
- IOCBucket. Resources like this are terrific and greatly appreciated by us and the community.
- Yara. Super Spiffy!
Tools in this Notebook:¶
- Workbench: Open Source Security Framework Workbench GitHub
- Yara: The pattern matching swiss knife for malware researchers Yara
Lets start up the workbench server...¶
Run the workbench server (from somewhere, for the demo we're just going to start a local one)
$ workbench_server
# Lets start to interact with workbench, please note there is NO specific client to workbench,
# Just use the ZeroRPC Python, Node.js, or CLI interfaces.
import zerorpc
c = zerorpc.Client()
c.connect("tcp://127.0.0.1:4242")
[None]

So I'm confused what am I suppose to do with workbench?¶
Workbench is often confusing for new users (we're trying to work on that). Please see our github repository https://github.com/SuperCowPowers/workbench for the latest documentation and notebooks examples (the notebook examples can really help). New users can start by typing **c.help()** after they connect to workbench.
# I forgot what stuff I can do with workbench
print c.help()
Welcome to Workbench: Here's a list of help commands: - Run c.help_basic() for beginner help - Run c.help_commands() for command help - Run c.help_workers() for a list of workers - Run c.help_advanced() for advanced help See https://github.com/SuperCowPowers/workbench for more information
print c.help_basic()
Workbench: Getting started...
- 1) $ print c.help_commands() for a list of commands
- 2) $ print c.help_command('store_sample') for into on a specific command
- 3) $ print c.help_workers() for a list a workers
- 4) $ print c.help_worker('meta') for info on a specific worker
- 5) $ my_md5 = c.store_sample(...)
- 6) $ output = c.work_request('meta', my_md5)
# STEP 1:
# Okay get the list of commands from workbench
print c.help_commands()
Workbench Commands: add_node(node_id, name, labels) add_rel(source_id, target_id, rel) clear_db() clear_graph_db() get_datastore_uri() get_sample(md5) get_sample_set(md5) get_sample_window(type_tag, size) has_node(node_id) have_sample(md5) help() help_advanced() help_basic() help_command(command) help_commands() help_worker(worker) help_workers() index_sample(md5, index_name) index_worker_output(worker_class, md5, index_name, subfield) search(index_name, query) store_sample(input_bytes, filename, type_tag) store_sample_set(md5_list) work_request(worker_class, md5, subkeys=None)
# STEP 2:
# Lets gets the infomation on a specific command 'store_sample'
print c.help_command('store_sample')
Command: store_sample(input_bytes, filename, type_tag)
Store a sample into the DataStore.
Args:
filename: name of the file (used purely as meta data not for lookup)
input_bytes: the actual bytes of the sample e.g. f.read()
type_tag: ('exe','pcap','pdf','json','swf', or ...)
Returns:
the md5 of the sample
# STEP 3:
# Now lets get infomation about the dynamically loaded workers (your site may have many more!)
# Next to each worker name is the list of dependences that worker has declared
print c.help_workers()
Workbench Workers: json_meta ['sample', 'meta'] log_meta ['sample', 'meta'] mem_base ['sample'] mem_connscan ['sample'] mem_dlllist ['sample'] mem_meta ['sample'] mem_procdump ['sample'] mem_pslist ['sample'] meta ['sample'] meta_deep ['sample', 'meta'] pcap_bro ['sample'] pcap_graph ['pcap_bro'] pcap_graph_0_1 ['pcap_bro'] pcap_http_graph ['pcap_bro'] pe_classifier ['pe_features', 'pe_indicators'] pe_deep_sim ['meta_deep'] pe_features ['sample'] pe_indicators ['sample'] pe_peid ['sample'] strings ['sample'] swf_meta ['sample', 'meta'] unzip ['sample'] url ['strings'] view ['meta'] view_customer ['meta'] view_log_meta ['log_meta'] view_meta ['meta'] view_pcap ['pcap_bro'] view_pcap_details ['view_pcap'] view_pdf ['meta', 'strings'] view_pe ['meta', 'strings', 'pe_peid', 'pe_indicators', 'pe_classifier', 'pe_disass'] view_zip ['meta', 'unzip'] vt_query ['meta'] yara_sigs ['sample']
# STEP 4:
# Lets gets the infomation about the meta worker
print c.help_worker('meta')
Worker: meta ['sample'] This worker computes meta data for any file type.

