Introduction to Machine Learning with Python¶
Welcome to Zipfian Academy's Machine Learning workshop. Thank you for attending, we hope you enjoyed the lecture (we sure had fun presenting). This exercise will give you hands-on experience with the concepts covered, and will help solidify your understanding of the process of data science.
Getting Help¶
As always, feel free to email us about anything at all (questions, issues, concerns, feedback) at class@zipfianacademy.com. We would love to hear how you liked the class, whether the content was technical enough (or too technical), or any other topics you wish were covered.
Next Steps¶
We hope you have fun with this exercise! If you want to learn more or dive deeper into any of these subjects, we are always happy to discuss (and can talk for days about these subjects). And if you just can't get enough of this stuff (and want a completely immersive environment), you can apply for our intensive data science bootcamp starting January 20th.
Learning Python¶
This assignment assumes a basic familiarity with Python and is intended to teach you how to leverage it for data science. If you do not feel comfortable enough with Python (and programming in general) I recommend these (freely available) resources:
- Think Python
- MIT Open Courseware: A Gentle Introduction to Programming Using Python
- Learn Python the Hard Way
- Python Koans
Setup and Environment¶
This exercise is written in an IPython notebook and uses many of wonderful libraries from the scientific Python community. While you do not need IPython locally to complete the exercise (there are PDF and .ipynb versions of these instructions), I recommend setting it up on your computer if you plan to continue learning and playing with data. IPython notebooks not only provide an interface to interactively run (and debug) code in a web browser, but also to document your file as you go along. Below are the steps to setup a scientific Python environment on your computer to complete this (and all future class') assignment. If you have tips or suggestions to make this process easier, please reach out via email.
Version control and Environment Isolation¶
- Git: Distributed Version Control to keep track of changes and updates to files/data.
- virualenv: Python environment isolation to help manage dependencies with packages and versions.
- pythonbrew: Manage and install multiple versions of Python. Can be handy if you want to experiment with Python 3.x.
Scientific Python packages¶
- Enthought Python Distribution: A freely available packaged environment for scientific Python.
- Scipy Superpack: Only for Mac OSX, but a one line shell script that installs all the fundamental scientific computing packages.
- pandas: Data analysis and statistical library providing functionality in Python similar to R.
if you are on OSX, you may need to install Xcode (with command line utilities) or install gcc directly
Tutorial walking you through the installation of these tools, with tests to make sure it all works.
User knowledge modelling¶
In this tutorial we will be using the Grockit Question logs dataset to predict the probability of getting the next question correct. We will also cluster the data to find similar students. Once we know which students will perform worse than the others (classifier), we can recommend similar (clustering) students who performed well to study with.
Resources¶
- scikit-learn tutorial
- Kaggle: Getting started with Python for Data Science
- AMPlab: Machine Learning crash course (part 1)
- AMPlab: Machine Learning crash course (part 2)
- How Khan Academy is using Machine Learning to Assess Student Mastery
- Machine Learning with Python -- Logistic Regression
- Evaluation: Cross Validation
Outline¶
- Get the Data
- Preparation -- vectorization and feature preparation (engineering)
- Train -- fit/build model from known labeled data
- Test -- evaluate model with cross validation
- Predict -- run model on data with unknown labels
Goals¶
- Understand the various stages of the ML pipeline
- Obtain
- Prepare
- Train
- Test
- Predict
- Get experience building models with scikit-learn
- Decision Boundaries
- Cost Function
- Logistic Regression and the sigmoid function
- Cross Validation
- K-fold
- Hold out
- Optimization functions
- Classification vs. Regression
- Supervised vs. Unsupervised learning
- Kmeans clustering
- Distance functions (similarity)
import math, pdb, json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import dateutil as du
from sklearn import datasets, neighbors, linear_model,svm, naive_bayes, ensemble
#allows for matplotlib plots to be embedded directly inline\n",
%pylab inline
Populating the interactive namespace from numpy and matplotlib
Get the Data¶
Obtaining data can often be difficult and error prone. Luckily for us the fine folks at Kaggle have already parsed their data sets for their contestants. The format is not perfect for our analysis however, let us first start to explore it.
