git is not really a "Version Control System". It is better described as a "Content Management System", that turns out to be really good for version control.
What should a "content manager" do?
We'll try and design our own, and then see what git has to say.
The general idea of this presentation comes from the git parable. The git foundations page extends the same idea.
A mysterious introduction¶
Later on, I'm going to ask you to solve a very difficult problem.
Here's some background that might help.
I'm going to describe "Crytographic hashes". It won't be obvious why that's a good idea for a little while.
See : Wikipedia on hash functions.
A hash is the result of running a hash function over a block of data. The hash is a fixed length string that is the signature of that exact block of data. Let's run this in Python:
import hashlib
sha1_hash_function = hashlib.sha1
sha1_hash_function
<function _hashlib.openssl_sha1>
message = "git is a rude word in UK English"
hash_value = sha1_hash_function(message).hexdigest()
hash_value
'fec41478c4f497c1d90fd28610f4272c78a6867e'
Not too exciting so far. However, the rather magical nature of this string is not yet apparent. Here's the trick:
There is no practical way for you to find another message that will give the same hash_value
The hash_value then is (nearly) completely unique to that set of bytes.
For example, a tiny change in the string makes the hash completely different:
sha1_hash_function("git is a rude word in UK English.").hexdigest() # Add a full stop
'9e87add001f13aa79ed7b42a5effbfc60aa8584e'
So, if you give me some data, and I calculate the hash value, and it comes out as "fec41478c4f497c1d90fd28610f4272c78a6867e", then I can be very sure that the data you gave me was exactly the string "git is a rude word in UK English".
The story so far...¶
You are writing a breakthrough paper showing that you can entirely explain the brain using random numbers. You've got the draft paper, and the analysis script and a figure for the paper. These are all in a directory modestly named nobel_prize.
In this directory, you have the paper draft nobel_prize.txt, the analysis script very_clever_analysis.py, and a figure for the paper stunning_figure.png.
# Make the directory for the paper and change into the directory
from os import chdir, getcwd, mkdir, listdir
from os.path import split as psplit, abspath, isdir
import shutil
# If we are in the nobel_prize directory already, get out
current_path = abspath(getcwd())
if current_path.endswith('nobel_prize'):
chdir('..') # Change down a directory
# If the directory exists, nuke it
if isdir('nobel_prize'):
shutil.rmtree('nobel_prize')
# Make the new directory, and change to it
mkdir('nobel_prize')
chdir('nobel_prize')
# Check we are there
print(getcwd())
# The directory should be empty at this point
assert listdir('.') == []
/Users/mb312/dev_trees/pna-notebooks/nobel_prize
%%file nobel_prize.txt
The brain is just a set of random numbers
=========================================
We have discovered that the brain is a set of random numbers.
We have charts and graphs to back us up.
Writing nobel_prize.txt
%%file very_clever_analysis.py
# The brain analysis script
import numpy as np
# Make brain data
brain_size = (128, 128)
random_data = np.random.normal(size=brain_size)
Writing very_clever_analysis.py
# Get the figure from storage
!cp ../images/stunning_figure.png .
import os
os.listdir('.')
['nobel_prize.txt', 'stunning_figure.png', 'very_clever_analysis.py']
The dog ate my results¶
You've been working on this paper for a while.
About 2 weeks ago, you were very excited with the results. You ran the script, made the figure, and went to your advisor, Josephine. She was excited too. The figure looks good! You get ready to publish in Science.
Today you finished cleaning up for the Science paper, and reran the analysis, and it doesn't look that good anymore. You go to see Josephine. She says "It used to look better than that". That's what you think too. But:
- Did it really look better before?
- If it did, why does it look different now?
Deja vu all over again¶
Given you are so clever and you have worked out the brain, it's really easy for you to leap in your time machine, and go back two weeks to start again.
What are you going to do differently this time?
Make regular snapshots¶
You decide to make your own content management system called fancy_backups.
It's very simple.
Every time you finish doing some work on your paper, you make a snapshot of the analysis directory.
The snapshot is just a copy of all the files in the directory, kept somewhere safe.
You make a directory to store the snapshots called .fancy_backups:
!mkdir .fancy_backups
Then you make a directory for the first backup:
!mkdir .fancy_backups/1
!mkdir .fancy_backups/1/files
And you copy the files there:
!cp * .fancy_backups/1/files
Some utility code to show directory listings
""" A little utility to display the structure of directory trees
Don't worry about the detail here, you'll see below what it does.
The code is not complicated, but it's not relevant to the main points on git.
Inspired by:
http://lorenzod8n.wordpress.com/2007/12/13/creating-a-tree-utility-in-python-part-2/
with thanks.
This version is my own copyright (Matthew Brett) released under 2-clause BSD
"""
from os import getcwd, listdir
from os.path import isdir, join as pjoin
# Unicode constants for constructing the tree trunk and branches
ALONG = u'\u2500'
DOWN = u'\u2502'
DOWN_RIGHT = u'\u251c'
ELBOW_RIGHT = u'\u2514'
BLUE = u'\033[94m'
ENDC = u'\033[0m'
DOWN_RIGHT_ALONG = DOWN_RIGHT + ALONG * 2 + u" "
ELBOW_RIGHT_ALONG = ELBOW_RIGHT + ALONG * 2 + u" "
CONTINUE_INDENT = DOWN + u' ' * 3
FINISH_INDENT = u' ' * 4
def print_tree(root_path=None, indent_str=u''):
""" Print tree structure starting from `root_path`
Parameters
----------
root_path : None or str, optional
path from which to print directory tree structure. If None, use current
directory.
indent_str : str, optional
prefix to print for every entry in the tree. Usually '', and then set
by recursion into the function when printing subdirectories.
