xkcd 1313: Regex Golf (Part 2: Infinite Problems)¶
Peter Norvig
with Stefan Pochmann
Feb 2014
revised Nov 2015

This Again?¶
Last month I demonstrated a simple Regex Golf program. I thought that was the end of the topic, but Stefan Pochmann sent me a series of emails suggesting some impressive improvements. (Davide Canton and Thomas Breuel also had good suggestions.) So this post is an exploration of some of Stefan's new ideas, and some of my own. It's a story about regex golf, and about using exploratory programming to test out ideas.
To review, here's the program from part 1, with some minor modifications:
%matplotlib inline
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from __future__ import division, print_function
from collections import Counter, defaultdict
import re
import itertools
import random
Set = frozenset # Data will be frozensets, so they can't be mutated.
def words(text):
"All space-separated words in text."
return Set(text.split())
def phrases(text, sep='/'):
"All sep-separated phrases in text, uppercased and stripped."
return Set(p.upper().strip() for p in text.split(sep))
def mistakes(regex, winners, losers):
"The set of mistakes made by this regex in classifying winners and losers."
return ({"Should have matched: " + W
for W in winners if not re.search(regex, W)} |
{"Should not have matched: " + L
for L in losers if re.search(regex, L)})
def findregex(winners, losers, k=4):
"Find a regex that matches all winners but no losers (sets of strings)."
# Make a pool of regex parts, then pick from them to cover winners.
# On each iteration, add the 'best' part to 'solution',
# remove winners covered by best, and keep in 'pool' only parts
# that still match some winner.
pool = regex_parts(winners, losers)
solution = []
def score(p): return k * len(matches(p, winners)) - len(p)
while winners:
best = max(pool, key=score)
solution.append(best)
winners = winners - matches(best, winners)
pool = {p for p in pool if matches(p, winners)}
return OR(solution)
def matches(regex, strings):
"Return a set of all the strings that are matched by regex."
return {s for s in strings if re.search(regex, s)}
OR = '|'.join # Join a sequence of strings with '|' between them
cat = ''.join # Join a sequence of strings with nothing between them
def regex_parts(winners, losers):
"Return parts that match at least one winner, but no loser."
wholes = {'^' + w + '$' for w in winners}
parts = {d for w in wholes for p in subparts(w) for d in dotify(p)}
return wholes | {p for p in parts if not matches(p, losers)}
def subparts(word):
"Return a set of subparts of word: consecutive characters up to length 4."
return set(word[i:i+n] for i in range(len(word)) for n in (1, 2, 3, 4))
def dotify(part):
"Return all ways to replace a subset of chars in part with '.'."
choices = map(replacements, part)
return {cat(chars) for chars in itertools.product(*choices)}
def replacements(c):
"All ways to replace character c with something interesting: for now, 'c' or '.'."
return c if c in '^$' else c + '.'
def report(winners, losers):
"Find a regex to match A but not B, and vice-versa. Print summary."
solution = findregex(winners, losers)
assert not mistakes(solution, winners, losers)
print('Chars: {}, ratio: {:.1f}, inputs: {}:{}'.format(
len(solution), len(trivial(winners)) / len(solution) , len(winners), len(losers)))
return solution
def trivial(winners): return '^(' + OR(winners) + ')$'
Here are some "arbitrary lists" (see panel two of the comic) which we will be using to test out the code.