# You can get data files from our site (caution large files):
#
# training_subset (152M): https://s3.amazonaws.com/zipf_data/training_subset.csv
# training_full (529M): https://s3.amazonaws.com/zipf_data/training_full.csv
# change this file path to where you downloaded the data
df = pd.read_csv("data/grockit_all_data/training_subset.csv")
#full_data = pd.read_csv("data/grockit_all_data/training_full.csv")
df
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
<class 'pandas.core.frame.DataFrame'> Int64Index: 4763362 entries, 0 to 4763361 Columns: 5 entries, correct to answered_at dtypes: int64(4), object(1)
df.head(50)
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| correct | outcome | user_id | question_id | answered_at | |
|---|---|---|---|---|---|
| 0 | 0 | 2 | 85818 | 5560 | 2010-08-18 20:18:18 |
| 1 | 1 | 1 | 85818 | 4681 | 2010-08-18 20:20:34 |
| 2 | 1 | 1 | 85818 | 1529 | 2010-08-18 20:21:56 |
| 3 | 1 | 1 | 85818 | 2908 | 2010-08-18 20:23:05 |
| 4 | 1 | 1 | 85818 | 1773 | 2010-08-18 20:26:08 |
| 5 | 1 | 1 | 85818 | 3170 | 2010-08-18 20:26:43 |
| 6 | 1 | 1 | 85818 | 438 | 2010-08-18 20:28:22 |
| 7 | 1 | 1 | 85818 | 1909 | 2010-08-18 20:32:19 |
| 8 | 1 | 1 | 85818 | 111 | 2010-08-18 20:32:45 |
| 9 | 1 | 1 | 85818 | 3125 | 2010-08-18 20:34:23 |
| 10 | 0 | 4 | 85818 | 1338 | NaN |
| 11 | 1 | 1 | 85818 | 1121 | 2010-08-20 14:16:53 |
| 12 | 1 | 1 | 85818 | 3177 | 2010-08-20 14:17:53 |
| 13 | 1 | 1 | 85818 | 2277 | 2010-08-20 14:22:53 |
| 14 | 0 | 4 | 85818 | 2946 | NaN |
| 15 | 1 | 1 | 85818 | 895 | 2010-08-20 14:28:42 |
| 16 | 1 | 1 | 85818 | 2131 | 2010-08-20 14:29:52 |
| 17 | 0 | 4 | 85818 | 4884 | NaN |
| 18 | 0 | 4 | 85818 | 5085 | NaN |
| 19 | 1 | 1 | 85818 | 1719 | 2010-08-20 14:38:21 |
| 20 | 1 | 1 | 85818 | 5181 | 2010-08-20 14:39:20 |
| 21 | 0 | 4 | 85818 | 874 | NaN |
| 22 | 0 | 4 | 85818 | 2873 | NaN |
| 23 | 1 | 1 | 85818 | 1148 | 2010-08-20 14:45:53 |
| 24 | 0 | 4 | 85818 | 3878 | NaN |
| 25 | 0 | 2 | 85818 | 5231 | 2010-08-20 15:04:36 |
| 26 | 0 | 2 | 85818 | 3655 | 2010-08-20 15:08:41 |
| 27 | 1 | 1 | 85818 | 5973 | 2010-08-20 15:10:07 |
| 28 | 1 | 1 | 85818 | 1416 | 2010-08-20 15:11:18 |
| 29 | 0 | 2 | 85818 | 3797 | 2010-08-20 15:12:36 |
| 30 | 1 | 1 | 85818 | 3811 | 2010-08-20 15:14:10 |
| 31 | 0 | 2 | 85818 | 3989 | 2010-08-20 15:18:08 |
| 32 | 0 | 4 | 85818 | 1901 | NaN |
| 33 | 0 | 4 | 85818 | 1641 | NaN |
| 34 | 0 | 2 | 85818 | 1228 | 2010-08-20 15:32:54 |
| 35 | 0 | 2 | 85818 | 5995 | 2010-08-20 15:35:20 |
| 36 | 0 | 4 | 85818 | 4218 | NaN |
| 37 | 0 | 4 | 85818 | 4061 | NaN |
| 38 | 1 | 1 | 85818 | 4852 | 2010-08-20 17:40:03 |
| 39 | 1 | 1 | 85818 | 531 | 2010-08-20 17:40:49 |
