Driveby PCAP analysis¶

We sumbled upon a really great collection of PCAPs that were interactions with suspicious websites. Which seemed to lead to the suspicion being correct, and an end system got exploited, or the suspicion was wrong and nothing bad happened. While we do no machine learning in this notebook, there are several techniques that are usful for collecting statistics about features across all the samples. However, when dealing with network traffic it's often very useful to have the additional context that a full session can provide. Here we try to break out of the sample box and begin showing groups of data as viewed by Bro in each network session.
Tools¶
- Bro (http://www.bro.org)
- IPython (http://www.ipython.org)
- pandas (http://pandas.pydata.org)
What we did:¶
- Data gathered with Bro (default Bro content)
- bro -C -r <pcap file> local
- Data cleanup
- Explored the Data!
- Found some patterns
- Exploited the patterns to us find new things!
Thanks!¶
- To the people that we borrowed the data from. Once they get back to me I'll be sure to give proper recognition. :)
# All the imports and some basic level setting with various versions
import IPython
import os
import pylab
import string
import pandas
import pickle
import matplotlib
import collections
import numpy as np
import pandas as pd
import matplotlib as plt
from __future__ import division
print "IPython version: %s" %IPython.__version__
print "pandas version: %s" %pd.__version__
print "numpy version: %s" %np.__version__
print "matplotlib version: %s" %plt.__version__
%matplotlib inline
pylab.rcParams['figure.figsize'] = (16.0, 5.0)
IPython version: 2.0.0 pandas version: 0.13.0rc1-32-g81053f9 numpy version: 1.6.1 matplotlib version: 1.3.1
# Mapping of fields of the files we want to read in and initial setup of pandas dataframes
# Borrowed from aonther notebook, this time we're just going to focus on notice and files for starters
# But the rest are here when we need 'em
logs_to_process = {
'conn.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','proto','service','duration','orig_bytes','resp_bytes','conn_state','local_orig','missed_bytes','history','orig_pkts','orig_ip_bytes','resp_pkts','resp_ip_bytes','tunnel_parents','sample'],
'dns.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','proto','trans_id','query','qclass','qclass_name','qtype','qtype_name','rcode','rcode_name','AA','TC','RD','RA','Z','answers','TTLs','rejected','sample'],
'files.log' : ['ts','fuid','tx_hosts','rx_hosts','conn_uids','source','depth','analyzers','mime_type','filename','duration','local_orig','is_orig','seen_bytes','total_bytes','missing_bytes','overflow_bytes','timedout','parent_fuid','md5','sha1','sha256','extracted','sample'],
'ftp.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','user','password','command','arg','mime_type','file_size','reply_code','reply_msg','data_channel.passive','data_channel.orig_h','data_channel.resp_h','data_channel.resp_p','fuid','sample'],
'http.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','trans_depth','method','host','uri','referrer','user_agent','request_body_len','response_body_len','status_code','status_msg','info_code','info_msg','filename','tags','username','password','proxied','orig_fuids','orig_mime_types','resp_fuids','resp_mime_types','sample'],
'irc.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','nick','user','command','value','addl','dcc_file_name','dcc_file_size','dcc_mime_type','fuid','sample'],
'notice.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','fuid','file_mime_type','file_desc','proto','note','msg','sub','src','dst','p','n','peer_descr','actions','suppress_for','dropped','remote_location.country_code','remote_location.region','remote_location.city','remote_location.latitude','remote_location.longitude','sample'],
'signatures.log' : ['ts','src_addr','src_port','dst_addr','dst_port','note','sig_id','event_msg','sub_msg','sig_count','host_count','sample'],
'smtp.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','trans_depth','helo','mailfrom','rcptto','date','from','to','reply_to','msg_id','in_reply_to','subject','x_originating_ip','first_received','second_received','last_reply','path','user_agent','fuids','is_webmail','sample'],
'ssl.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','version','cipher','server_name','session_id','subject','issuer_subject','not_valid_before','not_valid_after','last_alert','client_subject','client_issuer_subject','cert_hash','validation_status','sample'],
'tunnel.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','tunnel_type','action','sample'],
'weird.log' : ['ts','uid','id.orig_h','id.orig_p','id.resp_h','id.resp_p','name','addl','notice','peer','sample']
}
conndf = pd.DataFrame(columns=logs_to_process['conn.log'])
dnsdf = pd.DataFrame(columns=logs_to_process['dns.log'])
filesdf = pd.DataFrame(columns=logs_to_process['files.log'])
ftpdf = pd.DataFrame(columns=logs_to_process['ftp.log'])
httpdf = pd.DataFrame(columns=logs_to_process['http.log'])
ircdf = pd.DataFrame(columns=logs_to_process['irc.log'])
noticedf = pd.DataFrame(columns=logs_to_process['notice.log'])
smtpdf = pd.DataFrame(columns=logs_to_process['smtp.log'])
ssldf = pd.DataFrame(columns=logs_to_process['ssl.log'])
weirddf = pd.DataFrame(columns=logs_to_process['weird.log'])
process_files = ['notice.log','files.log']
for dirName, subdirList, fileList in os.walk('..'):
for fname in fileList:
tags = dirName.split('/')
if len(tags) == 2 and fname in logs_to_process:
logname = fname.split('.')
try:
if fname in process_files:
#print "Processing %s - %s" %(tags[1], fname)
tempdf = pd.read_csv(dirName+'/'+fname, sep='\t',skiprows=8, header=None,
names=logs_to_process[fname][:-1], skipfooter=1)
tempdf['sample'] = tags[1]
if fname == 'conn.log':
conndf = conndf.append(tempdf)
if fname == 'dns.log':
dnsdf = dnsdf.append(tempdf)
if fname == 'files.log':
filesdf = filesdf.append(tempdf)
if fname == 'ftp.log':
ftpdf = ftpdf.append(tempdf)
if fname == 'http.log':
httpdf = httpdf.append(tempdf)
if fname == 'notice.log':
noticedf = noticedf.append(tempdf)
if fname == 'signatures.log':
sigdf = sigdf.append(tempdf)
if fname == 'smtp.log':
smtpdf = smtpdf.append(tempdf)
if fname == 'ssl.log':
ssldf = ssldf.append(tempdf)
if fname == 'tunnel.log':
tunneldf = tunneldf.append(tempdf)
if fname == 'weird.log':
weirddf = weirddf.append(tempdf)
except Exception as e:
print "[*] error: %s, on %s/%s" % (str(e), dirName, fname)
#You can use these to save a copy of the raw dataframe, because reading in the files over-and-over again is awful
#pickle.dump(filesdf, open('files.dataframe', 'wb'))
filesdf = pickle.load(open('files.dataframe', 'rb'))
#pickle.dump(noticedf, open('notice.dataframe', 'wb'))
noticedf = pickle.load(open('notice.dataframe', 'rb'))
Well, it took a while to get the data read into the dataframes let's take a quick peek at what it looks like. If everything looks pretty, or at least how we'd expect we can move on with some analysis.