# STEP 5:
# Okay when we load up a file, we get the md5 back
filename = '../data/pe/bad/0cb9aa6fb9c4aa3afad7a303e21ac0f3'
with open(filename,'rb') as f:
my_md5 = c.store_sample(f.read(), filename, 'exe')
print my_md5
0cb9aa6fb9c4aa3afad7a303e21ac0f3

# Lets see what view_pe does
print c.help_worker('view_pe')
Worker: view_pe ['meta', 'strings', 'pe_peid', 'pe_indicators', 'pe_classifier', 'pe_disass'] Generates a high level summary view for PE files that incorporates a large set of workers
# Okay lets give it a try
c.work_request('view_pe', my_md5)
{'view_pe': {'classification': 'Evil!',
'customer': 'BearTron',
'disass': 'plugin_failed',
'encoding': 'binary',
'file_size': 20480,
'file_type': 'PE32 executable (GUI) Intel 80386, for MS Windows',
'filename': '../data/pe/bad/0cb9aa6fb9c4aa3afad7a303e21ac0f3',
'import_time': '2014-06-15T01:20:52.355000Z',
'indicators': [{'attributes': ['findwindowexa', 'findwindowa'],
'category': 'ANTI_DEBUG',
'description': 'Imported symbols related to anti-debugging',
'severity': 3},
{'category': 'MALFORMED', 'description': 'Checksum of Zero', 'severity': 1},
{'category': 'MALFORMED',
'description': 'Reported Checksum does not match actual checksum',
'severity': 2},
{'attributes': ['sendmessagea'],
'category': 'COMMUNICATION',
'description': 'Imported symbols related to network communication',
'severity': 1},
{'attributes': ['getmodulehandlea', 'getstartupinfoa'],
'category': 'PROCESS_MANIPULATION',
'description': 'Imported symbols related to process manipulation/injection',
'severity': 3},
{'attributes': ['getsystemmetrics'],
'category': 'PROCESS_SPAWN',
'description': 'Imported symbols related to spawning a new process',
'severity': 2}],
'length': 20480,
'md5': '0cb9aa6fb9c4aa3afad7a303e21ac0f3',
'mime_type': 'application/x-dosexec',
'peid_Matches': ['Microsoft Visual C++ v6.0'],
'type_tag': 'exe'}}

# Okay, that worker needed the output of pe_features and pe_indicators
# so what happened? The worker has a dependency list and workbench
# recursively satisfies that dependency list.. this is powerful because
# when we're interested in one particular analysis we just want to get
# the darn thing without having to worry about a bunch of details
# Well lets throw in a bunch of files!
import os
file_list = [os.path.join('../data/pe/bad', child) for child in os.listdir('../data/pe/bad')]
working_set = []
for filename in file_list:
with open(filename,'rb') as f:
md5 = c.store_sample(f.read(), filename, 'exe')
working_set.append(md5)
print working_set[:5]
['033d91aae8ad29ed9fbb858179271232', '0cb9aa6fb9c4aa3afad7a303e21ac0f3', '0e882ec9b485979ea84c7843d41ba36f', '0e8b030fb6ae48ffd29e520fc16b5641', '0eb9e990c521b30428a379700ec5ab3e']