| 40 | 1 | 1 | 85818 | 3020 | 2010-08-20 17:43:08 |
| 41 | 1 | 1 | 85818 | 1905 | 2010-08-20 17:45:08 |
| 42 | 1 | 1 | 85818 | 3506 | 2010-08-20 17:47:17 |
| 43 | 0 | 4 | 85818 | 5 | NaN |
| 44 | 0 | 4 | 85818 | 2355 | NaN |
| 45 | 1 | 1 | 85818 | 5576 | 2010-08-20 20:07:38 |
| 46 | 0 | 2 | 85818 | 3036 | 2010-08-20 20:12:02 |
| 47 | 1 | 1 | 85818 | 1722 | 2010-08-20 20:14:12 |
| 48 | 0 | 2 | 85818 | 4827 | 2010-08-20 20:16:25 |
| 49 | 1 | 1 | 85818 | 1288 | 2010-08-20 20:18:28 |
print "There are %d students in the dataset" % df['user_id'].nunique()
There are 179106 students in the dataset
counts = df['user_id'].value_counts()
counts.head(1000)
133472 10104 139564 7245 169858 7146 31228 7020 43889 6759 94877 6665 123742 6652 95423 6256 86139 5931 27429 5867 23819 5858 119351 5835 96046 5785 169795 5645 132295 5209 ... 52157 768 53168 766 82849 765 60665 765 152331 764 18097 764 81758 764 118232 764 63684 762 156016 762 145116 762 12944 762 30239 762 155377 761 177369 760 Length: 1000, dtype: int64
counts.mean()
26.595211774033253
# remove outliers
filtered = df[df['user_id'] != 133472]
print "There %d rows in our dataset. Each row corresponds to a user answering a question." % len(filtered)
There 4753258 rows in our dataset. Each row corresponds to a user answering a question.
Prepare¶
Now that we have our data loaded (thankfully it was in a nice delimited format) we can begin to explore it. In the data set, each row corresponds to a single student answering a single question. In order to begin to predict whether a user will get their next question right, we need t otransform this data set. Rather than each instance being a single answer, we want each row to correspond to a single user (and every question they have answered).
Vectorization¶
Feature selection/preparation/engineering is something of a black art. There are no hard set rules or approaches, and because of this proper features can be difficult to choose. And since the performance of the algorthm depends upon the knowledge representation of the feature space, it is often the most important part of the analysis. Using intuition, it makes some sense that each feature vector represents a user and all their results on all the questions. We can even make this more rich by adding things like: total questions correct, longest streak, moving average, etc.
filtered['question_id'].nunique()
6045
Sparse Data¶
Our data set is quite sparse: not every student answers every question. On average a student answers 26 question. There are a total of 6045 questions. In the interest of performance and accuracy, we will try to make our feature matrix a little more dense.