noticedf.head(3)
| ts | uid | id.orig_h | id.orig_p | id.resp_h | id.resp_p | fuid | file_mime_type | file_desc | proto | note | msg | sub | src | dst | p | n | peer_descr | actions | suppress_for | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.338423e+09 | C2cBNO2DuqzRxvfac6 | 192.168.88.10 | 1068 | 195.210.47.109 | 80 | FEdFLYNt00bHPa9sb | application/x-dosexec | http://navozmi.ipq.co/f/1100.exe?ts=405b7ca&af... | tcp | TeamCymruMalwareHashRegistry::Match | Malware Hash Registry Detection rate: 33% Las... | https://www.virustotal.com/en/search/?query=85... | 192.168.88.10 | 195.210.47.109 | 80 | - | bro | Notice::ACTION_LOG | 3600 | ... |
| 0 | 1.336524e+09 | Cbs89uRcl9HnSASEc | 192.168.15.10 | 1104 | 85.17.147.215 | 80 | FaeRAd49IO4E2V2ndb | application/x-dosexec | http://mybisyo.com/w.php?f=96ece&e=2 | tcp | TeamCymruMalwareHashRegistry::Match | Malware Hash Registry Detection rate: 24% Las... | https://www.virustotal.com/en/search/?query=bc... | 192.168.15.10 | 85.17.147.215 | 80 | - | bro | Notice::ACTION_LOG | 3600 | ... |
| 1 | 1.336524e+09 | Cpcwv13LGlszc39oQc | 192.168.15.10 | 1105 | 85.17.147.215 | 80 | F2ZPuu3GQcfZNFezk | application/x-shockwave-flash | http://mybisyo.com/data/field.swf | tcp | TeamCymruMalwareHashRegistry::Match | Malware Hash Registry Detection rate: 60% Las... | https://www.virustotal.com/en/search/?query=d6... | 192.168.15.10 | 85.17.147.215 | 80 | - | bro | Notice::ACTION_LOG | 3600 | ... |
3 rows × 27 columns
filesdf.head()
| ts | fuid | tx_hosts | rx_hosts | conn_uids | source | depth | analyzers | mime_type | filename | duration | local_orig | is_orig | seen_bytes | total_bytes | missing_bytes | overflow_bytes | timedout | parent_fuid | md5 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.320786e+09 | FDbQJR35HG4EfZ0nb4 | 75.119.221.151 | 192.168.41.10 | C9KyD7n902u8uko9j | HTTP | 0 | SHA1,MD5 | text/html | - | 0.000024 | - | F | 4305 | - | 0 | 0 | F | - | 8b07497c411ce08842cf2145380d238e | ... |
| 1 | 1.320786e+09 | Fhv2Jx2f5EiIs52jf4 | 75.119.221.151 | 192.168.41.10 | C9KyD7n902u8uko9j | HTTP | 0 | SHA1,MD5 | text/plain | - | 0.000323 | - | F | 3233 | 3233 | 0 | 0 | F | - | db8f4e6949c0fc0fc9cadf85d02e099a | ... |
| 2 | 1.320786e+09 | FUJQ4k1k9m9EUOiDL5 | 31.31.74.239 | 192.168.41.10 | CaTFVw42sBoMSa9Zcl | HTTP | 0 | SHA1,MD5 | text/html | - | 0.000000 | - | F | 2717 | 2717 | 0 | 0 | F | - | b030b8e337724d4a2786041a38c0951f | ... |
| 3 | 1.320786e+09 | F7p0uQ1a9czI7BIwW4 | 69.31.75.17 | 192.168.41.10 | CgQksU3fAxqa2VzJmi | HTTP | 0 | SHA1,MD5 | text/html | - | 0.000000 | - | F | 1567 | 1567 | 0 | 0 | F | - | 644a4a82d7580c2cf9f97e13b0ee1ced | ... |
| 4 | 1.320786e+09 | FitWMF3UfEasz2Vyql | 75.119.221.151 | 192.168.41.10 | C9KyD7n902u8uko9j | HTTP | 0 | SHA1,MD5 | application/x-shockwave-flash | - | 1.356016 | - | F | 1177469 | 1177469 | 0 | 0 | F | - | c2045c6a5e95a99f6ebbc073e62894cd | ... |
5 rows × 24 columns
noticedf.note.value_counts()
TeamCymruMalwareHashRegistry::Match 7212 Scan::Address_Scan 105 SSL::Invalid_Server_Cert 105 dtype: int64
Everything checks out nicely, and we've got a super-high-level view of what kinds of alerts were generated by Bro. I have a feeling the Team Cymru MHR results will come in handy if we want to get a feel for what's being detected vs. what's sneaking past the goalie.

hashes = set()
def grab_hash(s):
if 'virustotal' in s:
hashes.add(s.split('=')[1])
return ''
throwaway = noticedf['sub'].map(grab_hash)
def box_plot_df_setup(series_a, series_b):
# Count up all the times that a category from series_a
# matches up with a category from series_b. This is
# basically a gigantic contingency table
cont_table = collections.defaultdict(lambda : collections.Counter())
for val_a, val_b in zip(series_a.values, series_b.values):
cont_table[val_a][val_b] += 1
# Create a dataframe
# A dataframe with keys from series_a as the index, series_b_keys
# as the columns and the counts as the values.
dataframe = pd.DataFrame(cont_table.values(), index=cont_table.keys())
dataframe.fillna(0, inplace=True)
return dataframe
Everybody loves a good stacked bar graph. Here we can get a general feel for the data and there seem to be a lot of files! Apparently in some of the driveby activities some malware was (probably) run and grabbed something from an FTP site
ax = box_plot_df_setup(filesdf['source'], filesdf['mime_type']).T.plot(kind='bar', stacked=True)
pylab.xlabel('Mime-Type')
pylab.ylabel('Number of Files')
patches, labels = ax.get_legend_handles_labels()
ax.legend(patches, labels, title="Service Type")
<matplotlib.legend.Legend at 0x130e284d0>

filesdf.mime_type.value_counts().head()
text/html 252401 text/plain 244182 image/jpeg 200075 image/gif 141428 image/png 116836 dtype: int64
print "Lots of files!"