Returns
-------
None
"""
if root_path is None:
root_path = getcwd()
# ensure return of unicode paths from listdir
root_path = unicode(root_path)
paths = sorted(listdir(root_path))
if len(paths) == 0:
return
for path in paths[:-1]:
print_path(root_path, path, indent_str, False)
print_path(root_path, paths[-1], indent_str, True)
def print_path(root_path, path, indent_str, last_entry=False):
""" Print individual `path` (file or directory name) from `root_path`
Parameters
----------
root_path : str
path containing `path`
path : str
file name or directory name
indent_str : str
string to prefix to entry for this `path`
last_entry : bool, optional
Whether this is the last entry in a list of paths.
Returns
-------
None
"""
full_path = pjoin(root_path, path)
have_dir = isdir(full_path)
leader = ELBOW_RIGHT_ALONG if last_entry else DOWN_RIGHT_ALONG
path_colored = BLUE + path + ENDC if have_dir else path
print(indent_str + leader + path_colored)
if have_dir:
new_indent = FINISH_INDENT if last_entry else CONTINUE_INDENT
print_tree(full_path, indent_str + new_indent)
Reminding yourself of what you did¶
For good measure, you put a file in the snapshot directory to remind you when you did the snapshot, and who did it, and what was new for this snapshot
%%file .fancy_backups/1/info.txt
Date: April 1 2012, 14.30
Author: I. M. Awesome
Notes: First backup of my amazing idea
Writing .fancy_backups/1/info.txt
Now you have these files in the nobel_prize directory:
print_tree()
├── .fancy_backups │ └── 1 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── nobel_prize.txt ├── stunning_figure.png └── very_clever_analysis.py
Every time you do some work on the files, you back them up in the same way. After a few days:
!echo "The charts are very impressive\n" >> nobel_prize.txt
!mkdir .fancy_backups/2
!mkdir .fancy_backups/2/files
!cp * .fancy_backups/2/files
%%file .fancy_backups/2/info.txt
Date: April 1 2012, 18.03
Author: I. M. Awesome
Notes: Fruit of enormous thought
Writing .fancy_backups/2/info.txt
!echo "The graphs are also compelling\n" >> nobel_prize.txt
!mkdir .fancy_backups/3
!mkdir .fancy_backups/3/files
!cp * .fancy_backups/3/files
%%file .fancy_backups/3/info.txt
Date: April 2 2012, 11.20
Author: I. M. Awesome
Notes: Now seeing things clearly
Writing .fancy_backups/3/info.txt
print_tree()
├── .fancy_backups │ ├── 1 │ │ ├── files │ │ │ ├── nobel_prize.txt │ │ │ ├── stunning_figure.png │ │ │ └── very_clever_analysis.py │ │ └── info.txt │ ├── 2 │ │ ├── files │ │ │ ├── nobel_prize.txt │ │ │ ├── stunning_figure.png │ │ │ └── very_clever_analysis.py │ │ └── info.txt │ └── 3 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── nobel_prize.txt ├── stunning_figure.png └── very_clever_analysis.py
# Now we just cheat, and copy the commits
!cp -r .fancy_backups/3 .fancy_backups/4
!cp -r .fancy_backups/3 .fancy_backups/5
!cp -r .fancy_backups/3 .fancy_backups/6
You keep doing this, until again the day comes to talk to Josephine. You now have 5 backups.
The future has not changed. Josephine again thinks the results have changed. But now - you can check.
You go back and look at .fancy_backups/1/stunning_figure.png. It does look different.
You go through all the .fancy_backups directories in order. It turns out that the figure changes in .fancy_backups/4.
You look in .fancy_backups/4/info.txt and it says:
Date: April 8 2012, 01.40
Author: I. M. Awesome
Notes: I always get the best ideas after I have been drinking.
Aha. Then you go find the problem in fancy_backups/4/very_clever_analysis.py.
You fix very_clever_analysis.py.
You make a new snapshot .fancy_backups/6.
Back on track for a scientific breakthrough
Terminology breakout¶
Here are some terms.
- Working tree: the files you are working on in the current directory (
nobel_prize). The filesvery_clever_analysis.py,nobel_prize.txt,stunning_figure.pngare the files in your working tree - Repository: the directory containing information about the history of the files. Your directory
.fancy_snapshotis the repository. - Commit: a completed snapshot. For example,
.fancy_backups/1contains one commit.
We'll use these terms to get used to them.
Breaking up work into chunks¶
You did some edits to the paper nobel_prize.txt to edit the introduction.
You also had a good idea for the analysis, and did some edits to very_clever_analysis.py.
You've got used to breaking each new commit (snapshot) up into little bits of extra work, with their own comments in the info.txt.
You want to make two commits from your changes:
- a commit containing the changes to
nobel_prize.txt, with comment "Changes to introduction" - a commit containing the changes to
very_clever_analysis.pywith comment "Crazy new analysis"
How can I do that?
The staging area¶
We adapt the workflow. Each time we start work, after a commit, we copy the last commit to directory .fancy_backups/staging_area. That will the default contents of our next commit.
!mkdir .fancy_backups/staging_area
!cp .fancy_backups/6/files/* .fancy_backups/staging_area
!ls .fancy_backups/staging_area
nobel_prize.txt stunning_figure.png very_clever_analysis.py
Now, you do your edits to nobel_prize.txt, and very_clever_analysis.py in your working tree (the nobel_prize directory). Then you get ready for the next commit with:
!cp nobel_prize.txt .fancy_backups/staging_area
The staging area now contains all the files for the upcoming commit (snapshot).
