with PyToolz
# In[18]:
repo_commits = {}
for event in events:
if event['type']=="PushEvent":
repo = event['repo']['name']
commits = event['payload']['size']
repo_commits[repo] = \
repo_commits.get(repo, 0) + commits
print_top_items(repo_commits)
# In[19]:
from toolz.curried import filter, reduceby
pipe(events,
filter(lambda ev: ev['type']=='PushEvent'),
reduceby(lambda ev: ev['repo']['name'],
lambda commits, ev: commits+ev['payload']['size'],
init=0),
print_top_items
)
# ### The Point of Learning Patterns
#
# From Cosma Shalizi's [Statistical Computing](http://www.stat.cmu.edu/~cshalizi/statcomp/13/lectures/12/lecture-12.pdf) course:
#
# * Distinguish between **what** you want to do and **how you want to do it**.
# * Focusing on **what** brings clarity to intentions.
# * **How** also matters, but can obscure the high level problem.
#
# Learn the pattern, recognize the pattern, love the pattern!
#
# Re-use *good* solutions!
# ### Iteration Considered Unhelpful
#
# Could always do the same thing with `for` loops, but those are
#
# * *verbose* - lots of "how" obscures the "what"
# * painful/error-prone bookkeeping (indices, placeholders, ...)
# * clumsy - hard to parallelize
# ## Out-of-core processing - toolz example
# In[20]:
def count_commits(filename):
import gzip
import json
from toolz.curried import pipe, filter, reduceby
with gzip.open(filename) as f:
repo_commits = pipe(
map(json.loads, f),
filter(lambda ev: ev['type']=='PushEvent'),
reduceby(lambda ev: ev['repo']['name'],
lambda commits, e: commits+e['payload']['size'],
init=0)
)
return repo_commits
print_top_items(count_commits(path))
# In[21]:
import glob
files = glob.glob('C:/ARGO/talks/split-apply-combine/data/github_archive/2015-01-*')
print len(files)
N = 24 #len(files) # 10
# In[22]:
get_ipython().run_cell_magic('time', '', 'from toolz.curried import reduceby\nfrom __builtin__ import map as pmap\nrepo_commits = \\\n pipe(pmap(count_commits, files[:N]),\n lambda lst: reduce(lambda out, dct: out + dct.items(), lst, []),\n reduceby(lambda t: t[0], lambda s,t: s+t[1], init=0)\n )\nprint_top_items(repo_commits)\n')
# In[23]:
get_ipython().run_cell_magic('time', '', '# Remember to start the ipcluster!\n# ipcluster start -n 4\nfrom IPython.parallel import Client\np = Client()[:]\npmap = p.map_sync\nrepo_commits = \\\n pipe(pmap(count_commits, files[:N]),\n lambda lst: reduce(lambda out, dct: out + dct.items(), lst, []),\n reduceby(lambda t: t[0], lambda s,t: s+t[1], init=0)\n )\nprint_top_items(repo_commits)\n')
# # New tools
#
# ## [Blaze](http://blaze.pydata.org/en/latest/)
#
#  #
#
# ## [Dask](http://dask.pydata.org/en/latest/)
#
#
#
#
# ## [Dask](http://dask.pydata.org/en/latest/)
#
# 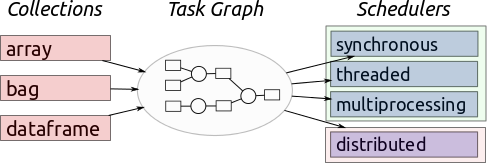 # ## Example 2 - using blaze (and pandas)
# In[24]:
repo_commits = df[df.type_=='PushEvent'].groupby('repo').commits.sum()
repo_commits.sort(ascending=False)
repo_commits.head(5)
# In[25]:
from blaze import Symbol, by
event = Symbol('event', 'var * {created_at: datetime, type_: string, user: string, repo: string, commits: int}')
push_events = event[event.type_=='PushEvent']
repo_commits = by(push_events.repo, commits=push_events.commits.sum())
top_repos = repo_commits.sort('commits', ascending=False).head(5)
# In[26]:
from blaze import compute
print compute(top_repos, df)