# Find top 500 most answered questions
top1000 = filtered['question_id'].value_counts().head(1000)
top1000
4059 13904 1272 12963 1928 10273 2179 10037 4952 10012 4444 9751 1883 9581 5252 9290 2775 8933 5706 8882 1856 8712 5092 8597 4103 8099 2984 7764 1356 7672 ... 6014 1294 2750 1293 2994 1293 2879 1292 2196 1292 918 1292 2426 1292 4329 1292 293 1291 2843 1291 5302 1291 192 1291 1210 1290 5573 1290 3584 1289 Length: 1000, dtype: int64
# select these from our data set
top_questions = filtered[filtered['question_id'].isin(top1000.index)]
top_questions['question_id'].nunique()
1000
# Select the top 10,000 users who answered the top 500 questions
users15000 = top_questions['user_id'].value_counts().head(15000)
top_users = top_questions[top_questions['user_id'].isin(users15000.index)]
top_users.to_csv("users_sample.csv")
top_questions.to_csv("questions_sample.csv")
users15000
59511 2458 86139 2427 20440 2308 29080 2239 119351 2234 169858 2133 78410 2096 94877 2011 123742 1998 27429 1849 43889 1762 1914 1717 96046 1676 62044 1670 47816 1644 ... 39815 22 133264 22 151401 22 104167 22 153522 22 77394 22 121615 22 61659 22 150720 22 81517 22 91938 22 78938 22 170964 22 97852 22 59498 22 Length: 15000, dtype: int64
top_users.head()
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| correct | outcome | user_id | question_id | answered_at | |
|---|---|---|---|---|---|
| 0 | 0 | 2 | 85818 | 5560 | 2010-08-18 20:18:18 |
| 1 | 1 | 1 | 85818 | 4681 | 2010-08-18 20:20:34 |
| 2 | 1 | 1 | 85818 | 1529 | 2010-08-18 20:21:56 |
| 3 | 1 | 1 | 85818 | 2908 | 2010-08-18 20:23:05 |
| 4 | 1 | 1 | 85818 | 1773 | 2010-08-18 20:26:08 |
Now we build up each user vector¶
# get rid of duplicate user answers for the same question
no_dups = top_users.drop_duplicates(cols=['user_id', 'question_id'], take_last=True)
# pivot the matrix -- each row becomes a user, and each column an index
pivot = no_dups.pivot(index='user_id', columns='question_id', values='outcome')
pivot.iloc[:20, 20:40]
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| question_id | 111 | 121 | 134 | 137 | 159 | 169 | 180 | 183 | 186 | 192 | 196 | 197 | 203 | 204 | 205 | 206 | 210 | 222 | 225 | 230 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||||
| 5 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 53 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 55 | NaN | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 77 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 86 | NaN | NaN | NaN | NaN | 2 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1 | NaN | NaN | NaN | NaN | NaN |
| 97 | 1 | 1 | NaN | 1 | 1 | 1 | 1 | NaN | NaN | 2 | NaN | NaN | NaN | NaN | 1 | NaN | NaN | NaN | NaN | 1 |
| 102 | NaN | NaN | 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 103 | NaN | NaN | 1 | NaN | NaN | NaN | NaN | NaN | 2 | NaN | 2 | NaN | NaN | 2 | NaN | 2 | NaN | 1 | NaN | NaN |
| 142 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2 | NaN | NaN | NaN | NaN | 1 | NaN |
| 168 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 183 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 185 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2 | NaN | NaN | NaN | NaN | NaN | 1 | NaN | NaN |
| 242 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2 |
| 275 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 302 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 313 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 334 | NaN | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 366 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 372 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2 | NaN | NaN | NaN | NaN | NaN |
# convert unanswered questions to 0
pivot_fill = pivot.fillna(0)
pivot_fill.iloc[:20, 20:40]
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| question_id | 111 | 121 | 134 | 137 | 159 | 169 | 180 | 183 | 186 | 192 | 196 | 197 | 203 | 204 | 205 | 206 | 210 | 222 | 225 | 230 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||||
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 53 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 55 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 77 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 86 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 97 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 102 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 103 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 2 | 0 | 2 | 0 | 1 | 0 | 0 |
| 142 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 168 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 183 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 185 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 242 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| 275 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 302 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 313 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 334 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 366 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 372 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 |
# transform unanwered, skipped, not finished => incorrect
mapping = { 1: 1, 0: 0, 2: 2, 3: 2, 4: 2 }
for name in pivot_fill.columns:
pivot_fill[name] = pivot_fill[name].map(mapping)
pivot_fill.iloc[:20, 20:40]
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| question_id | 111 | 121 | 134 | 137 | 159 | 169 | 180 | 183 | 186 | 192 | 196 | 197 | 203 | 204 | 205 | 206 | 210 | 222 | 225 | 230 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||||