winners = words('''washington adams jefferson jefferson madison madison monroe
monroe adams jackson jackson van-buren harrison polk taylor pierce buchanan
lincoln lincoln grant grant hayes garfield cleveland harrison cleveland mckinley
mckinley roosevelt taft wilson wilson harding coolidge hoover roosevelt
roosevelt roosevelt roosevelt truman eisenhower eisenhower kennedy johnson nixon
nixon carter reagan reagan bush clinton clinton bush bush obama obama''')
losers = words('''clinton jefferson adams pinckney pinckney clinton king adams
jackson adams clay van-buren van-buren clay cass scott fremont breckinridge
mcclellan seymour greeley tilden hancock blaine cleveland harrison bryan bryan
parker bryan roosevelt hughes cox davis smith hoover landon wilkie dewey dewey
stevenson stevenson nixon goldwater humphrey mcgovern ford carter mondale
dukakis bush dole gore kerry mccain romney''') - winners
boys = words('jacob mason ethan noah william liam jayden michael alexander aiden')
girls = words('sophia emma isabella olivia ava emily abigail mia madison elizabeth')
pharma = words('lipitor nexium plavix advair ablify seroquel singulair crestor actos epogen')
cities = words('paris trinidad capetown riga zurich shanghai vancouver chicago adelaide auckland')
foo = words('''afoot catfoot dogfoot fanfoot foody foolery foolish fooster footage foothot footle footpad footway
hotfoot jawfoot mafoo nonfood padfoot prefool sfoot unfool''')
bar = words('''Atlas Aymoro Iberic Mahran Ormazd Silipan altared chandoo crenel crooked fardo folksy forest
hebamic idgah manlike marly palazzi sixfold tarrock unfold''')
nouns = words('''time year people way day man thing woman life child world school
state family student group country problem hand part place case week company
system program question work government number night point home water room
mother area money story fact month lot right study book eye job word business
issue side kind head house service friend father power hour game line end member
law car city community name president team minute idea kid body information
back parent face others level office door health person art war history party result
change morning reason research girl guy moment air teacher force education''')
adverbs = words('''all particularly just less indeed over soon course still yet before
certainly how actually better to finally pretty then around very early nearly now
always either where right often hard back home best out even away enough probably
ever recently never however here quite alone both about ok ahead of usually already
suddenly down simply long directly little fast there only least quickly much forward
today more on exactly else up sometimes eventually almost thus tonight as in close
clearly again no perhaps that when also instead really most why ago off
especially maybe later well together rather so far once''') - nouns
verbs = words('''ask believe borrow break bring buy can be able cancel change clean
comb complain cough count cut dance draw drink drive eat explain fall
fill find finish fit fix fly forget give go have hear hurt know learn
leave listen live look lose make do need open close shut organise pay
play put rain read reply run say see sell send sign sing sit sleep
smoke speak spell spend stand start begin study succeed swim take talk
teach tell think translate travel try turn off turn on type understand
use wait wake up want watch work worry write''') - nouns
randoms = Set(vars(random))