# ## You can run the same **computation** on different backends!
# In[27]:
from odo import odo
uri = 'sqlite:///data/github_archive.sqlite::event'
odo(df, uri)
# In[28]:
from blaze import Data
db = Data(uri)
compute(top_repos, db)
# In[ ]:
import os
if os.path.exists('data/github_archive.sqlite'):
os.remove('data/github_archive.sqlite')
# ## Dask and Castra
# In[ ]:
from castra import Castra
castra = Castra('data/github_archive.castra',
template=df, categories=categories)
castra.extend_sequence(map(to_df, files), freq='1h')
# In[ ]:
import dask.dataframe as dd
from dask.diagnostics import ProgressBar
pbar = ProgressBar()
pbar.register()
df = dd.from_castra('data/github_archive.castra')
df.head()
# In[ ]:
df.type.value_counts().nlargest(5).compute()
# In[ ]:
df[df.type=='PushEvent'].groupby('repo').commits.resample('h', how='count').compute()
# ## So ...
#
# ## Example 2 - using blaze (and pandas)
# In[24]:
repo_commits = df[df.type_=='PushEvent'].groupby('repo').commits.sum()
repo_commits.sort(ascending=False)
repo_commits.head(5)
# In[25]:
from blaze import Symbol, by
event = Symbol('event', 'var * {created_at: datetime, type_: string, user: string, repo: string, commits: int}')
push_events = event[event.type_=='PushEvent']
repo_commits = by(push_events.repo, commits=push_events.commits.sum())
top_repos = repo_commits.sort('commits', ascending=False).head(5)
# In[26]:
from blaze import compute
print compute(top_repos, df)
# ## You can run the same **computation** on different backends!
# In[27]:
from odo import odo
uri = 'sqlite:///data/github_archive.sqlite::event'
odo(df, uri)
# In[28]:
from blaze import Data
db = Data(uri)
compute(top_repos, db)
# In[ ]:
import os
if os.path.exists('data/github_archive.sqlite'):
os.remove('data/github_archive.sqlite')
# ## Dask and Castra
# In[ ]:
from castra import Castra
castra = Castra('data/github_archive.castra',
template=df, categories=categories)
castra.extend_sequence(map(to_df, files), freq='1h')
# In[ ]:
import dask.dataframe as dd
from dask.diagnostics import ProgressBar
pbar = ProgressBar()
pbar.register()
df = dd.from_castra('data/github_archive.castra')
df.head()
# In[ ]:
df.type.value_counts().nlargest(5).compute()
# In[ ]:
df[df.type=='PushEvent'].groupby('repo').commits.resample('h', how='count').compute()
# ## So ...
#  # # ... in Python!
# # Thank you!
#
# ## We're hiring!
#
# * I'm [snth](http://github.com/snth) on github
# * The Jupyter Notebook is on github: [github.com/snth/split-apply-combine](http://github.com/snth/split-apply-combine)
# * You can view the slides on nbviewer: [slides](http://nbviewer.ipython.org/format/slides/github/snth/split-apply-combine/blob/master/The%20Split-Apply-Combine%20Pattern%20in%20Data%20Science%20and%20Python.ipynb#/)
# # ... in Python!
# # Thank you!
#
# ## We're hiring!
#
# * I'm [snth](http://github.com/snth) on github
# * The Jupyter Notebook is on github: [github.com/snth/split-apply-combine](http://github.com/snth/split-apply-combine)
# * You can view the slides on nbviewer: [slides](http://nbviewer.ipython.org/format/slides/github/snth/split-apply-combine/blob/master/The%20Split-Apply-Combine%20Pattern%20in%20Data%20Science%20and%20Python.ipynb#/)