Huffman codes¶
Unicode and ASCII code map characters to bits, but all characters (letters, numbers, punctuation marks) map to the same number of bits (7 for ASCII).
The Huffman code is a variable length code. The code length (in bits) for each datum (data point) is proportional to its frequency in the data. This is effectively a loss-less compression. The frequencies are calculated from a corpus - a big representative data set.
To preserve the reversability of the code (one-to-one) we use prefix free codes - no code is a prefix of another code, i.e. if 0110 is a code, then there is no other code theat begins with 0110.
We start with a simple code for creating a histogram of the data:
def char_count(text):
histogram = {}
for ch in text:
histogram[ch] = histogram.get(ch, 0) + 1
return histogram
letter_count = char_count("live and let live")
letter_count
{' ': 3, 'a': 1, 'd': 1, 'e': 3, 'i': 2, 'l': 3, 'n': 1, 't': 1, 'v': 2}
Next we need to build the Huffman tree.
def by_value(tup):
return tup[1]
def build_huffman_tree(letter_count):
""" recieves dictionary with char:count entries
generates a list of letters representing the binary Huffman encoding tree"""
queue = list(letter_count.items())
while len(queue) >= 2:
queue.sort(key=by_value) # sort by the count
# combine two least frequent elements
elem1, freq1 = queue.pop(0)
elem2, freq2 = queue.pop(0)
elems = (elem1, elem2)
freqs = freq1 + freq2
queue.append((elems,freqs))
return queue[0][0]
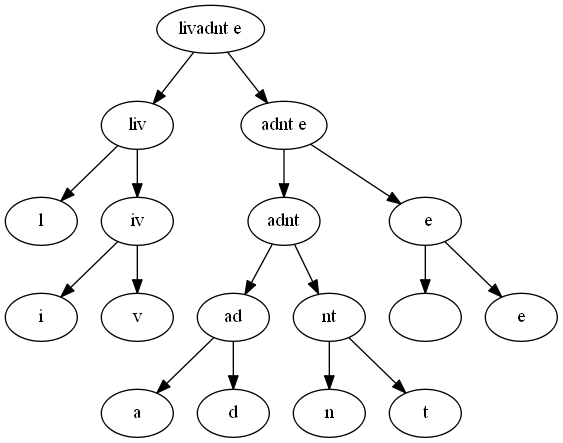
tree = build_huffman_tree(letter_count)
tree
(('l', ('i', 'v')), ((('a', 'd'), ('n', 't')), (' ', 'e')))
def build_codebook(huff_tree, prefix=''):
""" receives a Huffman tree with embedded encoding and a prefix of encodings.
returns a dictionary where characters are keys and associated binary strings are values."""
if isinstance(huff_tree, str): # a leaf
return {huff_tree: prefix}
else:
left, right = huff_tree
codebook = {}
codebook.update( build_codebook(left, prefix + '0'))
codebook.update( build_codebook(right, prefix + '1'))
return codebook
codebook = build_codebook(tree)
for ch,freq in sorted(letter_count.items(), key=by_value, reverse=True):
print(ch, freq, codebook[ch])
3 110 e 3 111 l 3 00 i 2 010 v 2 011 a 1 1000 d 1 1001 n 1 1010 t 1 1011
def compress(text, codebook):
''' compress text using codebook dictionary '''
return ''.join(codebook[ch] for ch in text if ord(ch) <= 128)
ch,ord(ch),'{:08b}'.format(ord(ch))
('t', 116, '01110100')
bits_ascii = ''.join(['{:07b}'.format(ord(ch)) for ch in "live and let live" if ord(ch) <= 128])
huff_bits = compress("live and let live", codebook)
print(len(bits_ascii),bits_ascii)
print(len(huff_bits),huff_bits)