# Okay we just pushed in a bunch of files, now we can extract features,
# look at indicators, peids, and yara sigs!
# Lets just randomly pick one to understand the details and then we'll look
# at running all of them a bit later.
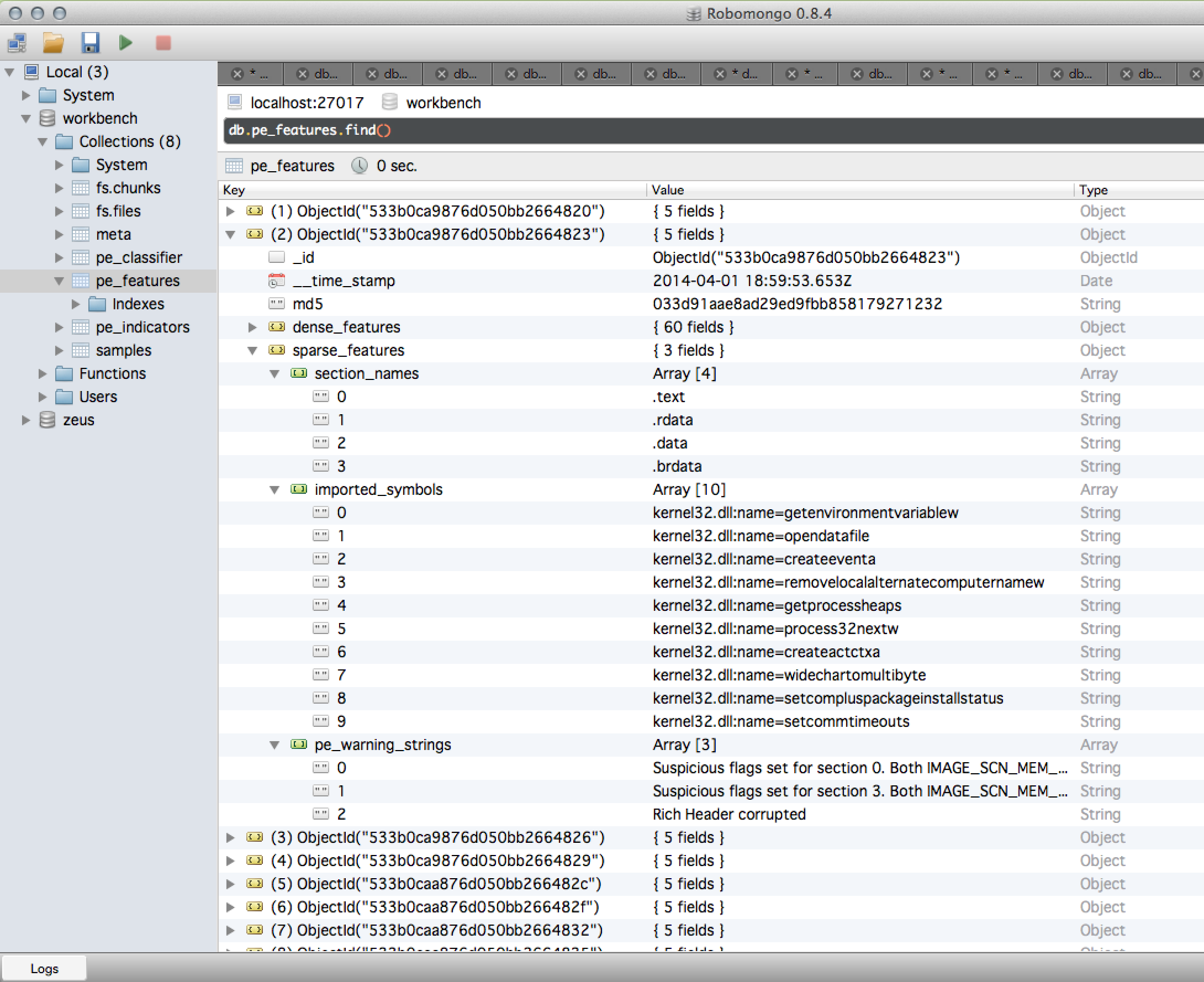
c.work_request('pe_features', working_set[0])
{'pe_features': {'dense_features': {'check_sum': 0,
'compile_date': 585810474,
'datadir_IMAGE_DIRECTORY_ENTRY_BASERELOC_size': 0,
'datadir_IMAGE_DIRECTORY_ENTRY_EXPORT_size': 0,
'datadir_IMAGE_DIRECTORY_ENTRY_IAT_size': 44,
'datadir_IMAGE_DIRECTORY_ENTRY_IMPORT_size': 40,
'datadir_IMAGE_DIRECTORY_ENTRY_RESOURCE_size': 0,
'debug_size': 0,
'export_size': 0,
'generated_check_sum': 98624,
'iat_rva': 17518,
'major_version': 0,
'minor_version': 0,
'number_of_bound_import_symbols': 0,
'number_of_bound_imports': 0,
'number_of_export_symbols': 0,
'number_of_import_symbols': 10,
'number_of_imports': 1,
'number_of_rva_and_sizes': 16,
'number_of_sections': 4,
'pe_char': 271,
'pe_dll': 0,
'pe_driver': 0,
'pe_exe': 1,
'pe_i386': 1,
'pe_majorlink': 6,
'pe_minorlink': 0,
'pe_warnings': 1,
'sec_entropy_brdata': 7.992004822536996,
'sec_entropy_data': 7.996253697966639,
'sec_entropy_rdata': 0.0,
'sec_entropy_reloc': 0,
'sec_entropy_rsrc': 0,
'sec_entropy_text': 6.4550179842911195,
'sec_raw_execsize': 84480,
'sec_rawptr_brdata': 57856,
'sec_rawptr_data': 14848,
'sec_rawptr_rdata': 0,
'sec_rawptr_rsrc': 0,
'sec_rawptr_text': 1024,
'sec_rawsize_brdata': 27648,
'sec_rawsize_data': 43008,
'sec_rawsize_rdata': 0,
'sec_rawsize_rsrc': 0,
'sec_rawsize_text': 13824,
'sec_va_execsize': 170626,
'sec_vasize_brdata': 49152,
'sec_vasize_data': 42586,
'sec_vasize_rdata': 65536,
'sec_vasize_rsrc': 0,
'sec_vasize_text': 13352,
'size_code': 13824,
'size_image': 180224,
'size_initdata': 43008,
'size_uninit': 65536,
'std_section_names': 0,
'total_size_pe': 85504,
'virtual_address': 4096,
'virtual_size': 13352,
'virtual_size_2': 65536},
'md5': '033d91aae8ad29ed9fbb858179271232',
'sparse_features': {'imp_hash': 'Not found: Install pefile 1.2.10-139 or later',
'imported_symbols': ['kernel32.dll:name=getenvironmentvariablew',
'kernel32.dll:name=opendatafile',
'kernel32.dll:name=createeventa',
'kernel32.dll:name=removelocalalternatecomputernamew',