print "Total # of files (across all samples): %s" %filesdf.shape[0]
print "Total # of unique files: %s" %len(filesdf['sha1'].unique())
print "Total # of network sessions involving files: %s" %len(filesdf['conn_uids'].unique())
print "Total # of unique mime_types: %s" %len(filesdf['mime_type'].unique())
print "Total # of unique filenames: %s" %len(filesdf['filename'].unique())
Lots of files! Total # of files (across all samples): 1100106 Total # of unique files: 312453 Total # of network sessions involving files: 238211 Total # of unique mime_types: 46 Total # of unique filenames: 18324
# We can use some of the output from above and get rid of them and look are more exciting files
# Just an example, I don't think we'll do much with this data frame today
boring = set(['text/html','text/plain','image/jpeg','image/gif','image/png','application/xml','image/x-icon'])
exciting_filesdf = filesdf[filesdf['mime_type'].apply(lambda x: x not in boring)]
exciting_filesdf.head(2)
| ts | fuid | tx_hosts | rx_hosts | conn_uids | source | depth | analyzers | mime_type | filename | duration | local_orig | is_orig | seen_bytes | total_bytes | missing_bytes | overflow_bytes | timedout | parent_fuid | md5 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 1.320786e+09 | FitWMF3UfEasz2Vyql | 75.119.221.151 | 192.168.41.10 | C9KyD7n902u8uko9j | HTTP | 0 | SHA1,MD5 | application/x-shockwave-flash | - | 1.356016 | - | F | 1177469 | 1177469 | 0 | 0 | F | - | c2045c6a5e95a99f6ebbc073e62894cd | ... |
| 7 | 1.320786e+09 | FAnnpf1X8a1w6JLtV9 | 95.211.160.73 | 192.168.41.10 | CENibi3Z3bv3ZVlyqf | HTTP | 0 | SHA1,MD5 | application/x-dosexec | - | 0.895983 | - | F | 342016 | - | 0 | 0 | F | - | ae12a0a1d449b9f2816d20546c477c0b | ... |
2 rows × 24 columns

After getting a high-level look at the data and doing our Python and pandas stretches we're set to move on to some more intresting ways to view the data and how different properties relate to one another.
Instead of looking at the top 10 of this or that, let's see how we can examine the top N broken down by various categories.
We'll start off easy and look at the most popular protocols and then the most popular mime-types by count within those protocls. Followed by a view of the same data but with the restriction that Bro know something about the filename, and last but not least we can look at the most popular filenames within a mime-type within a protocol!
filesdf['count'] = 1
filesdf[['source','mime_type','count']].groupby(['source','mime_type']).sum().sort('count', ascending=0).head(10)
| count | ||
|---|---|---|
| source | mime_type | |
| HTTP | text/html | 252401 |
| text/plain | 244182 | |
| image/jpeg | 200075 | |
| image/gif | 141428 | |
| image/png | 116836 | |
| binary | 39964 | |
| application/x-dosexec | 30456 | |
| application/x-shockwave-flash | 17878 | |
| application/jar | 14372 | |
| application/zip | 12247 |
10 rows × 1 columns
# We can get a slightly different view if we look at percentages of files
# Wonder how accurate the percentages are vs. monitored network traffic?
filesdf.groupby('source')['mime_type'].apply(lambda x: pd.value_counts(x)/x.count().astype(float)).head(20)
source
FTP_DATA application/x-java-applet 1.000000
HTTP text/html 0.229434
text/plain 0.221963
image/jpeg 0.181869
image/gif 0.128559
image/png 0.106205
binary 0.036328
application/x-dosexec 0.027685
application/x-shockwave-flash 0.016251
application/jar 0.013064
application/zip 0.011133
application/xml 0.006645
application/pdf 0.004922
application/vnd.ms-fontobject 0.002872
application/x-java-applet 0.002678
text/x-c 0.002036
application/octet-stream 0.001929
text/x-asm 0.001733
application/x-elc 0.000960
application/vnd.ms-cab-compressed 0.000865
dtype: float64
filesdf['count'] = 1
filesdf[filesdf['filename'] != '-'][['source','mime_type','count']].groupby(['source','mime_type']).sum().sort('count', ascending=0).head(10)
| count | ||
|---|---|---|
| source | mime_type | |
| HTTP | application/x-dosexec | 17793 |
| binary | 16810 | |
| application/jar | 8874 | |
| image/jpeg | 4756 | |
| application/pdf | 4672 | |
| application/zip | 4247 | |
| image/png | 847 | |
| image/gif | 161 | |
| text/plain | 120 | |
| text/html | 80 |
10 rows × 1 columns
filesdf[filesdf['filename'] != '-'][['source','mime_type','filename','count']].groupby(['source','mime_type','filename']).sum().sort('count', ascending=0).head(20)
| count | |||
|---|---|---|---|
| source | mime_type | filename | |
| HTTP | application/x-dosexec | setup.exe | 4471 |
| binary | setup.exe | 1461 | |
| application/x-dosexec | about.exe | 1204 | |
| contacts.exe | 1170 | ||
| info.exe | 1146 | ||
| calc.exe | 1101 | ||
| readme.exe | 1081 | ||
| scandsk.exe | 645 | ||
| PluginInstall.exe | 598 | ||
| files/load1.exe | 432 | ||
| application/jar | 938a99f1be85e19406438f9a572fdf71.jar | 374 | |
| loading.jar | 351 | ||
| a03cb4b8e5bb148134a57a2c87ddacd9.jar | 300 | ||
| application/x-dosexec | files/load2.exe | 231 | |
| uplayermediaplayer-setup.exe | 231 | ||
| foto43.exe | 188 | ||
| binary | ./files/cit_video.module | 133 | |
| image/png | ad516503a11cd5ca435acc9bb6523536.png | 127 | |
| application/jar | app.jar | 112 | |
| application/x-dosexec | 2.exe | 108 |
20 rows × 1 columns
The takeaway seems to be that if you're going to cause a file to be downloaded by a user over HTTP (malicious or not, but likely malicious) you should really call it 'setup.exe' followed not-so closely by: 'about.exe', 'contacts.exe', 'info.exe', 'calc.exe', 'readme.exe'. And looking for a mime-type of 'binary' or 'application/x-dosexec' should do pretty well.