builtins = Set(vars(__builtin__)) - randoms
starwars = phrases('''The Phantom Menace / Attack of the Clones / Revenge of the Sith /
A New Hope / The Empire Strikes Back / Return of the Jedi''')
startrek = phrases('''The Wrath of Khan / The Search for Spock / The Voyage Home /
The Final Frontier / The Undiscovered Country / Generations / First Contact /
Insurrection / Nemesis''')
dogs = phrases(''''Labrador Retrievers / German Shepherd Dogs / Golden Retrievers / Beagles / Bulldogs /
Yorkshire Terriers / Boxers / Poodles / Rottweilers / Dachshunds / Shih Tzu / Doberman Pinschers /
Miniature Schnauzers / French Bulldogs / German Shorthaired Pointers / Siberian Huskies / Great Danes /
Chihuahuas / Pomeranians / Cavalier King Charles Spaniels / Shetland Sheepdogs / Australian Shepherds /
Boston Terriers / Pembroke Welsh Corgis / Maltese / Mastiffs / Cocker Spaniels / Havanese /
English Springer Spaniels / Pugs / Brittanys / Weimaraners / Bernese Mountain Dogs / Vizslas / Collies /
West Highland White Terriers / Papillons / Bichons Frises / Bullmastiffs / Basset Hounds /
Rhodesian Ridgebacks / Newfoundlands / Russell Terriers / Border Collies / Akitas /
Chesapeake Bay Retrievers / Miniature Pinschers / Bloodhounds / St. Bernards / Shiba Inu / Bull Terriers /
Chinese Shar-Pei / Soft Coated Wheaten Terriers / Airedale Terriers / Portuguese Water Dogs / Whippets /
Alaskan Malamutes / Scottish Terriers / Australian Cattle Dogs / Cane Corso / Lhasa Apsos /
Chinese Crested / Cairn Terriers / English Cocker Spaniels / Dalmatians / Italian Greyhounds /
Dogues de Bordeaux / Samoyeds / Chow Chows / German Wirehaired Pointers / Belgian Malinois /
Great Pyrenees / Pekingese / Irish Setters / Cardigan Welsh Corgis / Staffordshire Bull Terriers /
Irish Wolfhounds / Old English Sheepdogs / American Staffordshire Terriers / Bouviers des Flandres /
Greater Swiss Mountain Dogs / Japanese Chin / Tibetan Terriers / Brussels Griffons /
Wirehaired Pointing Griffons / Border Terriers / English Setters / Basenjis / Standard Schnauzers /
Silky Terriers / Flat-Coated Retrievers / Norwich Terriers / Afghan Hounds / Giant Schnauzers / Borzois /
Wire Fox Terriers / Parson Russell Terriers / Schipperkes / Gordon Setters / Treeing Walker Coonhounds''')
cats = phrases('''Abyssinian / Aegean cat / Australian Mist / American Curl / American Bobtail /
American Polydactyl / American Shorthair / American Wirehair / Arabian Mau / Asian / Asian Semi-longhair /
Balinese / Bambino / Bengal / Birman / Bombay / Brazilian Shorthair / British Shorthair / British Longhair /
Burmese / Burmilla / California Spangled Cat / Chantilly/Tiffany / Chartreux / Chausie / Cheetoh /
Colorpoint Shorthair / Cornish Rex / Cymric / Cyprus cat / Devon Rex / Donskoy or Don Sphynx / Dragon Li /
Dwelf / Egyptian Mau / European Shorthair / Exotic Shorthair / German Rex / Havana Brown / Highlander /
Himalayan-Colorpoint Persian / Japanese Bobtail / Javanese / Khao Manee / Korat / Korn Ja /
Kurilian Bobtail / LaPerm / Maine Coon / Manx / Mekong bobtail / Minskin / Munchkin / Nebelung / Napoleon /
Norwegian Forest Cat / Ocicat / Ojos Azules / Oregon Rex / Oriental Bicolor / Oriental Shorthair /
Oriental Longhair / Persian / Peterbald / Pixie-bob / Ragamuffin / Ragdoll / Russian Blue / Russian Black /
Sam Sawet / Savannah / Scottish Fold / Selkirk Rex / Serengeti cat / Serrade petit / Siamese / Siberian /
Singapura / Snowshoe / Sokoke / Somali / Sphynx / Swedish forest cat / Thai / Tonkinese / Toyger /