119 11011001101001111011011001010100000110000111011101100100010000011011001100101111010001000001101100110100111101101100101 52 0001001111111010001010100111000111101111000010011111
def build_decoding_dict(codebook):
"""build the "reverse" of encoding dictionary"""
return {v:k for k,v in codebook.items()}
decodebook = build_decoding_dict(codebook)
decodebook
{'00': 'l',
'010': 'i',
'011': 'v',
'1000': 'a',
'1001': 'd',
'1010': 'n',
'1011': 't',
'110': ' ',
'111': 'e'}
def decompress(bits, decodebook):
prefix = ''
result = []
for bit in bits:
prefix += bit
if prefix not in decodebook:
continue
result.append(decodebook[prefix])
prefix = ''
assert prefix == '' # must finish last codeword
return ''.join(result) # converts list of chars to a string
decompress(huff_bits, decodebook)
'live and let live'
Examples¶
def huffman_code(corpus):
counts = char_count(corpus)
tree = build_huffman_tree(counts)
return build_codebook(tree)
There is only one way to create the codebook for this corpus:
huffman_code('aaabbc')
{'a': '0', 'b': '11', 'c': '10'}
There are different ways to create a codebook for this corpus - b and c are interchangeable:
huffman_code('aaabbcc')
{'a': '0', 'b': '11', 'c': '10'}
Here the frequency of all characters is equal, so the code is actually a fixed length code - most characters
codebook = huffman_code('qwertuioplkjhgfdsazxcvbnm')
codebook
{'a': '01110',
'b': '10000',
'c': '01111',
'd': '10010',
'e': '10001',
'f': '10100',
'g': '10011',
'h': '10110',
'i': '10101',
'j': '11000',
'k': '10111',
'l': '11010',
'm': '11001',
'n': '11100',
'o': '11011',
'p': '11110',
'q': '11101',
'r': '0000',
's': '11111',
't': '0010',
'u': '0001',
'v': '0100',
'w': '0011',
'x': '0101',
'z': '0110'}
Average length of 4.72, most codes are of length 5:
mean([len(v) for v in codebook.values()])
4.7199999999999998
In the next corpus every letter appears a different number of times:
corpus = ''.join([ch*(i+1) for i,ch in enumerate('qwertuioplkjhgfdsazxcvbnm') ])
corpus
'qwweeerrrrtttttuuuuuuiiiiiiioooooooopppppppppllllllllllkkkkkkkkkkkjjjjjjjjjjjjhhhhhhhhhhhhhggggggggggggggfffffffffffffffddddddddddddddddsssssssssssssssssaaaaaaaaaaaaaaaaaazzzzzzzzzzzzzzzzzzzxxxxxxxxxxxxxxxxxxxxcccccccccccccccccccccvvvvvvvvvvvvvvvvvvvvvvbbbbbbbbbbbbbbbbbbbbbbbnnnnnnnnnnnnnnnnnnnnnnnnmmmmmmmmmmmmmmmmmmmmmmmmm'
huffman_code(corpus)
{'a': '0100',
'b': '1011',
'c': '1000',
'd': '0010',
'e': '1101110',
'f': '0000',
'g': '11111',
'h': '11110',
'i': '00010',
'j': '11010',
'k': '10011',
'l': '10010',
'm': '1110',
'n': '1100',
'o': '00011',
'p': '01010',
'q': '11011110',
'r': '010110',
's': '0011',
't': '010111',
'u': '110110',
'v': '1010',
'w': '11011111',
'x': '0111',
'z': '0110'}
What do we do if some characters in the text did not appear in the corpus?