You make the commit with:
!mkdir .fancy_backups/7
!mkdir .fancy_backups/7/files
!cp .fancy_backups/staging_area/* .fancy_backups/7/files
%%file .fancy_backups/7/info.txt
Date: April 10 2012, 14.30
Author: I. M. Awesome
Notes: Changes to introduction
Writing .fancy_backups/7/info.txt
Now you are ready for the next commit, with the changes to the analysis script.
!cp very_clever_analysis.py .fancy_backups/staging_area
The commit is now staged and ready to be saved.
# Our commit procedure; same as last time with "8" instead of "7"
!mkdir .fancy_backups/8
!mkdir .fancy_backups/8/files
!cp .fancy_backups/staging_area/* .fancy_backups/8/files
%%file .fancy_backups/8/info.txt
Date: April 10 2012, 14.35
Author: I. M. Awesome
Notes: Crazy new analysis
Writing .fancy_backups/8/info.txt
Here is what we have in our .fancy_backups directory:
print_tree('.fancy_backups')
├── 1 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 2 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 3 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 4 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 5 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 6 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 7 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt ├── 8 │ ├── files │ │ ├── nobel_prize.txt │ │ ├── stunning_figure.png │ │ └── very_clever_analysis.py │ └── info.txt └── staging_area ├── nobel_prize.txt ├── stunning_figure.png └── very_clever_analysis.py
Now the very difficult problem¶
Let's say that the figure stunning_figure.png is large.
Let's say it changes only once across our 8 commits, at commit 5.
What should we do to save disk space for .fancy_backups?
Exercise - your strategy¶
Split into pairs.
In five minutes, we'll share ideas.
My crazy idea - use hash values as file names¶
Make a new directory:
!mkdir .fancy_backups/objects
Calculate the hash value for the figure:
import hashlib
# read the bytes for the figure into a string
figure_data = open('.fancy_backups/1/files/stunning_figure.png', 'rb').read()
# Calculate the hash value
figure_hash = hashlib.sha1(figure_data).hexdigest()
figure_hash
'aff88ecead2c7166770969a54dc855c8b91be864'
Save the figure with the hash value as the file name:
!cp .fancy_backups/1/files/stunning_figure.png .fancy_backups/objects/$figure_hash
Do the same for the other two files in the first commit.
import os
def copy_to_hash(fname):
# Read the data
binary_data = open(fname, 'rb').read()
# Find the hash
hash_value = hashlib.sha1(binary_data).hexdigest()
# Save with the hash filename
hash_fname = '.fancy_backups/objects/' + hash_value
if os.path.isfile(hash_fname):
print "We already have a hash file for " + fname
else:
open(hash_fname, 'wb').write(binary_data)
return hash_value
paper_hash = copy_to_hash('.fancy_backups/1/files/nobel_prize.txt')
script_hash = copy_to_hash('.fancy_backups/1/files/very_clever_analysis.py')
Making the directory listing¶
Here are the hashes for all files:
print 'Hash for stunning_figure.png:', figure_hash
print 'Hash for nobel_prize:', paper_hash
print 'Hash for very_clever_analysis.py:', script_hash
Hash for stunning_figure.png: aff88ecead2c7166770969a54dc855c8b91be864 Hash for nobel_prize: 3af8809ecb9c6dec33fc7e5ad330e384663f5a0d Hash for very_clever_analysis.py: e7f3ca9157fd7088b6a927a618e18d4bc4712fb6
print_tree('.fancy_backups/objects')
├── 3af8809ecb9c6dec33fc7e5ad330e384663f5a0d ├── aff88ecead2c7166770969a54dc855c8b91be864 └── e7f3ca9157fd7088b6a927a618e18d4bc4712fb6
Now point the snapshot to the hash filename versions of the files by making a text directory listing or tree listing:
%%file .fancy_backups/1/directory_list
Filename Hash value
======== ==========
stunning_figure.png aff88ecead2c7166770969a54dc855c8b91be864
nobel_prize.txt 3af8809ecb9c6dec33fc7e5ad330e384663f5a0d
very_clever_analysis.py e7f3ca9157fd7088b6a927a618e18d4bc4712fb6
Writing .fancy_backups/1/directory_list
The next commit - saves space!¶
# Nothing to for unchanged figure - already have hash value file
figure_hash = copy_to_hash('.fancy_backups/2/files/stunning_figure.png')
# Makes a new copy
paper_hash = copy_to_hash('.fancy_backups/2/files/nobel_prize.txt')
# Nothing to for unchanged script - already have hash value file
script_hash = copy_to_hash('.fancy_backups/2/files/very_clever_analysis.py')
print 'Hash for stunning_figure.png:', figure_hash
print 'Hash for nobel_prize:', paper_hash
print 'Hash for very_clever_analysis.py:', script_hash
We already have a hash file for .fancy_backups/2/files/stunning_figure.png We already have a hash file for .fancy_backups/2/files/very_clever_analysis.py Hash for stunning_figure.png: aff88ecead2c7166770969a54dc855c8b91be864 Hash for nobel_prize: bc330d8886bb1b36a49d8e7ebb07d3443190b0e6 Hash for very_clever_analysis.py: e7f3ca9157fd7088b6a927a618e18d4bc4712fb6
Only the nobel_prize.txt has changed. So:
%%file .fancy_backups/2/directory_list
Filename Hash value
======== ==========
stunning_figure.png aff88ecead2c7166770969a54dc855c8b91be864
nobel_prize.txt bc330d8886bb1b36a49d8e7ebb07d3443190b0e6
very_clever_analysis.py e7f3ca9157fd7088b6a927a618e18d4bc4712fb6
Writing .fancy_backups/2/directory_list
An even more crazy idea - hash the tree¶
I guess we can store the tree for the first commit according to its hash:
tree_hash = copy_to_hash('.fancy_backups/1/directory_list')
tree_hash
'63d466086dd359c0b34d21e04b812781c7153b23'
And we can do the same for the second commit:
copy_to_hash('.fancy_backups/2/directory_list')
'd45095659d1ea567b90aaf923e265bf41cbb126f'
Now - would I get the same hash if I had had a different figure?