Turkish Angora / Turkish Van / Ukrainian Levkoy / York Chocolate Cat''')
movies = phrases('''Citizen Kane / The Godfather / Vertigo / 2001: A Space Odyssey / The Searchers / Sunrise /
Singin’ in the Rain / Psycho / Casablanca / The Godfather Part II / The Magnificent Ambersons / Chinatown /
North by Northwest / Nashville / The Best Years of Our Lives / McCabe & Mrs Miller / The Gold Rush /
City Lights / Taxi Driver / Goodfellas / Mulholland Drive / Greed / Annie Hall / The Apartment /
Do the Right Thing / Killer of Sheep / Barry Lyndon / Pulp Fiction / Raging Bull / Some Like It Hot /
A Woman Under the Influence / The Lady Eve / The Conversation / The Wizard of Oz / Double Indemnity /
Star Wars / Imitation of Life / Jaws / The Birth of a Nation / Meshes of the Afternoon / Rio Bravo /
Dr Strangelove / Letter from an Unknown Woman / Sherlock Jr / The Man Who Shot Liberty Valance /
It’s a Wonderful Life / Marnie / A Place in the Sun / Days of Heaven / His Girl Friday / Touch of Evil /
The Wild Bunch / Grey Gardens / Sunset Boulevard / The Graduate / Back to the Future / Crimes and Misdemeanors /
The Shop Around the Corner / One Flew Over the Cuckoo’s Nest / Blue Velvet / Eyes Wide Shut / The Shining /
Love Streams / Johnny Guitar / The Right Stuff / Red River / Modern Times / Notorious / Koyaanisqatsi /
The Band Wagon / Groundhog Day / The Shanghai Gesture / Network / Forrest Gump /
Close Encounters of the Third Kind / The Empire Strikes Back / Stagecoach / Schindler’s List /
The Tree of Life / Meet Me in St Louis / Thelma & Louise / Raiders of the Lost Ark / Bringing Up Baby /
Deliverance / Night of the Living Dead / The Lion King / Eternal Sunshine of the Spotless Mind /
West Side Story / In a Lonely Place / Apocalypse Now / ET: The Extra-Terrestrial / The Night of the Hunter /
Mean Streets / 25th Hour / Duck Soup / The Dark Knight / Gone With the Wind / Heaven’s Gate / 12 Years a Slave /
Ace in the Hole''')
tv = phrases('''The Abbott and Costello Show / ABC’s Wide World of Sports / Alfred Hitchcock Presents /
All in the Family / An American Family / American Idol / Arrested Development / Battlestar Galactica /
The Beavis and Butt-Head Show / The Bob Newhart Show / Brideshead Revisited / Buffalo Bill /
Buffy the Vampire Slayer / The Carol Burnett Show / The CBS Evening News with Walter Cronkite /
A Charlie Brown Christmas / Cheers / The Cosby Show / The Daily Show / Dallas / The Day After /
Deadwood / The Dick Van Dyke Show / Dragnet / The Ed Sullivan Show / The Ernie Kovacs Show /
Felicity / Freaks and Geeks / The French Chef / Friends / General Hospital /
The George Burns and Gracie Allen Show / Gilmore Girls / Gunsmoke / Hill Street Blues /
Homicide: Life on the Street / The Honeymooners / I, Claudius / I Love Lucy / King of the Hill /
The Larry Sanders Show / Late Night with David Letterman / Leave It to Beaver / Lost /
Married with Children / Mary Hartman, Mary Hartman / The Mary Tyler Moore Show / MASH / The Monkees /
Monty Python’s Flying Circus / Moonlighting / My So-Called Life / Mystery Science Theater 3000 /
The Odd Couple / The Office / The Oprah Winfrey Show / Pee Wee’s Playhouse / Playhouse 90 /
The Price Is Right / Prime Suspect / The Prisoner / The Real World / Rocky and His Friends / Roots /
Roseanne / Sanford and Son / Saturday Night Live / Second City Television / See It Now / Seinfeld /
Sesame Street / Sex and the City / The Shield / The Simpsons / The Singing Detective / Six Feet Under /