'kernel32.dll:name=getprocessheaps',
'kernel32.dll:name=process32nextw',
'kernel32.dll:name=createactctxa',
'kernel32.dll:name=widechartomultibyte',
'kernel32.dll:name=setcompluspackageinstallstatus',
'kernel32.dll:name=setcommtimeouts'],
'pe_warning_strings': ['Suspicious flags set for section 0. Both IMAGE_SCN_MEM_WRITE and IMAGE_SCN_MEM_EXECUTE are set. This might indicate a packed executable.',
'Suspicious flags set for section 3. Both IMAGE_SCN_MEM_WRITE and IMAGE_SCN_MEM_EXECUTE are set. This might indicate a packed executable.',
'Rich Header corrupted'],
'section_names': ['.text', '.rdata', '.data', '.brdata']}}}
c.work_request('pe_indicators', working_set[0])
{'pe_indicators': {'indicator_list': [{'category': 'PE_WARN',
'description': 'Suspicious flags set for section 0. Both IMAGE_SCN_MEM_WRITE and IMAGE_SCN_MEM_EXECUTE are set. This might indicate a packed executable.',
'severity': 2},
{'category': 'PE_WARN',
'description': 'Suspicious flags set for section 3. Both IMAGE_SCN_MEM_WRITE and IMAGE_SCN_MEM_EXECUTE are set. This might indicate a packed executable.',
'severity': 2},
{'category': 'PE_WARN',
'description': 'Rich Header corrupted',
'severity': 2},
{'category': 'MALFORMED', 'description': 'Checksum of Zero', 'severity': 1},
{'category': 'MALFORMED',
'description': 'Reported Checksum does not match actual checksum',
'severity': 2},
{'category': 'MALFORMED',
'description': 'Image size does not match reported size',
'severity': 3},
{'attributes': ['.brdata'],
'category': 'MALFORMED',
'description': 'Section(s) with a non-standard name, tamper indication',
'severity': 3},
{'attributes': ['process32nextw'],
'category': 'PROCESS_MANIPULATION',
'description': 'Imported symbols related to process manipulation/injection',
'severity': 3}],
'md5': '033d91aae8ad29ed9fbb858179271232'}}
Your data - Transparent, Organized, Accessible¶
Everything done by workbench is pushed into the MongoDB backend, worker output is automatically pushed into the datastore and a very lightweight call is made to get the results. As seen in the workflow diagrame above, workers are chained together within a gevent-coprocessing server, data outputs are 'shallow copied' and pipelined into other workers. The whole process is efficient and elegant.