Even more crazy idea - make the whole commit into a text file¶
How about this?
%%file .fancy_backups/1/commit
Date: April 1 2012, 14.30
Author: I. M. Awesome
Notes: First backup of my amazing idea
Tree: 63d466086dd359c0b34d21e04b812781c7153b23
Writing .fancy_backups/1/commit
And now I can hash the commit!
commit_hash = copy_to_hash('.fancy_backups/1/commit')
commit_hash
'f473e51a38d40772722205c92dddd4bdfd941ef8'
Would the commit hash value change if the figure changed?
So crazy it's actually git¶
Now look in .fancy_backups/objects:
ls .fancy_backups/objects
3af8809ecb9c6dec33fc7e5ad330e384663f5a0d bc330d8886bb1b36a49d8e7ebb07d3443190b0e6 f473e51a38d40772722205c92dddd4bdfd941ef8 63d466086dd359c0b34d21e04b812781c7153b23 d45095659d1ea567b90aaf923e265bf41cbb126f aff88ecead2c7166770969a54dc855c8b91be864 e7f3ca9157fd7088b6a927a618e18d4bc4712fb6
That's 3 file copies for the files from the first commit, 1 file copy from the second commit, 2 directory listings (for first and second commit) and one commit listing (for the first commit) = 7 hash objects.
We know that the file beginning 'f473e51' completely defines the first commit:
!cat .fancy_backups/objects/f473e51a38d40772722205c92dddd4bdfd941ef8
Date: April 1 2012, 14.30 Author: I. M. Awesome Notes: First backup of my amazing idea Tree: 63d466086dd359c0b34d21e04b812781c7153b23
Linking the commits¶
Can we completely get rid of .fancy_backups/1, .fancy_backups/2 ?
The reason for our commit names "1","2", "3" was so we know that commit "2" comes after commit "1" and before commit "3". Now our commits have arbitrary hashes, we can't tell the order from the name.
We can specify the order by adding the commit hash of the previous commit into the current commit:
%%file .fancy_backups/temporary_file
Date: April 1 2012, 18.03
Author: I. M. Awesome
Notes: Fruit of enormous thought
Tree: d45095659d1ea567b90aaf923e265bf41cbb126f
Parent: 63dab6e48ed2e9111624a3b5391bdf784c040b86
Writing .fancy_backups/temporary_file
commit2_hash = copy_to_hash('.fancy_backups/temporary_file')
Now we have the order of the commits from the links between them.
And now you are already a git master.
Gitting going (sorry)¶
Note: Much of the rest of this presentation comes from Fernando Perez' excellent git tutorial in his reproducible software repository. Thanks to Fernando for sharing.
We need to tell git about us before we start. This stuff will go into the commit information.
!git config --global user.name "Matthew Brett"
!git config --global user.email "matthew.brett@gmail.com"
git often needs to call up a text editor. Choose the editor you like here:
# Put here your preferred editor.
!git config --global core.editor gedit
We also turn on the use of color, which is very helpful in making the output of git easier to read
!git config --global color.ui "auto"
Getting help¶
!git
usage: git [--version] [--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p|--paginate|--no-pager] [--no-replace-objects] [--bare]
[--git-dir=<path>] [--work-tree=<path>] [--namespace=<name>]
[-c name=value] [--help]
<command> [<args>]
The most commonly used git commands are:
add Add file contents to the index
bisect Find by binary search the change that introduced a bug
branch List, create, or delete branches
checkout Checkout a branch or paths to the working tree
clone Clone a repository into a new directory
commit Record changes to the repository
diff Show changes between commits, commit and working tree, etc
fetch Download objects and refs from another repository
grep Print lines matching a pattern
init Create an empty git repository or reinitialize an existing one
log Show commit logs
merge Join two or more development histories together
mv Move or rename a file, a directory, or a symlink
pull Fetch from and merge with another repository or a local branch
push Update remote refs along with associated objects
rebase Forward-port local commits to the updated upstream head
reset Reset current HEAD to the specified state
rm Remove files from the working tree and from the index
show Show various types of objects
status Show the working tree status
tag Create, list, delete or verify a tag object signed with GPG
See 'git help <command>' for more information on a specific command.
Try git help add for an example.
Initializing the repository¶
Let's make this nobel_prize directory be version controlled with git.
# First pull the contents of the first commit from .fancy_backups
!cp .fancy_backups/1/files/* .
# Then delete .fancy_backups - we're done with those guys
!rm -rf .fancy_backups
!ls -a
. .. nobel_prize.txt stunning_figure.png very_clever_analysis.py
!git init
Initialized empty Git repository in /Users/mb312/dev_trees/pna-notebooks/nobel_prize/.git/
Just what we were expecting; a repository directory called .git
!ls .git
HEAD branches config description hooks info objects refs
The objects directory looks familiar. What's in there?
print_tree('.git/objects')
├── info └── pack
Nothing. That makes sense.
git add - put stuff into the staging area¶
!git add nobel_prize.txt
print_tree('.git/objects')
├── d9 │ └── 2d079af6a7f276cc8d63dcf2549c03e7deb553 ├── info └── pack
Doing git add nobel_prize.txt has added a file to the .git/objects directory. That filename looks suspiciously like a hash.
git add and the staging area¶
We expect that git add added the file to the staging area. Have we got any evidence of that?