60 Minutes / Soap / The Sopranos / South Park / SpongeBob SquarePants / SportsCenter / Star Trek /
St Elsewhere / The Super Bowl / Survivor / Taxi /The Tonight Show Starring Johnny Carson /
24 / The Twilight Zone / Twin Peaks / The West Wing / What’s My Line / WKRP in Cincinnati /
The Wire / Wiseguy / The X-Files''')
stars = phrases('''Humphrey Bogart / Cary Grant / James Stewart / Marlon Brando / Fred Astaire / Henry Fonda /
Clark Gable / James Cagney / Spencer Tracy / Charlie Chaplin / Gary Cooper / Gregory Peck / John Wayne /
Laurence Olivier / Gene Kelly / Orson Welles / Kirk Douglas / James Dean / Burt Lancaster / Marx Brothers /
Buster Keaton / Sidney Poitier / Robert Mitchum / Edward G. Robinson / William Holden / Katharine Hepburn /
Bette Davis / Audrey Hepburn / Ingrid Bergman / Greta Garbo / Marilyn Monroe / Elizabeth Taylor / Judy Garland /
Marlene Dietrich / Joan Crawford / Barbara Stanwyck / Claudette Colbert / Grace Kelly / Ginger Rogers /
Mae West / Vivien Leigh / Lillian Gish / Shirley Temple / Rita Hayworth / Lauren Bacall / Sophia Loren /
Jean Harlow / Carole Lombard / Mary Pickford / Ava Gardner''')
scientists = phrases('''Alain Aspect / Martin Karplus / David Baltimore / Donald Knuth / Allen Bard /
Robert Marks II / Timothy Berners-Lee / Craig Mello / John Tyler Bonner / Luc Montagnier / Dennis Bray /
Gordon Moore / Sydney Brenner / Kary Mullis / Pierre Chambon / C Nüsslein-Volhard / Simon Conway Morris /
Seiji Ogawa / Mildred Dresselhaus / Jeremiah Ostriker / Gerald M Edelman / Roger Penrose / Ronald Evans /
Stanley Prusiner / Anthony Fauci / Henry F Schaefer III / Anthony Fire / Thomas Südhof / Jean Frechet /
Jack Szostak / Margaret Geller / James Tour / Jane Goodall / Charles Townes / Alan Guth / Harold Varmus /
Lene Vestergaard Hau / Craig Venter / Stephen Hawking / James Watson / Peter Higgs / Steven Weinberg /
Leroy Hood / George Whitesides / Eric Kandel / Edward Wilson / Andrew Knoll / Edward Witten / Charles Kao /
Shinya Yamanaka''')
And here we show how it works:
solution = findregex(starwars, startrek)
solution
' T|E.P|EW'
not mistakes(solution, starwars, startrek)
True
Plan of Attack¶
To improve the program, I'll take the following steps:
- Profiling: Figure out where the program spends its time.
- Speedup: Make the program faster.
- Benchmarking: Run the program over pairs of arbitrary lists to see how fast it is and how short the solutions are.
- Analyzing: Learn something by looking at the benchmark results.
- Searching: Introduce a better search algorithm.
- Eliminating Parts: Get rid of parts that can't possibly be part of an optimal solution.
- Adding Parts: Add new types of parts to allow new, shorter solutions.
- Randomizing Search: Randomness allows us to explore different parts of the search space.
- Speculating: Think about what we could do next.
Profiling¶
Let's time how long it takes to separate the top 100 adverbs from top 100 nouns:
%timeit findregex(adverbs, nouns)
1 loops, best of 3: 4.16 s per loop
On my computer it was 4 seconds. I have some ideas for how to make this faster, but I know that I shouldn't waste effort trying to speed up parts of a program that don't take much of the total time. I'll use the cProfile module to see where the time goes:
import cProfile
cProfile.run('findregex(adverbs, nouns)', sort='cumulative')
12212651 function calls in 6.768 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 6.768 6.768 {built-in method builtins.exec}
1 0.000 0.000 6.768 6.768 <string>:1(<module>)