# Filenames with a '/' in them??
# Just some random exploring, wonder why these have a path associated w/them and not the rest? Questions for another day.
print filesdf[filesdf['filename'].str.contains('/')]['filename'].value_counts().head(10)
print
print filesdf[filesdf['filename'].str.contains('\.\.')]['filename'].value_counts()
files/load1.exe 432 files/load2.exe 231 ./files/cit_video.module 133 ./files/cit_ffcookie.module 60 users/leftunch/file/ractrupt.exe 44 files/load5.exe 42 files/load3.exe 37 ./files/barman.png 36 ./files/up.bin 26 users/root/file/file.exe 26 dtype: int64 ./../load/12.exe 4 ../admin/files/cit_video.module 2 Ray Rice had three TD\xe2\x80\x99s..jpeg 2 ../admin/files/cit_ffcookie.module 2 ../admin/files/gconfig8.dll 2 \xe1\xba\xa3nh h\xc3\xa0i h\xc3\xb3a ra ng\xc3\xa0nh c\xc6\xa1 kh\xc3\xad b\xc3\xa1ch khoa....jpg 2 ../admin/files/webinjects/merged-1.txt 2 Sexy Dr..jpg 2 dtype: int64
# Lots of duplicate files Wonder what these look like?
filesdf.md5.value_counts().head()
28d6814f309ea289f847c69cf91194c6 8328 b4491705564909da7f9eaf749dbbfbb1 7527 cd2e0e43980a00fb6a2742d3afd803b8 5831 d9feff91276e487e595cc23f62d259bc 4740 325472601571f31e1bf00674c368d335 4320 dtype: int64
filesdf[filesdf['filename'] != '-'][['filename','mime_type','count']].groupby(['filename','mime_type']).sum().sort('count', ascending=0).head(10)
| count | ||
|---|---|---|
| filename | mime_type | |
| setup.exe | application/x-dosexec | 4471 |
| binary | 1461 | |
| about.exe | application/x-dosexec | 1204 |
| contacts.exe | application/x-dosexec | 1170 |
| info.exe | application/x-dosexec | 1146 |
| calc.exe | application/x-dosexec | 1101 |
| readme.exe | application/x-dosexec | 1081 |
| scandsk.exe | application/x-dosexec | 645 |
| PluginInstall.exe | application/x-dosexec | 598 |
| files/load1.exe | application/x-dosexec | 432 |
10 rows × 1 columns
filesdf[filesdf['filename'] != '-'][['filename','md5','count']].groupby(['filename','md5']).sum().sort('count', ascending=0).head(10)
| count | ||
|---|---|---|
| filename | md5 | |
| loading.jar | 2d272e75e6be0d397dcc9b493936d873 | 238 |
| setup.exe | 7776d42f2e2167591de7321b18704e9a | 134 |
| b87668c676063c0f36f2c7faef6b7d3d | 92 | |
| 618ba1bbd7e537482f7e058419fa8a28 | 92 | |
| 405f6ef1172501148ac36495780a69d0 | 78 | |
| 938a99f1be85e19406438f9a572fdf71.jar | e872a71a6060413c1abfa5e41839aa8d | 72 |
| ad516503a11cd5ca435acc9bb6523536.png | 102345b9de00a7f5d7ee00f688ba68ab | 72 |
| 938a99f1be85e19406438f9a572fdf71.jar | 88f7ddd10321d1a035b05a7a0ca263f1 | 66 |
| foto43.exe | 0cd1f2bc16529f88a919830c87f180f7 | 66 |
| Applet.jar | 0e658e5217ea9f0d28e60ab491e716f2 | 63 |
10 rows × 1 columns
It seems (from this data) there is a fair amount of resuse of both filenames and actual samples. Perhaps these samples were of the more boring exploit kits that don't try to obfuscate each individual download. Oh well, at least we've got some easy potential IOCs to look for.
Now we've got some hunches, how can we back these up using the results of the MHR events we found earlier?
# Lookup to see what the Bro - Team Cymru Malware Hash Registry picks up
def tc_mhr_present_single(sha1):
if sha1 in hashes:
return True
return False
tempdf = filesdf
tempdf['count'] = 1
tempdf['mhr'] = tempdf['sha1'].map(tc_mhr_present_single)
# The following 2 Commands Print out the tables below
#tempdf[tempdf['filename'] != '-'][['mhr','filename','count']].groupby(['mhr','filename']).sum().sort('count', ascending=0).head(12)
#tempdf[tempdf['filename'] != '-'][['filename','mhr','count']].groupby(['filename','mhr']).sum().sort('count', ascending=0).head(12)
The tables below were converted to .png files for pretty display, but they're just screen-caps of the above commands
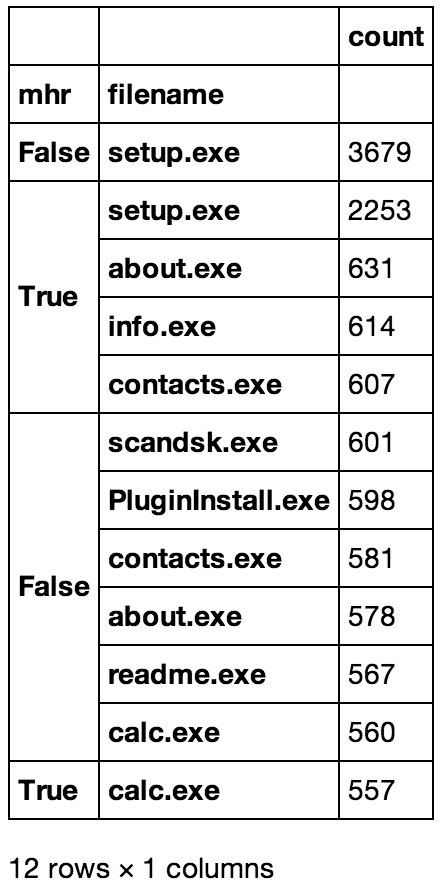
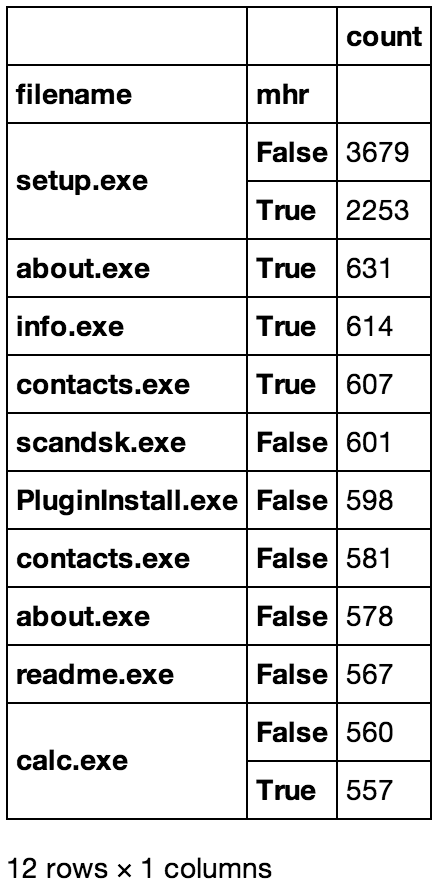
tempdf.groupby('mhr')['filename'].apply(lambda x: pd.value_counts(x)/len(tempdf.index))
mhr
False - 0.940176
setup.exe 0.003344
scandsk.exe 0.000546
PluginInstall.exe 0.000544
contacts.exe 0.000528
about.exe 0.000525
readme.exe 0.000515
calc.exe 0.000509
info.exe 0.000499
files/load1.exe 0.000230
a03cb4b8e5bb148134a57a2c87ddacd9.jar 0.000224
uplayermediaplayer-setup.exe 0.000210
938a99f1be85e19406438f9a572fdf71.jar 0.000204
foto43.exe 0.000157
files/load2.exe 0.000135
...