!git status
# On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: nobel_prize.txt # # Untracked files: # (use "git add <file>..." to include in what will be committed) # # stunning_figure.png # very_clever_analysis.py
Reading real git objects¶
Git objects are nearly as simple as the objects we were writing in .fancy_backups.
The main difference is that, to save space, they are compressed, in fact using a library called zlib.
Here's a routine that gives us the raw contents of stuff in the .git/objects directory. There are neater commands in git to do this, but this shows just how simple these objects are.
import zlib # A compression / decompression library
def read_git_object(filename):
""" Read an object in the ``.git/objects`` directory
Yes, it's this simple - in this case. But git reserves the right to use
more complicated storage formats to save space when your repository is larger
"""
compressed_contents = open(filename, 'rb').read()
return zlib.decompress(compressed_contents)
filename = '.git/objects/d9/2d079af6a7f276cc8d63dcf2549c03e7deb553'
new_object_data = read_git_object(filename)
print new_object_data
blob 189�The brain is just a set of random numbers ========================================= We have discovered that the brain is a set of random numbers. We have charts and graphs to back us up.
It's just the contents of the file, with some cruft at the start (blob 189).
Staging the other files¶
!git add stunning_figure.png
!git add very_clever_analysis.py
!git status
# On branch master # # Initial commit # # Changes to be committed: # (use "git rm --cached <file>..." to unstage) # # new file: nobel_prize.txt # new file: stunning_figure.png # new file: very_clever_analysis.py #
print_tree('.git/objects')
├── 8a │ └── dc8bf371d669242ea998f78f9916867cc6203c ├── 9f │ └── fc311b29f0c87bf502b92df951d90ef88c1c7d ├── d9 │ └── 2d079af6a7f276cc8d63dcf2549c03e7deb553 ├── info └── pack
print read_git_object('.git/objects/8a/dc8bf371d669242ea998f78f9916867cc6203c')
blob 138�# The brain analysis script import numpy as np # Make brain data brain_size = (128, 128) random_data = np.random.normal(size=brain_size)
git commit - making the snapshot¶
!git commit -m "First backup of my amazing idea"
[master (root-commit) 1d7415e] First backup of my amazing idea 3 files changed, 12 insertions(+) create mode 100644 nobel_prize.txt create mode 100644 stunning_figure.png create mode 100644 very_clever_analysis.py
In the commit above, we used the -m flag to specify a message at the command line. If we don't do that, git will open the editor we specified in our configuration above and require that we enter a message. By default, git refuses to record changes that don't have a message to go along with them (though you can obviously 'cheat' by using an empty or meaningless string: git only tries to facilitate best practices, it's not your nanny).
We are now expecting to have a .git object for the directory tree, and for the commit.
print_tree('.git/objects')
├── 1d │ └── 7415e14ef0d556a97630997644307942f7f703 ├── 1e │ └── 322f4e782df4dfe963eda96517886f4e39a454 ├── 8a │ └── dc8bf371d669242ea998f78f9916867cc6203c ├── 9f │ └── fc311b29f0c87bf502b92df951d90ef88c1c7d ├── d9 │ └── 2d079af6a7f276cc8d63dcf2549c03e7deb553 ├── info └── pack
Here's the tree:
print read_git_object('.git/objects/1e/322f4e782df4dfe963eda96517886f4e39a454')
tree 141�100644 nobel_prize.txt��-����v̍c��T��S100644 stunning_figure.png���1)��{��-�Q���
}100644 very_clever_analysis.py��܋�q�i$.������|� <
These are in fact the file permissions, the filenames, and a binary form of the file hashes. Git will read this in a more friendly form for us:
!git ls-tree 1e322f4
100644 blob d92d079af6a7f276cc8d63dcf2549c03e7deb553 nobel_prize.txt 100644 blob 9ffc311b29f0c87bf502b92df951d90ef88c1c7d stunning_figure.png 100644 blob 8adc8bf371d669242ea998f78f9916867cc6203c very_clever_analysis.py
git log - what are the commits so far?¶
!git log
commit 1d7415e14ef0d556a97630997644307942f7f703
Author: Matthew Brett <matthew.brett@gmail.com>
Date: Thu May 2 22:04:55 2013 -0700
First backup of my amazing idea
!git log --parents
commit 1d7415e14ef0d556a97630997644307942f7f703
Author: Matthew Brett <matthew.brett@gmail.com>
Date: Thu May 2 22:04:55 2013 -0700
First backup of my amazing idea
Why are these two outputs the same?
git branch - which branch are we on?¶
We haven't covered branches yet. Branches are bookmarks. They label the commit we are on at the moment, and they track the commits as we do new ones.
The default branch for git is called master. Git creates it automatically when you do your first commit.
!git branch
* master
!git branch -v
* master 1d7415e First backup of my amazing idea
!ls .git/refs/heads
master
!cat .git/refs/heads/master
1d7415e14ef0d556a97630997644307942f7f703
git diff - what has changed?¶
Let's do a little bit more work... Again, in practice you'll be editing the files by hand, here we do it via shell commands for the sake of automation (and therefore the reproducibility of this tutorial!)
!echo "\nThe charts are very impressive\n" >> nobel_prize.txt
And now we can ask git what is different:
!git diff
diff --git a/nobel_prize.txt b/nobel_prize.txt index d92d079..47b7547 100644 --- a/nobel_prize.txt +++ b/nobel_prize.txt @@ -4,3 +4,6 @@ The brain is just a set of random numbers We have discovered that the brain is a set of random numbers. We have charts and graphs to back us up. + +The charts are very impressive +
You need to git add a file to put it into the staging area¶
Remember that git only commits stuff that has been added to the staging area.