1 0.001 0.001 6.768 6.768 <ipython-input-2-f5df3c47a125>:24(findregex)
54140 0.040 0.000 6.681 0.000 <ipython-input-2-f5df3c47a125>:40(matches)
54140 0.893 0.000 6.641 0.000 <ipython-input-2-f5df3c47a125>:42(<setcomp>)
2839292 1.286 0.000 5.748 0.000 re.py:170(search)
2839292 1.248 0.000 3.577 0.000 re.py:278(_compile)
41 0.015 0.000 3.121 0.076 {built-in method builtins.max}
25303 0.029 0.000 3.106 0.000 <ipython-input-2-f5df3c47a125>:32(score)
41 0.018 0.000 2.927 0.071 <ipython-input-2-f5df3c47a125>:37(<setcomp>)
45055 0.199 0.000 2.255 0.000 sre_compile.py:531(compile)
45055 0.151 0.000 1.098 0.000 sre_parse.py:819(parse)
2839292 0.884 0.000 0.884 0.000 {method 'search' of '_sre.SRE_Pattern' objects}
45055 0.078 0.000 0.852 0.000 sre_compile.py:516(_code)
45055 0.093 0.000 0.756 0.000 sre_parse.py:429(_parse_sub)
1 0.000 0.000 0.717 0.717 <ipython-input-2-f5df3c47a125>:47(regex_parts)
1 0.003 0.003 0.702 0.702 <ipython-input-2-f5df3c47a125>:51(<setcomp>)
45055 0.266 0.000 0.604 0.000 sre_compile.py:412(_compile_info)
45055 0.257 0.000 0.604 0.000 sre_parse.py:491(_parse)
172960 0.076 0.000 0.219 0.000 sre_parse.py:247(get)
218015 0.175 0.000 0.175 0.000 sre_parse.py:226(__next)
45055 0.138 0.000 0.168 0.000 sre_parse.py:167(getwidth)
45055 0.131 0.000 0.165 0.000 sre_compile.py:64(_compile)
917011 0.117 0.000 0.117 0.000 {method 'append' of 'list' objects}
45055 0.065 0.000 0.104 0.000 sre_parse.py:217(__init__)
172960 0.064 0.000 0.087 0.000 sre_parse.py:165(append)
28913 0.069 0.000 0.074 0.000 sre_compile.py:391(_generate_overlap_table)
574321 0.058 0.000 0.058 0.000 {built-in method builtins.len}
90110 0.041 0.000 0.055 0.000 sre_compile.py:513(isstring)
45055 0.042 0.000 0.049 0.000 sre_parse.py:797(fix_flags)
90110 0.033 0.000 0.042 0.000 sre_parse.py:75(groups)
135163 0.041 0.000 0.041 0.000 {built-in method builtins.min}
225275 0.040 0.000 0.040 0.000 {built-in method builtins.isinstance}
45055 0.039 0.000 0.039 0.000 sre_parse.py:70(__init__)
45055 0.034 0.000 0.034 0.000 {built-in method _sre.compile}
45055 0.025 0.000 0.030 0.000 sre_parse.py:276(tell)
45055 0.029 0.000 0.029 0.000 sre_parse.py:105(__init__)
88 0.025 0.000 0.025 0.000 {method 'clear' of 'dict' objects}
1 0.003 0.003 0.015 0.015 <ipython-input-2-f5df3c47a125>:50(<setcomp>)
57828 0.015 0.000 0.015 0.000 {method 'extend' of 'list' objects}
45055 0.014 0.000 0.014 0.000 sre_parse.py:242(match)
119495 0.013 0.000 0.013 0.000 {built-in method builtins.ord}
2131 0.005 0.000 0.011 0.000 <ipython-input-2-f5df3c47a125>:57(dotify)
45055 0.005 0.000 0.005 0.000 {method 'items' of 'dict' objects}
2131 0.003 0.000 0.005 0.000 <ipython-input-2-f5df3c47a125>:60(<setcomp>)
14683 0.003 0.000 0.003 0.000 {method 'get' of 'dict' objects}
11135 0.002 0.000 0.002 0.000 {method 'join' of 'str' objects}
98 0.001 0.000 0.002 0.000 <ipython-input-2-f5df3c47a125>:53(subparts)
4921 0.001 0.000 0.001 0.000 <ipython-input-2-f5df3c47a125>:62(replacements)
2874 0.001 0.000 0.001 0.000 <ipython-input-2-f5df3c47a125>:55(<genexpr>)
1 0.000 0.000 0.000 0.000 <ipython-input-2-f5df3c47a125>:49(<setcomp>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
About 99% of the time was spent in matches. And most of the time in matches goes to re.search. So my thoughts are:
- Can we make each call to
matchesrun faster? - Can we make fewer calls to
matches? - Can we use
re.searchmore effectively? - Nothing else matters. 99% of the time is in
matches; don't waste effort speeding up anything else.