- We can add them to the corpus - not very reasonable for large text
- We can add all characters to the corpus with a small initial frequency:
print(''.join([chr(c) for c in range(128)]))
�
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
Compression ratio¶
This is a measure of how much space is saved by using the Huffman code to compress the text:
def compression_ratio(text, corpus):
codebook = huffman_code(corpus)
len_compress = len(compress(text, codebook))
len_ascii = len(text) * 7
return len_compress / len_ascii
Lets see how the language of the corpus affects the compression ratio:
from urllib.request import urlopen
with urlopen("http://www.gutenberg.org/cache/epub/42745/pg42745.txt") as f:
gauss = f.read().decode('utf-8')
print(gauss[:gauss.index('\n\r')])
The Project Gutenberg EBook of Gauss, by Friedrich August Theodor Winnecke
with urlopen("http://www.gutenberg.org/files/25447/25447-0.txt") as f:
russell = f.read().decode('utf-8')
print(russell[:russell.index('\n\r')])
Project Gutenberg's Mysticism and Logic and Other Essays, by Bertrand Russell
with urlopen("http://www.gutenberg.org/files/42743/42743-0.txt") as f:
table_ronde = f.read().decode('utf-8')
print(table_ronde[:table_ronde.index('\n\r')])
Project Gutenberg's Les Romans de la Table Ronde (1 / 5), by Anonyme
with urlopen("http://www.gutenberg.org/cache/epub/97/pg97.txt") as f:
flatland_book = f.read().decode('utf-8')
print(flatland_book[:flatland_book.index('\n\r')])
The Project Gutenberg EBook of Flatland, by Edwin A. Abbott
print("self",compression_ratio(flatland_book, flatland_book))
print("en",compression_ratio(flatland_book, russell))
print("de",compression_ratio(flatland_book, gauss))
print("fr",compression_ratio(flatland_book, table_ronde))
self 0.6564487342348225 en 0.6600341125397221 de 0.6740207814752815 fr 0.6887171389789191
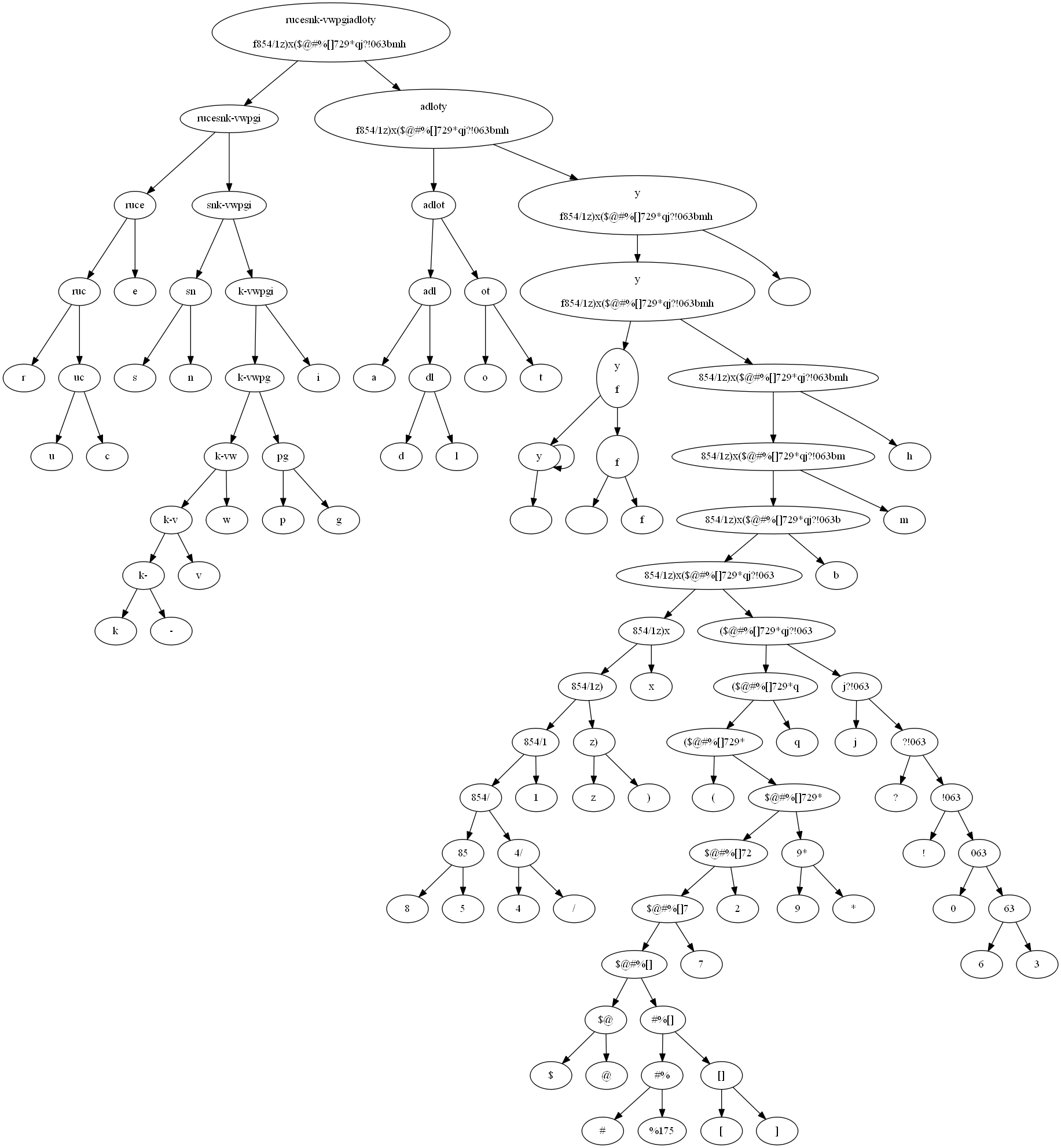
Here is the Huffman tree for "Flatland", with some minor modifications to the text to make the tree more clear:
Supplementry¶
The following code was used to generate the Huffman tree image:
import pydot # https://github.com/nlhepler/pydot-py3, http://pyparsing.wikispaces.com/Download+and+Installation
Couldn't import dot_parser, loading of dot files will not be possible.
def tree_to_str(tree):
if isinstance(tree, str):
return tree
return ''.join([tree_to_str(item) for item in tree])
def add_to_node(tree, node, graph):
left, right = tree
left_node, right_node = pydot.Node(tree_to_str(left)), pydot.Node(tree_to_str(right))
graph.add_node(left_node)
graph.add_node(right_node)
graph.add_edge(pydot.Edge(node, left_node))
graph.add_edge(pydot.Edge(node, right_node))
if not isinstance(left, str):
add_to_node(left, left_node, graph)
if not isinstance(right, str):
add_to_node(right, right_node, graph)
def tree_to_graph(tree):
graph = pydot.Dot(graph_type='digraph',strict=True)
root = pydot.Node(tree_to_str(tree))
graph.add_node(root)
add_to_node(tree, root, graph)
return graph
tree_to_str(tree)
'livadnt e'
graph = tree_to_graph(tree)
with open("tmp.dot","w") as f:
f.write(graph.to_string())
!dot tmp.dot -Tpng -ohuffman_tree.png
!huffman_tree.png
for c in flatland_book:
if ord(c) >= 128:
print(ord(c))
65279
flatland_book_clean = flatland_book.replace(chr(65279), '').replace('"','').replace("'",'').replace(",",'').replace(";",'').replace(":",'').replace(".",'')
flatland_tree = build_huffman_tree(char_count(flatland_book_clean.lower()))
tree_to_str(flatland_tree)
'rucesnk-vwpgiadloty\n\rf854/1z)x($@#%[]729*qj?!063bmh '
graph = tree_to_graph(flatland_tree)
with open("tmp.dot","w") as f:
f.write(graph.to_string())
!dot tmp.dot -Tpng -oflatland_tree.png
!flatland_tree.png
Fin¶
This notebook is part of the Extended introduction to computer science course at Tel-Aviv University.
The notebook was written using Python 3.2 and IPython 0.13.1.
The code is available at https://raw.github.com/yoavram/CS1001.py/master/recitation11.ipynb.
The notebook can be viewed online at http://nbviewer.ipython.org/urls/raw.github.com/yoavram/CS1001.py/master/recitation11.ipynb.
This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.