# Now we rip the peid on all the PE files
output = c.batch_work_request('pe_peid', {'md5_list':working_set})
output
<generator object iterator at 0x10b8c0a50>

Now we're going to take that generator and populate a Pandas Dataframe in ONE LINE of CODE! Are people paying attention?!? This is like Butter!¶
# At this granularity it opens up a new world
import pandas as pd
df = pd.DataFrame(output)
df.head(10)
| match_list | md5 | |
|---|---|---|
| 0 | [] | 033d91aae8ad29ed9fbb858179271232 |
| 1 | [Microsoft Visual C++ v6.0] | 0cb9aa6fb9c4aa3afad7a303e21ac0f3 |
| 2 | [Microsoft Visual Basic v5.0 - v6.0] | 0e882ec9b485979ea84c7843d41ba36f |
| 3 | [] | 0e8b030fb6ae48ffd29e520fc16b5641 |
| 4 | [] | 0eb9e990c521b30428a379700ec5ab3e |
| 5 | [Microsoft Visual C++ v6.0] | 127f2bade752445b3dbf2cf2ea75c201 |
| 6 | [] | 139385a91b9bca0833bdc1fa77e42b91 |
| 7 | [Microsoft Visual C++ v6.0] | 13dcc5b4570180118eb65529b77f6d89 |
| 8 | [Armadillo v4.x] | 1cac80a2147cd8f3860547e43edcaa00 |
| 9 | [] | 1cea13cf888cd8ce4f869029f1dbb601 |
10 rows × 2 columns
# So lets get a breakdown of the PEID matches
df['match'] = [str(match) for match in df['match_list']]
df['match'].value_counts()
[] 26 ['Microsoft Visual C++ v6.0'] 4 ['Borland Delphi 3.0 (???)'] 3 ['Microsoft Visual C++ v7.0'] 3 ['UPX v1.25 (Delphi) Stub'] 2 ['Armadillo v4.x'] 1 ['ASPack v1.06b'] 1 ['Microsoft Visual Basic v5.0 - v6.0'] 1 ['Safeguard 1.03 -> Simonzh'] 1 ['Upack v0.399 -> Dwing'] 1 ['UPX v0.71 - v0.72', 'tElock v0.7x - v0.84'] 1 ['Pack Master v1.0', 'PEX v0.99'] 1 ['Microsoft Visual Basic v5.0'] 1 ['UPX -> www.upx.sourceforge.net'] 1 ['Dev-C++ v5'] 1 ['Borland Delphi 4.0'] 1 ['BobSoft Mini Delphi -> BoB / BobSoft'] 1 dtype: int64
# Now we do the same thing for yara sigs
output = c.batch_work_request('yara_sigs', {'md5_list':working_set})
output
<generator object iterator at 0x10b9310f0>
# Pop it into a dataframe with one line of code
df_yara = pd.DataFrame(output)
df_yara.head(10)
| matches | md5 | |
|---|---|---|
| 0 | {} | 033d91aae8ad29ed9fbb858179271232 |
| 1 | {u'anti_debug': [{u'matches': True, u'meta': {... | 0cb9aa6fb9c4aa3afad7a303e21ac0f3 |
| 2 | {u'anti_debug': [{u'matches': True, u'meta': {... | 0e882ec9b485979ea84c7843d41ba36f |
| 3 | {u'import': [{u'matches': True, u'meta': {'des... | 0e8b030fb6ae48ffd29e520fc16b5641 |
| 4 | {} | 0eb9e990c521b30428a379700ec5ab3e |
| 5 | {u'import': [{u'matches': True, u'meta': {'des... | 127f2bade752445b3dbf2cf2ea75c201 |
| 6 | {} | 139385a91b9bca0833bdc1fa77e42b91 |
| 7 | {u'import': [{u'matches': True, u'meta': {'des... | 13dcc5b4570180118eb65529b77f6d89 |
| 8 | {u'anti_debug': [{u'matches': True, u'meta': {... | 1cac80a2147cd8f3860547e43edcaa00 |
| 9 | {u'anti_debug': [{u'matches': True, u'meta': {... | 1cea13cf888cd8ce4f869029f1dbb601 |
10 rows × 2 columns
# Here the yara output is a bit more details so we're going to carve it up a bit
import numpy as np