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 53 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 55 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 77 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 86 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 97 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 102 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 103 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 2 | 0 | 2 | 0 | 1 | 0 | 0 |
| 142 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 168 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 183 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 185 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 242 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| 275 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 302 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 313 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 334 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 366 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 372 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 |
col_names = pivot_fill.columns
test_columns = list(col_names)
test_columns.remove(1272)
print len(col_names)
print len(test_columns)
1000 999
Train¶
Now that we have properly vectorized our data set and prepared our features, we can begin to train our model. Training a model is very similar to fitting a (statistical) distribution, except that it iterative updates itself based on the data it sees (similar to a Bayesian prior). We will not be going into too much detail in this exercise about how the logistic regression function works under the hood, but the basics are as follows:
We would like a function that we can give a new (un-labeled) vector of features, and our function correcty returns the predicted label. This function is the sigmoid:
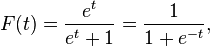
And t in this case is a linear function of the exploratory variable (our features). This t forms a separating hyperplane (more on this later) that creates a decision boundary between the classified points. Our algorithm will try to ___learn___ each of the weights (beta0, beta1, etc.) in this function:
___h(x)___ = 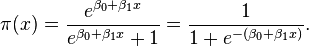
We can treat these weights as a vector, in order to determine the optimal weights we can use the ideal of a cost function. A cost function determines what optimal weights are: it represents the error in the classification. By minimizing the cost function, we can minimize the error in our predictions. The cost function for logistic regression:

Optimization¶
In order to calculate the ideal weights (theta), we need to use an optimization technique. In this situation (since our cost function is convex), gradient descent is our best choice. This amounts to finding the global minimum (over theta) of the cost function. Gradient descent works much like a tired climber might descending a mountain: at each step figure out which direction the steepest decline is in and continue in that direction.

# shuffle data to randomize cross validation split
pivot_fill = pivot_fill.reindex(np.random.permutation(pivot_fill.index))
# split data into features and target variable
train_x = pivot_fill[test_columns]
train_y = pivot_fill[1272]
# map unanswered to incorrect in our target variable
train_y = train_y.map({0: 2, 2:2, 1:1})
# Create cross validation splits -- 90% train ;; 10% test
n_samples = len(pivot_fill)
X_train = train_x.as_matrix()[:.9 * n_samples]
y_train = np.array(train_y[:.9 * n_samples])
X_test = train_x.as_matrix()[.9 * n_samples:]
y_test = np.array(train_y[.9 * n_samples:])
-c:4: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/series.py:711: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future return Series(self.values[indexer], index=self.index[indexer], /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/index.py:341: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future result = arr_idx[key] -c:6: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/series.py:711: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future return Series(self.values[indexer], index=self.index[indexer], /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/index.py:341: DeprecationWarning: using a non-integer number instead of an integer will result in an error in the future result = arr_idx[key]
# create classifier objects with parameters
logistic = linear_model.LogisticRegression(C=1e5, penalty="l1")
knn = neighbors.KNeighborsClassifier()
sgd = linear_model.SGDClassifier(loss="log", penalty="l1")
bayes = naive_bayes.BernoulliNB()
svmm = svm.SVC(kernel='rbf')
rf = ensemble.RandomForestClassifier()
%%time
# train Stocastic Gradient Descent on training set
sgd_model = sgd.fit(X_train, y_train)
CPU times: user 1.1 s, sys: 66.5 ms, total: 1.16 s Wall time: 1.18 s
%%time
# train Stocastic Gradient Descent on training set
rf_model = rf.fit(X_train, y_train)
CPU times: user 4.4 s, sys: 46.2 ms, total: 4.45 s Wall time: 4.47 s
%%time
# train Stocastic Gradient Descent on training set
svm_model = svmm.fit(X_train, y_train)
CPU times: user 1min 9s, sys: 581 ms, total: 1min 10s Wall time: 1min 11s
%%time
# train Stocastic Gradient Descent on training set
bayes_model = bayes.fit(X_train, y_train)
CPU times: user 555 ms, sys: 123 ms, total: 678 ms Wall time: 649 ms
%%time
# train k-Nearest Neighbors on training set
knn_model = knn.fit(X_train, y_train)
CPU times: user 3.36 s, sys: 68.9 ms, total: 3.43 s Wall time: 3.51 s
Validate¶
Now that we have trained our models on our data, we need to check each model's accuracy. In practice you do this for many different parameters to each algorithm and also compare many algorithms to each other. In cross validation, we have the notion of a hold out set. These data we already know the labels for, but we pretend that we do not and see what our model predicts.