Speedup: Faster matches by Compiling Regexes¶
The re package uses strings to specify regular expressions, but internally, when we call re.search on a string, that string is compiled, with the function re.compile, into an object that has a search method. If you need to search many times with the same regex, then it is faster to call re.compile once, and then call the search method of the compiled object, rather than calling re.search each time.
Another trick: use the builtin function filter rather than a set comprehension. Builtins, written in C, are often faster.
def matches(regex, strings):
"Return a set of all the strings that are matched by regex."
searcher = re.compile(regex).search
return set(filter(searcher, strings))
One thing to be careful about: the re module manages a cache of recent compilations. I call re.purge() before each timing, to make sure that I'm not re-using any work that was done before the timing started.
re.purge()
%timeit findregex(adverbs, nouns)
1 loops, best of 3: 2.25 s per loop
That was almost twice as fast! Not bad for changing two lines.
Speedup: Fewer matches Against Losers¶
In regex_parts, for each part, p, we test if not matches(p, losers). This applies searcher to every loser and builds up a set of all those that match. It would be faster if we could exit early: as soon as we find one loser that matches, we don't need to apply searcher to the remaining losers. Stefan Pochmann came up with a great way to do this. If we concatenate the list of losers together into one big string, then we only need one call to re.search for each part p. If a part matches the big string anywhere, the call will return immediately, and we will know the part is no good.
There is one catch: we have to make sure that the start of each loser matches '^' and the end matches '$'. We can do that by concatenating together the losers with a newline between them, and by using the re.MULTILINE option. (See the re module documentation if this is unfamiliar.)
Here is the change, with timing before and after:
re.purge()
%timeit regex_parts(adverbs, nouns)
1 loops, best of 3: 212 ms per loop
def regex_parts(winners, losers):
"Return parts that match at least one winner, but no loser."
losers_str = '\n'.join(losers)
def no_losers(part): return not re.compile(part, re.MULTILINE).search(losers_str)
wholes = {'^' + w + '$' for w in winners}
parts = {d for w in wholes for p in subparts(w) for d in dotify(p)}
return wholes | set(filter(no_losers, parts))
re.purge()
%timeit regex_parts(adverbs, nouns)
10 loops, best of 3: 127 ms per loop
We've made regex_parts almost two times faster.
Speedup: Fewer matches Against Winners¶
Here's what findregex currently looks like:
def findregex(winners, losers, k=4):
"Find a regex that matches all winners but no losers (sets of strings)."
# Make a pool of regex parts, then pick from them to cover winners.
# On each iteration, add the 'best' part to 'solution',
# remove winners covered by best, and keep in 'pool' only parts
# that still match some winner.
pool = regex_parts(winners, losers)
solution = []
def score(p): return k * len(matches(p, winners)) - len(p)
while winners:
best = max(pool, key=score)
solution.append(best)
winners = winners - matches(best, winners)
pool = {p for p in pool if matches(p, winners)}
return OR(solution)
Notice that we call matches twice (once within score) for every part in the pool on every iteration of the main loop. If there are 50 iterations of the loop, and 1000 parts, that's 100,000 calls to matches. Instead of repeating all these calls, I propose that, for each part in the pool, we limit ourselves to this:
- One
re.compile. - One
re.searchagainst each of the winners. - One
re.searchagainst the big string of losers. - Some cache lookups as needed.
During initialization, we create a dict, called covers, that will serve as a cache: covers[p] is the set of all winners that match the part p. The new function regex_covers replaces the old function regex_parts. Here is the new findregex, with timing before and after:
re.purge()
%timeit findregex(adverbs, nouns)
1 loops, best of 3: 2.19 s per loop
def findregex(winners, losers, k=4):
"Find a regex that matches all winners but no losers (sets of strings)."