True windows-update-sp4-kb66639-setup.exe 0.000001
f13f6a19.jar 0.000001
34dcaa0c.jar 0.000001
7af76.pdf 0.000001
windows-update-sp3-kb74463-setup.exe 0.000001
windows-update-sp2-kb66551-setup.exe 0.000001
a37002b0.jar 0.000001
windows-update-sp2-kb88572-setup.exe 0.000001
d1af818e.jar 0.000001
load/49.exe 0.000001
FIX_KB111703.exe 0.000001
windows-update-sp2-kb81951-setup.exe 0.000001
c5d53367.jar 0.000001
2bba99f3.jar 0.000001
3.exe 0.000001
Length: 18400, dtype: float64

# Number of files per sample
filesdf[['sample','count']].groupby(['sample']).sum().sort('count', ascending=0).head(10)
| count | |
|---|---|
| sample | |
| fffa22264e6ebebdfcc3c9526d8bc19c_20130313 | 14598 |
| c352624409de5b479f26a904c29d413f_20130719 | 4936 |
| ef3be687d525c85b00a91efdfda711e9_20121204 | 4928 |
| 51e711110049f0788bcac16b0acd558a_20130814 | 4674 |
| e259f0c751b02bd2419538ddc6b99772_20140314 | 3496 |
| d3819a56d678838f0e01fa2c637f3b1a_20111004 | 3480 |
| 7138d1cd36d383673844013d4eae97af_20130116 | 3312 |
| ae3d23caa091be1d3df1107898ea5231_20110902 | 3292 |
| a1da196baea54a71d34e6421b7a8f040_20130908 | 3210 |
| 0f0fd9ada450841ab1fd767d7387e489_20130803 | 3198 |
10 rows × 1 columns
filesdf[['conn_uids','count']].groupby(['conn_uids']).sum().sort('count', ascending=0).head(10)
| count | |
|---|---|
| conn_uids | |
| C9KyD7n902u8uko9j | 2916 |
| CENibi3Z3bv3ZVlyqf | 972 |
| COhNOY1kIa174wPKK6 | 972 |
| CCBO2p2JDrryA2k1gb | 972 |
| CaTFVw42sBoMSa9Zcl | 972 |
| CBiXTD427Vvn9DXymd | 972 |
| CN0i562AIvEXAXVdS6 | 972 |
| CVANI54q1eA8PJEPNl | 972 |
| C9O3nw2UUAuRVkxqHe | 972 |
| CgQrNE10zxxoKNF1O7 | 972 |
10 rows × 1 columns
It's always fun when data causes more questions than it answers! What's with all the repeated 972s above? Maybe we're not looking at it correctly
filesdf[['sample','conn_uids','count']].groupby(['sample','conn_uids']).sum().sort('count', ascending=0).head(20)
| count | ||
|---|---|---|
| sample | conn_uids | |
| fffa22264e6ebebdfcc3c9526d8bc19c_20130313 | C9KyD7n902u8uko9j | 2910 |
| CVANI54q1eA8PJEPNl | 970 | |
| C3lCz83lC3PGZKMUR9 | 970 | |
| C9O3nw2UUAuRVkxqHe | 970 | |
| CBiXTD427Vvn9DXymd | 970 | |
| CCBO2p2JDrryA2k1gb | 970 | |
| CN0i562AIvEXAXVdS6 | 970 | |
| COhNOY1kIa174wPKK6 | 970 | |
| CENibi3Z3bv3ZVlyqf | 970 | |
| Cf6EYC22yHQsulV7mc | 970 | |
| CgQksU3fAxqa2VzJmi | 970 | |
| CgQrNE10zxxoKNF1O7 | 970 | |
| CaTFVw42sBoMSa9Zcl | 970 | |
| c352624409de5b479f26a904c29d413f_20130719 | CFPUpI2zTBwvTHZWe5 | 468 |
| C7HuQHe3tlEc740dk | 450 | |
| 42c918193f5f3fe008e1ad8007ee0a64_20120612 | CNCa6Z2Ybjei8Cu0B | 446 |
| CJtgFl3ASjdriC7976 | 438 | |
| b1321a9f0dd6c48c296a07205557b969_20120201 | CNzvnh3VdsIivzr2z8 | 346 |
| CyP6oYOs7782sfNO1 | 310 | |
| 9003a3423d9e3d05d96b4a09d8d64c61_20120131 | CgDZVO1O4jpz7Rz3uj | 292 |
20 rows × 1 columns
filesdf[filesdf['conn_uids'] == 'CVANI54q1eA8PJEPNl'].shape[0]
972
print filesdf[filesdf['conn_uids'] == 'CVANI54q1eA8PJEPNl']['sample'].unique()
print filesdf[filesdf['conn_uids'] == 'C9KyD7n902u8uko9j']['sample'].unique()
[fffa22264e6ebebdfcc3c9526d8bc19c_20130313 2f261ef858fe6ac50d3c1a4f9abf9090_20111108] [fffa22264e6ebebdfcc3c9526d8bc19c_20130313 2f261ef858fe6ac50d3c1a4f9abf9090_20111108]
Guess Bro conn uids weren't as unique as I thought they should be.