Remember: NEVER TEST ON YOUR TRAINING DATA¶
%%time
print('sgd score: %f' % sgd_model.score(X_test, y_test))
sgd score: 0.892667 CPU times: user 10.5 ms, sys: 9.6 ms, total: 20.1 ms Wall time: 16.9 ms
%%time
print('Random Forest score: %f' % rf_model.score(X_test, y_test))
Random Forest score: 0.923333 CPU times: user 14 ms, sys: 8.93 ms, total: 23 ms Wall time: 55 ms
%%time
print('bayes score: %f' % bayes_model.score(X_test, y_test))
bayes score: 0.748667 CPU times: user 54.5 ms, sys: 22.1 ms, total: 76.6 ms Wall time: 72.9 ms
%%time
print('svm score: %f' % svm_model.score(X_test, y_test))
svm score: 0.931333 CPU times: user 6.49 s, sys: 24.9 ms, total: 6.51 s Wall time: 6.54 s
%%time
print('KNN score: %f' % knn_model.score(X_test, y_test))
KNN score: 0.917333 CPU times: user 45.1 s, sys: 157 ms, total: 45.3 s Wall time: 45.4 s
%%time
print('LogisticRegression score: %f'
% logistic.fit(X_train, y_train).score(X_test, y_test))
LogisticRegression score: 0.896667 CPU times: user 1.63 s, sys: 40.5 ms, total: 1.67 s Wall time: 1.68 s
Clustering¶
We will be using the UCI Knowledge modelling dataset to cluster the users based on performance. We will use k=4 clusters to correspond to the 4 classes of UNS (knowledge level) and compare the results of the clustering to the ground truth observation (data set contains true labels)
Get the Data¶
#load the dataset
user_knowledge = pd.read_table('data/uci_students_train.tsv', sep='\t')
knowledge_test = pd.read_table('data/uci_students_test.tsv', sep='\t')
Attribute Information:¶
- STG (The degree of study time for goal object materails), (input value)
- SCG (The degree of repetition number of user for goal object materails) (input value)
- STR (The degree of study time of user for related objects with goal object) (input value)
- LPR (The exam performance of user for related objects with goal object) (input value)
- PEG (The exam performance of user for goal objects) (input value)
- UNS (The knowledge level of user) (target value)
Classes -- UNS¶
- Very Low: 50
- Low: 129
- Middle: 122
- High 130
user_knowledge
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
<class 'pandas.core.frame.DataFrame'> Int64Index: 258 entries, 0 to 257 Data columns (total 7 columns): STG 258 non-null values SCG 258 non-null values STR 258 non-null values LPR 258 non-null values PEG 258 non-null values UNS 258 non-null values Unnamed: 6 0 non-null values dtypes: float64(6), object(1)
user_knowledge.head()
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| STG | SCG | STR | LPR | PEG | UNS | Unnamed: 6 | |
|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | very_low | NaN |
| 1 | 0.08 | 0.08 | 0.10 | 0.24 | 0.90 | High | NaN |
| 2 | 0.06 | 0.06 | 0.05 | 0.25 | 0.33 | Low | NaN |
| 3 | 0.10 | 0.10 | 0.15 | 0.65 | 0.30 | Middle | NaN |
| 4 | 0.08 | 0.08 | 0.08 | 0.98 | 0.24 | Low | NaN |
# get rid of extraneous column
user_knowledge = user_knowledge.iloc[:,:-1]
user_knowledge.head()
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| STG | SCG | STR | LPR | PEG | UNS | |
|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | very_low |
| 1 | 0.08 | 0.08 | 0.10 | 0.24 | 0.90 | High |
| 2 | 0.06 | 0.06 | 0.05 | 0.25 | 0.33 | Low |
| 3 | 0.10 | 0.10 | 0.15 | 0.65 | 0.30 | Middle |
| 4 | 0.08 | 0.08 | 0.08 | 0.98 | 0.24 | Low |
# remove any spaces in column titles
user_knowledge.columns = user_knowledge.columns.map(str.strip)