At the moment we have changes that have not been staged:
!git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: nobel_prize.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
If we try and do a commit, git will tell us there is nothing to commit, because nothing has been staged:
!git commit
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: nobel_prize.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
The cycle of git virtue: work, commit, work, commit, ...¶
!git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: nobel_prize.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
!git add nobel_prize.txt
!git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: nobel_prize.txt
#
!git commit -m "Fruit of enormous thought"
[master ceda705] Fruit of enormous thought 1 file changed, 3 insertions(+)
Remember branches?
!cat .git/refs/heads/master
ceda7056aba330314aa219f7facbb00eb1a03248
git log revisited¶
First, let's see what the log shows us now:
!git log
commit ceda7056aba330314aa219f7facbb00eb1a03248 Author: Matthew Brett <matthew.brett@gmail.com> Date: Thu May 2 22:04:59 2013 -0700 Fruit of enormous thought commit 1d7415e14ef0d556a97630997644307942f7f703 Author: Matthew Brett <matthew.brett@gmail.com> Date: Thu May 2 22:04:55 2013 -0700 First backup of my amazing idea
!git log --parents
commit ceda7056aba330314aa219f7facbb00eb1a03248 1d7415e14ef0d556a97630997644307942f7f703 Author: Matthew Brett <matthew.brett@gmail.com> Date: Thu May 2 22:04:59 2013 -0700 Fruit of enormous thought commit 1d7415e14ef0d556a97630997644307942f7f703 Author: Matthew Brett <matthew.brett@gmail.com> Date: Thu May 2 22:04:55 2013 -0700 First backup of my amazing idea
Making log output more pithy¶
Sometimes it's handy to see a very summarized version of the log:
!git log --oneline --topo-order --graph
* ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
Git supports aliases: new names given to command combinations. Let's make this handy shortlog an alias, so we only have to type git slog and see this compact log:
# We create our alias (this saves it in git's permanent configuration file):
!git config --global alias.slog "log --oneline --topo-order --graph"
# And now we can use it
!git slog
* ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
git mv and rm: moving and removing files¶
While git add is used to add files to the list git tracks, we must also tell it if we want their names to change or for it to stop tracking them. In familiar Unix fashion, the mv and rm git commands do precisely this:
!git mv very_clever_analysis.py slightly_dodgy_analysis.py
!git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# renamed: very_clever_analysis.py -> slightly_dodgy_analysis.py
#
Note that these changes must be committed too, to become permanent! In git's world, until something has been committed, it isn't permanently recorded anywhere.
!git commit -m "I like this new name better"
[master 01df2e1] I like this new name better 1 file changed, 0 insertions(+), 0 deletions(-) rename very_clever_analysis.py => slightly_dodgy_analysis.py (100%)
!git slog
* 01df2e1 I like this new name better * ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
And git rm works in a similar fashion.
Exercise¶
Add a new file file2.txt, commit it, make some changes to it, commit them again, and then remove it (and don't forget to commit this last step!).
Local user, branching¶
What is a branch? Simply a label for the 'current' commit in a sequence of ongoing commits:
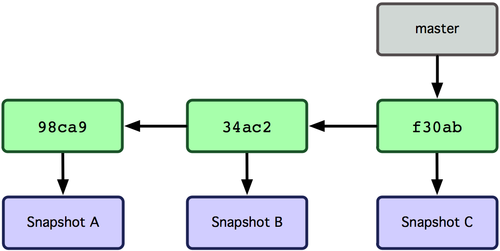
There can be multiple branches alive at any point in time; the working directory is the state of a special pointer called HEAD. In this example there are two branches, master and testing, and testing is the currently active branch since it's what HEAD points to:
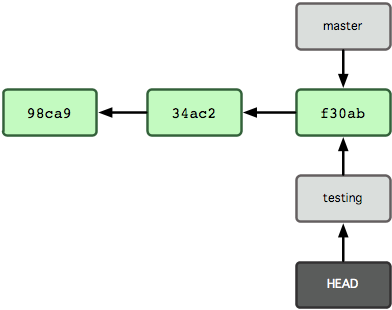
!cat .git/HEAD
ref: refs/heads/master
!cat .git/refs/heads/master
01df2e1271fe12e0586f3a3876a567c684d6ce9b
!git branch -v
* master 01df2e1 I like this new name better
Once new commits are made on a branch, HEAD and the branch label move with the new commits:
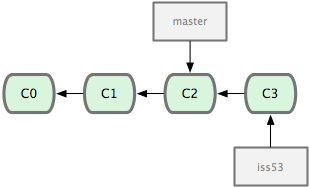
This allows the history of both branches to diverge:
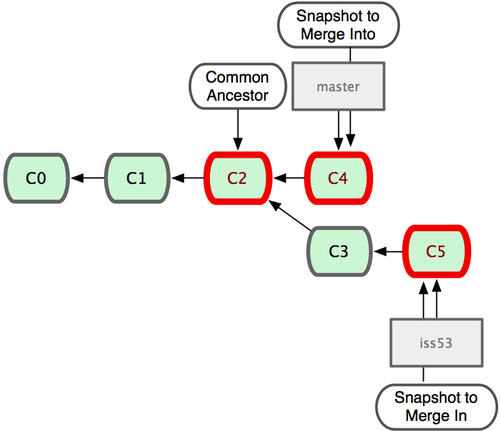
But based on this graph structure, git can compute the necessary information to merge the divergent branches back and continue with a unified line of development:
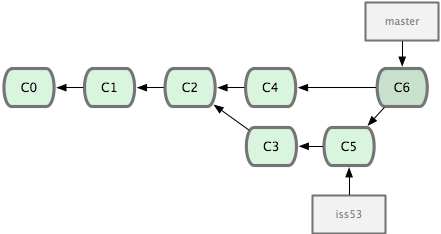
Let's now illustrate all of this with a concrete example. Let's get our bearings first:
!git status
!ls
# On branch master nothing to commit (working directory clean) nobel_prize.txt slightly_dodgy_analysis.py stunning_figure.png
We are now going to try two different routes of development: on the master branch we will add one file and on the experiment branch, which we will create, we will add a different one. We will then merge the experimental branch into master.