Now that we have a good handle on the data and the successes/failurs of AV, what if we could figure out what samples and sessions had "interesting" combinations of file types. Could we build a better driveby detector?
# These are so we can pick up combinations of executable/persistent mime-types along with a mime-type that is frequently
# associated with exploits/drivebys
executable_types = set(['application/x-dosexec', 'application/octet-stream', 'binary', 'application/vnd.ms-cab-compressed'])
common_exploit_types = set(['application/x-java-applet','application/pdf','application/zip','application/jar','application/x-shockwave-flash'])
# If there is at least one executable type and one exploit type in a list of mime-types
def intresting_combo_data(mimetypes):
mt = set(mimetypes.tolist())
et = set()
cet = set()
et = mt.intersection(executable_types)
cet = mt.intersection(common_exploit_types)
if len(et) > 0 and len(cet) > 0:
return ":".join(cet) + ":" + ":".join(et)
if len(et) > 0 and len(cet) == 0:
return ":".join(et)
if len(cet) > 0 and len(et) == 0:
return ":".join(cet)
return "NONE"
def intresting_combo_label(mimetypes):
mt = set(mimetypes.tolist())
et = set()
cet = set()
et = mt.intersection(executable_types)
cet = mt.intersection(common_exploit_types)
if len(et) > 0 and len(cet) > 0:
return "C-c-c-combo"
if len(et) > 0 and len(cet) == 0:
return "Executable only"
if len(cet) > 0 and len(et) == 0:
return "Exploit only"
return "NONE"
# Lookup to see what the Bro - Team Cymru Malware Hash Registry picks up
def tc_mhr_present(sha1):
for h in set(sha1.tolist()):
if h in hashes:
return True
return False
# Get the data in a list (Series) of <sample name> -> <nparray of mime-types>
sample_groups = filesdf.groupby('sample')
s = sample_groups['mime_type'].apply(lambda x: x.unique())
# Rebuild the series into a dataframe and then "collapse" the dataframe with a reset index
sample_combos = pd.DataFrame(s, columns=['mime_types'])
sample_combos['sample'] = s.index
sample_combos['combos_data'] = s.map(intresting_combo_data)
sample_combos['combos_label'] = s.map(intresting_combo_label)
# Add some more columns and reset the index
sample_combos['sha1'] = sample_groups['sha1'].apply(lambda x: x.unique())
sample_combos['num_files'] = sample_groups['sha1'].apply(lambda x: len(x))
sample_combos = sample_combos.reset_index(drop=True)
sample_combos['mhr'] = sample_combos['sha1'].map(tc_mhr_present)
sample_combos.head()
# Now we have a nice "flat" dataframe that for each sample has a list of sha1s associated with it, along with mime-types
# associated with it. Including the list of interesting mime-type combinations and if any of the sha1 hashes were picked up in
# the MHR
| mime_types | sample | combos_data | combos_label | sha1 | num_files | mhr | |
|---|---|---|---|---|---|---|---|
| 0 | [text/html, text/plain, image/jpeg, applicatio... | 00065098d5b9f76f15b7eafadc0fd262_20120531 | application/zip:application/x-dosexec:binary | C-c-c-combo | [faa7c496d19abe7fdb0e46deeac899353a6d29f8, a37... | 84 | True |
| 1 | [text/html, image/png, text/plain, image/jpeg,... | 0009e3e91e87268dfa577f4626072bab_20120615 | application/zip:application/x-dosexec:binary | C-c-c-combo | [7f140fddab21ae35f577f3527aed9933d05b58d3, 32f... | 66 | False |
| 2 | [text/plain, text/html, image/jpeg, image/gif,... | 001d54c3e3f4cb05bc7676c98d70d0ec_20120509 | application/x-shockwave-flash:application/pdf:... | C-c-c-combo | [3e611f6de96f98df23791dc837aa62f0d627a366, 17a... | 350 | True |
| 3 | [text/html, text/plain, application/jar, appli... | 0020e9fc0bf7538cdf75b0308c5a236c_20121230 | application/x-shockwave-flash:application/jar:... | C-c-c-combo | [fad057c5e1022a584646517aa2a4ef2998937490, cda... | 126 | True |
| 4 | [text/html, text/plain, image/gif, application... | 002487431d095f45222491166c16f2ae_20120121 | application/x-shockwave-flash:application/jar:... | C-c-c-combo | [fea5705f0bfa0f45a6dac2dbc8ffa9106a7bc3f4, be0... | 132 | True |
5 rows × 7 columns
With the nice table above we have a sample view of the unique mime-types, unique files, total # of files and if any of those files were detected by the MHR all rolled into once nice package.
Assumption Alert!
In the case of using sample (eg. PCAP) we can treat this as activity from a single host w/o worry about trying to unique out all the information about the sandbox env and it's IPs.
print "Reminder"
print "Total files found: %s" %len(filesdf.index)
print "Total Samples: %s" %len(sample_combos.index)
print "\nData summary"
print sample_combos.combos_label.value_counts()
sample_combos['count'] = 1
sample_combos[['combos_label','combos_data','count']].groupby(['combos_label','combos_data']).sum().sort('count', ascending=0).head(15)
Reminder Total files found: 1100106 Total Samples: 6662 Data summary C-c-c-combo 5410 Executable only 1218 Exploit only 25 NONE 9 dtype: int64
| count | ||
|---|---|---|
| combos_label | combos_data | |
| Executable only | application/x-dosexec | 801 |
| C-c-c-combo | application/jar:application/x-dosexec | 403 |
| application/zip:application/x-dosexec:binary | 361 | |
| application/jar:application/x-dosexec:binary | 352 | |
| Executable only | application/x-dosexec:binary | 305 |
| C-c-c-combo | application/jar:application/pdf:application/x-dosexec:binary | 303 |
| application/zip:application/pdf:application/x-dosexec:binary | 274 | |
| application/zip:application/pdf:application/x-shockwave-flash:application/x-dosexec:binary | 248 | |
| application/zip:application/pdf:application/x-shockwave-flash:application/x-dosexec | 238 | |
| application/x-shockwave-flash:application/x-dosexec | 228 | |
| application/zip:application/x-dosexec | 184 | |
| application/zip:application/x-shockwave-flash:application/x-dosexec:binary | 181 | |
| application/x-shockwave-flash:application/pdf:application/x-dosexec | 172 | |
| application/x-shockwave-flash:application/jar:application/pdf:application/x-dosexec:binary | 171 | |
| application/x-shockwave-flash:application/jar:application/x-dosexec:binary | 168 |
15 rows × 1 columns
(100. * sample_combos.combos_data.value_counts() / len(sample_combos.index)).head(10)
application/x-dosexec 12.023416 application/jar:application/x-dosexec 6.049234 application/zip:application/x-dosexec:binary 5.418793 application/jar:application/x-dosexec:binary 5.283699 application/x-dosexec:binary 4.578205 application/jar:application/pdf:application/x-dosexec:binary 4.548184 application/zip:application/pdf:application/x-dosexec:binary 4.112879 application/zip:application/pdf:application/x-shockwave-flash:application/x-dosexec:binary 3.722606 application/zip:application/pdf:application/x-shockwave-flash:application/x-dosexec 3.572501 application/x-shockwave-flash:application/x-dosexec 3.422396 dtype: float64
# Sorry for the lousy formatting, I really wanted (me) and you to see all the crazy combinations of files in some of these samples.