# create a separate feature vector and label vector
# all feature are an appropriate scale, but in some cases
# normalization/feature scaling may be necessary
student_train_frame = user_knowledge.iloc[:,:-1]
student_label_frame = user_knowledge.iloc[:,-1:]
student_train_frame.head()
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning) /Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/pandas/core/config.py:570: DeprecationWarning: height has been deprecated. warnings.warn(d.msg, DeprecationWarning)
| STG | SCG | STR | LPR | PEG | |
|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1 | 0.08 | 0.08 | 0.10 | 0.24 | 0.90 |
| 2 | 0.06 | 0.06 | 0.05 | 0.25 | 0.33 |
| 3 | 0.10 | 0.10 | 0.15 | 0.65 | 0.30 |
| 4 | 0.08 | 0.08 | 0.08 | 0.98 | 0.24 |
# convert to Numpy array for sklearn
student_train = student_train_frame.as_matrix()
student_label = student_label_frame.as_matrix()
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(student_train)
KMeans(copy_x=True, init='k-means++', max_iter=300, n_clusters=4, n_init=10,
n_jobs=1, precompute_distances=True, random_state=None, tol=0.0001,
verbose=0)
student_label
258 258
y_hat = kmeans.labels_
y_hat
array([1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 2, 0, 0, 2, 2, 2, 0, 1, 1, 1, 0, 1, 1,
0, 0, 2, 0, 0, 0, 2, 2, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 2, 2, 0, 0, 2,
2, 2, 2, 1, 1, 1, 0, 2, 2, 0, 0, 2, 2, 0, 0, 2, 2, 0, 0, 1, 1, 1, 1,
1, 1, 1, 0, 2, 2, 0, 0, 2, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 2, 2, 0,
0, 2, 2, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 2, 2, 2, 0, 2, 2, 2, 3, 1, 1,
0, 0, 3, 2, 2, 0, 0, 2, 2, 2, 3, 2, 2, 0, 0, 1, 1, 0, 3, 1, 1, 0, 0,
2, 1, 0, 0, 2, 2, 2, 3, 1, 0, 0, 3, 1, 1, 0, 0, 2, 2, 2, 3, 2, 2, 0,
0, 1, 1, 0, 1, 1, 2, 0, 1, 2, 2, 2, 0, 2, 2, 0, 3, 1, 1, 0, 3, 2, 1,
0, 0, 2, 2, 0, 3, 2, 2, 2, 3, 1, 1, 0, 0, 1, 0, 0, 3, 1, 2, 3, 0, 2,
2, 0, 3, 1, 1, 3, 3, 2, 1, 0, 3, 2, 2, 0, 3, 2, 2, 0, 3, 1, 1, 3, 3,
1, 1, 0, 3, 2, 2, 0, 2, 2, 2, 0, 3, 1, 1, 0, 3, 2, 1, 3, 3, 2, 2, 0,
3, 2, 2, 0, 3], dtype=int32)
pl = plt.scatter(student_train[:,0], student_train[:, 1], c=y_hat)

import itertools as iter
list(iter.combinations([0,1,2,3,4], 2))
[(0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
col = user_knowledge.columns
col
Index([u'STG', u'SCG', u'STR', u'LPR', u'PEG', u'UNS'], dtype=object)
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
ground_truth = le.fit_transform(student_label)
/Users/JayOheN/.virtualenvs/dataweek/lib/python2.7/site-packages/sklearn/preprocessing/label.py:99: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True)
def plot_kmeans(title="kmeans", fignum = 1, size=(10, 6), columns=(0,1), labels=None, axes=["x_axis", "y_axis"]):
fig = plt.figure(fignum, figsize=size)
plt.scatter(student_train[:,columns[0]], student_train[:, columns[1]], c=labels, label=labels)
plt.title(title)
plt.xlabel(axes[columns[0]])
plt.ylabel(axes[columns[1]])
return fignum + 1
f = 1
for x,y in iter.combinations([0,1,2,3,4], 2):
# plot kmeans clustering
f = plot_kmeans(fignum=f, columns=(x,y), labels=y_hat, axes=col)
# plot true labels
f = plot_kmeans(title="Ground Truth", fignum=f, columns=(x,y), labels=ground_truth, axes=col)




















# Example from scikit-learn site: http://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_iris.html
import numpy as np
import pylab as pl