!git branch experiment
What just happened? We made a branch, which is a pointer to this same commit:
!ls .git/refs/heads
experiment master
!git branch -v
experiment 01df2e1 I like this new name better
* master 01df2e1 I like this new name better
!cat .git/refs/heads/experiment
01df2e1271fe12e0586f3a3876a567c684d6ce9b
How do we start working on this branch experiment rather than master?
git checkout - set the current branch, set the working tree from a commit¶
Up until now we have been on the master branch. When we make a commit, the master branch pointer (.git/refs/heads/master) moves up to track our most recent commit.
git checkout can switch us to using another branch:
!git checkout experiment
Switched to branch 'experiment'
What just happened?
!git branch -v
* experiment 01df2e1 I like this new name better
master 01df2e1 I like this new name better
!cat .git/HEAD
ref: refs/heads/experiment
As we'll see later, git checkout somebranch also sets the contents of the working tree to match the commit contents for somebranch. In this case the commits for master and experiment are currently the same, so we don't change the working tree at all.
Now let's do some changes on our experiment branch:
!echo "Some crazy idea" > experiment.txt
!git add experiment.txt
!git commit -m "Trying something new"
!git slog
[experiment b83cd47] Trying something new 1 file changed, 1 insertion(+) create mode 100644 experiment.txt * b83cd47 Trying something new * 01df2e1 I like this new name better * ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
Notice we have a new file called experiment.txt in this branch:
!ls
experiment.txt nobel_prize.txt slightly_dodgy_analysis.py stunning_figure.png
The experiment branch has now moved:
!cat .git/refs/heads/experiment
b83cd47540cb7dbd7d16292d8a35417f031716f9
git checkout again - reseting the working tree¶
If somewhere is a branch name, then git checkout somewhere selects somewhere as the current branch. It also resets the working tree to match the working tree for that commit.
!git checkout master
!cat .git/HEAD
Switched to branch 'master' ref: refs/heads/master
We're back to the working tree as of the master branch; experiment.txt has gone now.
!ls
nobel_prize.txt slightly_dodgy_analysis.py stunning_figure.png
Meanwhile we do some more work on master:
!git slog
* 01df2e1 I like this new name better * ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
!echo "All the while, more work goes on in master..." >> nobel_prize.txt
!git add nobel_prize.txt
!git commit -m "The mainline keeps moving"
!git slog
[master 5c436d0] The mainline keeps moving 1 file changed, 1 insertion(+) * 5c436d0 The mainline keeps moving * 01df2e1 I like this new name better * ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
!ls
nobel_prize.txt slightly_dodgy_analysis.py stunning_figure.png
Now let's do the merge
!git merge experiment -m "Merge in the experiment"
Merge made by the 'recursive' strategy.
experiment.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 experiment.txt
!git slog
* b444163 Merge in the experiment |\ | * b83cd47 Trying something new * | 5c436d0 The mainline keeps moving |/ * 01df2e1 I like this new name better * ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
An important aside: conflict management¶
While git is very good at merging, if two different branches modify the same file in the same location, it simply can't decide which change should prevail. At that point, human intervention is necessary to make the decision. Git will help you by marking the location in the file that has a problem, but it's up to you to resolve the conflict. Let's see how that works by intentionally creating a conflict.
We start by creating a branch and making a change to our experiment file:
!git branch trouble
!git checkout trouble
!echo "This is going to be a problem..." >> experiment.txt
!git add experiment.txt
!git commit -m"Changes in the trouble branch"
Switched to branch 'trouble' [trouble 6921250] Changes in the trouble branch 1 file changed, 1 insertion(+)
And now we go back to the master branch, where we change the same file:
!git checkout master
!echo "More work on the master branch..." >> experiment.txt
!git add experiment.txt
!git commit -m"Mainline work"
Switched to branch 'master' [master 1ebca55] Mainline work 1 file changed, 1 insertion(+)
More configuration for fuller output¶
This line tells git how to show conflicts in text files.
See git config --help and look for merge.conflictstyle for more information.
This setting asks git to show:
- The original file contents from
HEAD, the commit tree that you are merging into - The contents of the file as of last common ancestor commit
- The new file contents from the commit tree that you are merging from
!git config merge.conflictstyle diff3
So now let's see what happens if we try to merge the trouble branch into master:
!git merge trouble -m "Unlikely this one will work"
Auto-merging experiment.txt CONFLICT (content): Merge conflict in experiment.txt Automatic merge failed; fix conflicts and then commit the result.
Let's see what git has put into our file:
!cat experiment.txt
Some crazy idea <<<<<<< HEAD More work on the master branch... ||||||| merged common ancestors ======= This is going to be a problem... >>>>>>> trouble
Read this as:
- Common ancestor (between
||... and==) has nothing; HEAD- the current branch - (between<<... and||) addsMore work on the master branch...;- the
troublebranch (between==... and>>...) addsThis is going to be a problem....
At this point, we go into the file with a text editor, decide which changes to keep, and make a new commit that records our decision.
I'll do the edits by writing the file I want directly in this case:
%%file experiment.txt
Some crazy idea
More work on the master branch...
This is going to be a problem...