# Maybe they're multiple malicious sites, or maybe it's just some crazy spray-and-pray happening!
sample_mhr = sample_combos[sample_combos['mhr'] == True]
print "Total Samples: %s" %len(sample_mhr.index)
print
print sample_mhr.combos_label.value_counts()
print
print (100. * sample_mhr.combos_data.value_counts() / len(sample_mhr.index)).head(10)
Total Samples: 2849 C-c-c-combo 2761 Executable only 85 Exploit only 3 dtype: int64 application/jar:application/x-dosexec 9.582310 application/jar:application/pdf:application/x-dosexec:binary 7.230607 application/zip:application/pdf:application/x-shockwave-flash:application/x-dosexec:binary 7.195507 application/zip:application/pdf:application/x-shockwave-flash:application/x-dosexec 6.739207 application/zip:application/x-dosexec:binary 6.598807 application/zip:application/pdf:application/x-dosexec:binary 5.440505 application/jar:application/x-dosexec:binary 5.229905 application/x-shockwave-flash:application/pdf:application/x-dosexec 4.563005 application/x-shockwave-flash:application/pdf:application/x-dosexec:binary 3.580204 application/x-shockwave-flash:application/jar:application/pdf:application/x-dosexec:binary 3.545104 dtype: float64
We've got a great picture at how things could look coming from a host in a "short" amount of itme, wonder what it looks like when it's broken up at the network layer. Let's mimic the layout and some of the analysis from above and see what pops up.
# Get the data in a list (Series) of <sample name> -> <nparray of mime-types>
uid_groups = filesdf.groupby('conn_uids')
s = uid_groups['mime_type'].apply(lambda x: x.unique())
# Rebuild the series into a dataframe and then "collapse" the dataframe with a reset index
uid_combos = pd.DataFrame(s, columns=['mime_types'])
uid_combos['conn_uid'] = s.index
uid_combos['combos_data'] = s.map(intresting_combo_data)
uid_combos['combos_label'] = s.map(intresting_combo_label)
# Same trick, different day
uid_combos['sha1'] = uid_groups['sha1'].apply(lambda x: x.unique())
uid_combos['num_files'] = uid_groups['sha1'].apply(lambda x: len(x))
uid_combos = uid_combos.reset_index(drop=True)
uid_combos = uid_combos[uid_combos['conn_uid'] != '(empty)']
uid_combos['mhr'] = uid_combos['sha1'].map(tc_mhr_present)
uid_combos.head()
# Now we've got the same type of dataframe as above in sample_combos.
| mime_types | conn_uid | combos_data | combos_label | sha1 | num_files | mhr | |
|---|---|---|---|---|---|---|---|
| 1 | [image/png, text/plain] | C000io4MJcSJMUYhmb | NONE | NONE | [d34f84ee29438bba5c353a9d20f3536badb38178, 577... | 32 | False |
| 2 | [image/jpeg] | C001r8hbIKrnTGyHf | NONE | NONE | [74d87f7b1ca35f84cd4f1a08314c2d2b8c2aa763, 59d... | 4 | False |
| 3 | [application/zip] | C002bZ2fhBI7mYwQxf | application/zip | Exploit only | [c17ac3fb131adc485b32bebb3bcad742a0a676d1] | 2 | False |
| 4 | [text/html] | C007502KmyrlCzKHqb | NONE | NONE | [36124e9da41313a4bc3a903abe5fccf0ea9c7736] | 2 | False |
| 5 | [image/gif] | C009392KwetlBZpxC | NONE | NONE | [75e91ae3e549dab12ed1c9787ade9131aef1c981] | 2 | False |
5 rows × 7 columns
# Same deal as above, these 2 make the same tables as the images below
#uid_combos.describe()
#sample_combos.describe()
The tables below were converted to .png files for pretty display, but they're just screen-caps of the above commands
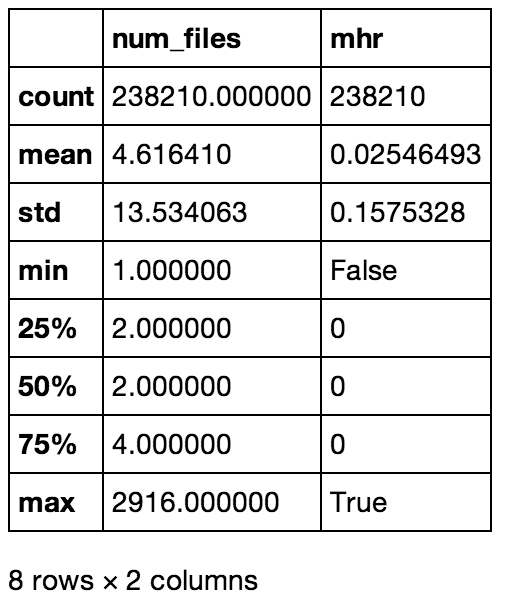 Stats bassed on session (conn_uid)
Stats bassed on session (conn_uid)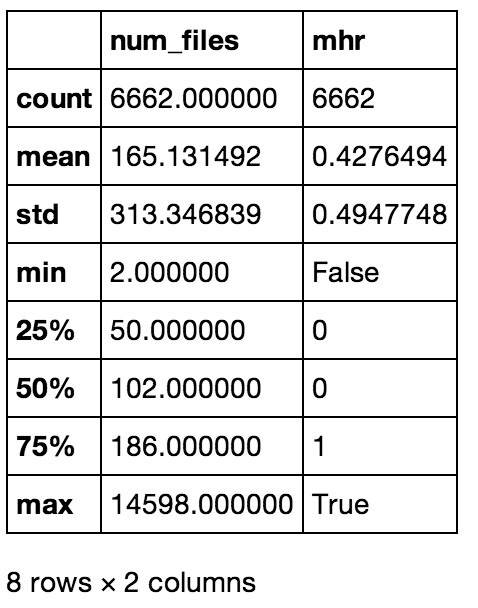 Stats based on sample (sample)
Stats based on sample (sample)df_uid = pd.DataFrame()
df_uid['num_files'] = uid_combos['num_files']
df_uid['label'] = "session"
df_sample = pd.DataFrame()
df_sample['num_files'] = sample_combos['num_files']
df_sample['label'] = "sample"
df = pd.concat([df_sample, df_uid], ignore_index=True)
df.boxplot('num_files','label',vert=False)
plt.pyplot.xlabel('Number of Files, Session v. Sample')
plt.pyplot.ylabel('# of Files')
plt.pyplot.title('Comparision of # Files')
plt.pyplot.suptitle("")
<matplotlib.text.Text at 0x149bf4790>

print "Total connections: %s" %len(uid_combos.index)
#100. * uid_combos.combos.value_counts() / len(uid_combos.index)
uid_combos['count'] = 1
uid_combos[['combos_label','combos_data','count']].groupby(['combos_label','combos_data']).sum().sort('count', ascending=0).head(15)
Total connections: 238210
| count | ||
|---|---|---|
| combos_label | combos_data | |
| NONE | NONE | 198045 |
| Executable only | application/x-dosexec | 10395 |
| binary | 10136 | |
| Exploit only | application/x-shockwave-flash | 6035 |
| application/jar | 3276 | |
| application/zip | 2570 | |
| application/x-java-applet | 1483 | |
| application/pdf | 1398 | |
| C-c-c-combo | application/pdf:application/x-dosexec | 1030 |