df_yara['match'] = [str(match.keys()) if match.keys() else np.nan for match in df_yara['matches'] ]
df_yara = df_yara.dropna()
df_yara['count'] = 1
df_yara.groupby(['match','md5']).sum()
| count | ||
|---|---|---|
| match | md5 | |
| ['anti_debug'] | 0cb9aa6fb9c4aa3afad7a303e21ac0f3 | 1 |
| 0e882ec9b485979ea84c7843d41ba36f | 1 | |
| 1cac80a2147cd8f3860547e43edcaa00 | 1 | |
| 1cea13cf888cd8ce4f869029f1dbb601 | 1 | |
| 2d094b6c69020091b68d1bcf5d11fa4b | 1 | |
| 2d09b5768e3617523d8afa110361919c | 1 | |
| 2d09b8d9852c3176259915e3509bcbd1 | 1 | |
| 2d09cc92bbe29d96bb3a91b350d1725f | 1 | |
| 9ceccd9f32cb2ad0b140b6d15d8993b6 | 1 | |
| 9e42ff1e6f75ae3e60b24e48367c8f26 | 1 | |
| cc113aa59c04b17e7cb832fc417f104d | 1 | |
| ['import', 'anti_debug'] | 0e8b030fb6ae48ffd29e520fc16b5641 | 1 |
| 127f2bade752445b3dbf2cf2ea75c201 | 1 | |
| 13dcc5b4570180118eb65529b77f6d89 | 1 | |
| 2058c50de5976c67a09dfa5e0e1c7eb5 | 1 | |
| b681485cb9e0cad73ee85b9274c0d3c2 | 1 | |
| ['import'] | 2d09e4aff42aebac87ae2fd737aba94f | 1 |
17 rows × 1 columns
# Alright now that we have an overview of matches we drill down again
c.work_request('yara_sigs', 'b681485cb9e0cad73ee85b9274c0d3c2')
{'yara_sigs': {'matches': {'anti_debug': [{'matches': True,
'meta': {'description': 'Anti-Debug Imports'},
'rule': 'process_manip',
'strings': [{'data': 'FindWindow',
'flags': 283,
'identifier': '$',
'offset': 44110},
{'data': 'GetTickCount',
'flags': 283,
'identifier': '$',
'offset': 43080}],
'tags': []}],
'import': [{'matches': True,
'meta': {'description': 'Communication Calls (Winsock WSA)'},
'rule': 'winsock_wsa',
'strings': [{'data': 'WSASocket',
'flags': 275,
'identifier': '$',
'offset': 44206}],
'tags': []},
{'matches': True,
'meta': {'description': 'Communication Calls (Winsock Generic)'},
'rule': 'winsock_generic',
'strings': [{'data': 'closesocket',
'flags': 275,
'identifier': '$',
'offset': 44290},
{'data': 'connect', 'flags': 275, 'identifier': '$', 'offset': 44280},
{'data': 'recv', 'flags': 275, 'identifier': '$', 'offset': 44272},
{'data': 'send', 'flags': 275, 'identifier': '$', 'offset': 44264},
{'data': 'socket', 'flags': 275, 'identifier': '$', 'offset': 44295}],
'tags': []}]},
'md5': 'b681485cb9e0cad73ee85b9274c0d3c2'}}
Wrap Up¶
Well for this short notebook we focused on PE File static analysis. Obviously we need lots more yara sigs (please some nice person help us out with yara sigs). We hope this exercise showed some neato functionality using Workbench, we encourage you to check out the GitHub repository and our other notebooks:
- PCAP_to_Graph for a short notebook on turning this PCAP into a Neo4j graph.
- Workbench Demo general introduction to Workbench.
- PCAP_DriveBy a detail look at a Web DriveBy from the ThreatGlass repository.
- PE File Sim Graph using Neo4j to generate a similarity graph using PE File features.
- Generator Pipelines using the client/server streaming generators to demonstrate 'chaining' generators.