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from sklearn import datasets
np.random.seed(5)
centers = [[1, 1], [-1, -1], [1, -1]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = {'k_means_iris_3': KMeans(n_clusters=3),
'k_means_iris_8': KMeans(n_clusters=8),
'k_means_iris_bad_init': KMeans(n_clusters=3, n_init=1,
init='random')}
fignum = 1
for name, est in estimators.iteritems():
fig = pl.figure(fignum, figsize=(10, 6))
pl.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
pl.cla()
est.fit(X)
labels = est.labels_
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(np.float))
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
fignum = fignum + 1
# Plot the ground truth
fig = pl.figure(fignum, figsize=(10, 6))
pl.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
pl.cla()
for name, label in [('Setosa', 0),
('Versicolour', 1),
('Virginica', 2)]:
ax.text3D(X[y == label, 3].mean(),
X[y == label, 0].mean() + 1.5,
X[y == label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
# Reorder the labels to have colors matching the cluster results
y = np.choose(y, [1, 2, 0]).astype(np.float)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
pl.show()




Euclidean Distance¶
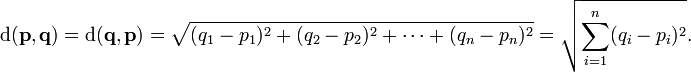
# Euclidean distance function
def euclidean(vec1, vec2):
diff = vec1 - vec2
total_sq = np.sum(diff ** 2)
return math.sqrt(total_sq)
Glossary¶
- expert system: A classifier that performs the same task as an 'expert', i.e. identifying spam emails, or birds, or documents.
- feature: An attribute/field of the data point. Think column in a database. Whether or not a word of our lexiccon is present in an article.
- instance: One data point, a collection or vector of features. Think row in a database. A whole article and the words it contains.
- class: The label we are trying to classify/predict for an instance. The whether a student got a question right.
- training set: A collection of pre-labeled instances (we know which class they belong to) used to build the model. A collection of student questions that we know whether they got correct.
- training example: One instance of the training set.
- target variable: The feature we want to predict for all of our unlabeled instances. The class is the value of the target variable. The target variable is the question outcome (correct/not correct). (careful when calling the target variable a feature, some people may disagree on this)
- test set: A collection of pre-labeled instances used to evaluate our predictor. We pretend we do not know the target variable and run these instances through the predictor comparing the actual class with what the model assigned.
- nominal value: A discrete string or number. Finite domain of possible values. i.e. NYT sections
- continuous value: A continuous value ;) most defeinitely a number. Real or integer. Infinite domain of possible values. i.e. Temperature (since it can be arbitrarily precise)
- model: Resulting data structure of training the algorithm. We can think of this as a function. Takes as input an instance and outputs a class for the target variable
- knowledge representation: data structure encoding information on what algorithm learned. Can be a set of rules, probabilities, a tree, or a function. Sometimes knowledge representation is more important than the model or prediction itself, i.e. Decision tree nodes/splits.