| application/jar:application/x-dosexec | 902 | |
| application/zip:application/x-dosexec | 877 | |
| Executable only | application/octet-stream | 862 |
| application/vnd.ms-cab-compressed:binary | 242 | |
| application/vnd.ms-cab-compressed | 198 | |
| C-c-c-combo | application/x-shockwave-flash:application/pdf:application/x-dosexec | 186 |
15 rows × 1 columns
uid_mhr = uid_combos[uid_combos['mhr'] == True]
print "Total connections: %s" %len(uid_mhr.index)
print
print uid_mhr.combos_label.value_counts()
print
100. * uid_mhr.combos_data.value_counts() / len(uid_mhr.index)
Total connections: 6066 Executable only 2998 C-c-c-combo 1748 Exploit only 1320 dtype: int64
application/x-dosexec 49.010880 application/pdf:application/x-dosexec 9.347181 application/jar:application/x-dosexec 9.066930 application/x-shockwave-flash 8.127267 application/jar 6.594131 application/zip:application/x-dosexec 5.637982 application/x-java-applet 4.648863 application/x-shockwave-flash:application/pdf:application/x-dosexec 2.884932 application/pdf 2.176063 application/x-shockwave-flash:application/x-dosexec 1.483680 application/x-dosexec:binary 0.395648 application/pdf:application/x-dosexec:binary 0.263765 application/x-shockwave-flash:application/pdf 0.214309 application/x-shockwave-flash:application/pdf:application/x-dosexec:binary 0.049456 application/jar:binary 0.049456 application/pdf:binary 0.016485 application/x-shockwave-flash:application/pdf:binary 0.016485 application/x-dosexec:application/octet-stream 0.016485 dtype: float64

After a long slog through the data (some interesting, and some ... eh) we've got a few more questions we can answer. We'll stick to just the session view from now on, but these can just as easily be done above via the sample dataframe.
Great, AV was able to detect some things, but what is it missing? Can we find any relationships between what AV missed and what it found?
uid_mhr = uid_combos[uid_combos['mhr'] != True]
print uid_mhr.combos_label.value_counts()
print
uid_mhr[uid_mhr['combos_label'] == 'C-c-c-combo']['combos_data'].value_counts()
NONE 198045 Executable only 18981 Exploit only 13496 C-c-c-combo 1622 dtype: int64
application/zip:application/x-dosexec 535 application/pdf:application/x-dosexec 463 application/jar:application/x-dosexec 352 application/jar:binary 150 application/x-shockwave-flash:application/x-dosexec 35 application/x-shockwave-flash:binary 33 application/pdf:binary 26 application/x-shockwave-flash:application/pdf:application/x-dosexec 11 application/zip:binary 4 application/zip:application/jar:application/x-dosexec 4 application/x-shockwave-flash:application/octet-stream 3 application/pdf:application/x-dosexec:binary 3 application/x-shockwave-flash:application/x-dosexec:binary 1 application/zip:application/jar:binary 1 application/x-java-applet:application/x-dosexec 1 dtype: int64
combos = uid_combos[uid_combos['combos_label'] == 'C-c-c-combo'].shape[0]
print "% of MHR hits in sessions with an \"interesting\" file combination"
print uid_combos[uid_combos['combos_label'] == 'C-c-c-combo']['mhr'].value_counts().apply(lambda x: x/combos)
print "\n% of MHR hits from samples (end systems) with an \"interesting\" file combination"
combos = sample_combos[sample_combos['combos_label'] == 'C-c-c-combo'].shape[0]
print sample_combos[sample_combos['combos_label'] == 'C-c-c-combo']['mhr'].value_counts().apply(lambda x: x/combos)
% of MHR hits in sessions with an "interesting" file combination True 0.518694 False 0.481306 dtype: float64 % of MHR hits from samples (end systems) with an "interesting" file combination True 0.510351 False 0.489649 dtype: float64

Wait, what!?
Did we just figure out that (according to our samples) that if you're relying on AV to detect bad files instead of looking for a super easy pattern in network traffic you're missing out on 1/2 of the possible malware driveby downloads. Granted this requires an "interesting" file combination be present in both the same session or from the same source host, but wow.
Assumption Alert!
Again, we believe this data to be composed of mostly driveby downloads, so we're only looking at labels within a known-malicous set. Looking for those interesting file combinations on the network may yield additional false-positives.
Closing
We were able to successfully dissect properties of files that traverse the network. Based on the properties the effectiveness of current solutions, proposed patterns to look for new and "un-known" attacks were discovered! Never underestimate the value of having better data. With this set, some insights were gained, but if the data came pre-labeled or we knew more about how it was collected perhaps we'd have more or different assumptions and gotten different results.