Overwriting experiment.txt
I've now made the edits. I decided that both pieces of text were useful, but integrated them with some changes:
!git status
# On branch master
# You have unmerged paths.
# (fix conflicts and run "git commit")
#
# Unmerged paths:
# (use "git add <file>..." to mark resolution)
#
# both modified: experiment.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
Let's then make our new commit:
!git add experiment.txt
!git commit -m "Completed merge of trouble, fixing conflicts along the way"
!git slog
[master 51fd6ff] Completed merge of trouble, fixing conflicts along the way * 51fd6ff Completed merge of trouble, fixing conflicts along the way |\ | * 6921250 Changes in the trouble branch * | 1ebca55 Mainline work |/ * b444163 Merge in the experiment |\ | * b83cd47 Trying something new * | 5c436d0 The mainline keeps moving |/ * 01df2e1 I like this new name better * ceda705 Fruit of enormous thought * 1d7415e First backup of my amazing idea
Other useful commands¶
Git resources¶
Introductory materials¶
There are lots of good tutorials and introductions for Git, which you can easily find yourself; this is just a short list of things I've found useful. For a beginner, I would recommend the following 'core' reading list, and below I mention a few extra resources:
- The smallest, and in the style of this tuorial: git - the simple guide
contains 'just the basics'. Very quick read.
The concise Git Reference: compact but with all the key ideas. If you only read one document, make it this one.
In my own experience, the most useful resource was [Understanding Git
Conceptually](http://www.sbf5.com/~cduan/technical/git). Git has a reputation for being hard to use, but I have found that with a clear view of what is actually a very simple internal design, its behavior is remarkably consistent, simple and comprehensible.
- For more detail, see the start of the excellent Pro Git online book, or similarly the early parts of the Git community book. Pro Git's chapters are very short and well illustrated; the community book tends to have more detail and has nice screencasts at the end of some sections.
If you are really impatient and just want a quick start, this visual git tutorial may be sufficient. It is nicely illustrated with diagrams that show what happens on the filesystem.
For windows users, an Illustrated Guide to Git on Windows is useful in that it contains also some information about handling SSH (necessary to interface with git hosted on remote servers when collaborating) as well as screenshots of the Windows interface.
- Cheat sheets
- Two different
[cheat](http://zrusin.blogspot.com/2007/09/git-cheat-sheet.html)
[sheets](http://jan-krueger.net/development/git-cheat-sheet-extended-edition)
in PDF format that can be printed for frequent reference.
Beyond the basics¶
As you've seen, this tutorial makes the bold assumption that you'll be able to understand how git works by seeing how it is built. These two documents, written in a similar spirit, are probably the most useful descriptions of the Git architecture short of diving into the actual implementation. They walk you through how you would go about building a version control system with a little story. By the end you realize that Git's model is almost an inevitable outcome of the proposed constraints:
- The Git parable by Tom Preston-Werner.
- Git foundations by Matthew Brett.
- Git ready
- A great website of posts on specific git-related topics, organized
by difficulty.
- QGit: an excellent Git GUI
- Git ships by default with gitk and git-gui, a pair of Tk graphical
clients to browse a repo and to operate in it. I personally have
found [qgit](http://sourceforge.net/projects/qgit/) to be nicer and
easier to use. It is available on modern linux distros, and since it
is based on Qt, it should run on OSX and Windows.
- Git Magic
- Another book-size guide that has useful snippets.
- The learning center at Github
- Guides on a number of topics, some specific to github hosting but
much of it of general value.
- A port of the Hg book's beginning
- The Mercurial book has a reputation
for clarity, so Carl Worth decided to
[port](http://cworth.org/hgbook-git/tour) its introductory chapter
to Git. It's a nicely written intro, which is possible in good
measure because of how similar the underlying models of Hg and Git
ultimately are.
- Intermediate tips
- A set of tips that contains some very valuable nuggets, once you're
past the basics.
For SVN users¶
If you want a bit more background on why the model of version control used by Git and Mercurial (known as distributed version control) is such a good idea, I encourage you to read this very well written post by Joel Spolsky on the topic. After that post, Joel created a very nice Mercurial tutorial, whose first page applies equally well to git and is a very good 're-education' for anyone coming from an SVN (or similar) background.
In practice, I think you are better off following Joel's advice and understanding git on its own merits instead of trying to bang SVN concepts into git shapes. But for the occasional translation from SVN to Git of a specific idiom, the Git - SVN Crash Course can be handy.
A few useful tips for common tasks¶
Better shell support¶
Adding git branch info to your bash prompt and tab completion for git commands and branches is extremely useful. I suggest you at least copy:
You can then source both of these files in your ~/.bashrc (Linux) or ~/.bash_profile (OSX), and then set your prompt (I'll assume you named them as the originals but starting with a . at the front of the name):
source $HOME/.git-completion.bash
source $HOME/.git-prompt.sh
PS1='[\u@\h \W$(__git_ps1 " (%s)")]\$ ' # adjust this to your prompt liking
See the comments in both of those files for lots of extra functionality they offer.
Embedding Git information in LaTeX documents¶
(Sent by Yaroslav Halchenko)
I use a Make rule:
# Helper if interested in providing proper version tag within the manuscript
revision.tex: ../misc/revision.tex.in ../.git/index
GITID=$$(git log -1 | grep -e '^commit' -e '^Date:' | sed -e 's/^[^ ]* *//g' | tr '\n' ' '); \
echo $$GITID; \
sed -e "s/GITID/$$GITID/g" $< >| $@
in the top level Makefile.common which is included in all
subdirectories which actually contain papers (hence all those
../.git). The revision.tex.in file is simply:
% Embed GIT ID revision and date
\def\revision{GITID}
The corresponding paper.pdf depends on revision.tex and includes the
line \input{revision} to load up the actual revision mark.
git export¶
Git doesn't have a native export command, but this works just fine:
git archive --prefix=fperez.org/ master | gzip > ~/tmp/source.tgz