# Initialize covers = {regex: {winner,...}} for a large set of regex components.
# On each iteration, add the 'best' component to 'solution',
# remove winners covered by best, and keep in 'pool' only components
# that still match some winner.
covers = regex_covers(winners, losers)
pool = list(covers)
solution = []
def score(p): return k * len(covers[p] & winners) - len(p)
while winners:
best = max(pool, key=score)
solution.append(best)
winners = winners - covers[best]
pool = [p for p in pool
if not covers[p].isdisjoint(winners)]
return OR(solution)
def regex_covers(winners, losers):
"""Generate regex parts and return a dict of {regex: {winner,...}}.
Each regex matches at least one winner and no loser."""
losers_str = '\n'.join(losers)
wholes = {'^' + w + '$' for w in winners}
parts = {d for w in wholes for p in subparts(w) for d in dotify(p)}
pool = wholes | parts
searchers = {p: re.compile(p, re.MULTILINE).search for p in pool}
return {p: Set(filter(searchers[p], winners))
for p in pool
if not searchers[p](losers_str)}
re.purge()
%timeit findregex(adverbs, nouns)
10 loops, best of 3: 198 ms per loop
Wow! That's a dozen times faster! But I don't want to draw too many conclusions from just this one example.
Benchmarking¶
We will benchmark the program on a suite of 22 different problems (11 examples, run in both directions). The function benchmark finds a solution to each problem and prints the number of characters in the solution, and some other information. In the end it prints the total number of characters, and if we use the %time magic, we can see how long it took.
EXAMPLES = [ex for example in [
(winners, 'win', 'lose', losers),
(boys, 'boy', 'girl', girls),
(pharma, 'drug', 'city', cities),
(foo, 'foo', 'bar', bar),
(starwars, 'wars', 'trek', startrek),
(nouns, 'noun', 'adj', adverbs),
(nouns, 'noun', 'verb', verbs),
(randoms, 'rand', 'built', builtins),
(dogs, 'dog', 'cat', cats),
(movies, 'movie', 'tv', tv),
(scientists, 'sci', 'star', stars)]
for ex in (example, example[::-1])] # Do each example both ways
SOLUTION = {} # A cached table of solutions; SOLUTION[W, L] will hold a regex
def benchmark(examples=EXAMPLES):
"Run examples; print summaries; return total of solution lengths."
totalchars = 0
for (W, Wname, Lname, L) in examples:
re.purge()
solution = SOLUTION[W, L] = findregex(W, L)
assert not mistakes(solution, W, L)
legend = '{}({}):{}({})'.format(Wname, len(W), Lname, len(L))
print('{:20} {:3}: "{}"'.format(legend, len(solution), truncate(solution, 50)))
totalchars += len(solution)
print('Total characters: {:6}'.format(totalchars))
return totalchars
def truncate(text, nchars, ellipsis=' ...'):
"Return whole string, or version truncated to nchars."
return text if len(text) < nchars else text[:nchars-len(ellipsis)] + ellipsis
%time benchmark()
win(34):lose(34) 54: "a.a|i..n|j|li|a.t|a..i|bu|oo|ay.|n.e|r.e$|ls|t ..." lose(34):win(34) 60: "^d|^s|r.$|^.re|cc|hu|n.y|o.d|l.i|an.o|ya|ox|ti ..." boy(10):girl(10) 11: "a.$|e.$|a.o" girl(10):boy(10) 10: "a$|^..i|ad" drug(10):city(10) 15: "o.$|x|ir|q|b|en" city(10):drug(10) 11: "ri|an|ca|e$" foo(21):bar(21) 3: "f.o" bar(21):foo(21) 28: "r..$|k|.m|i...|la|c..n|or|ld" wars(6):trek(9) 9: " T|E.P|A " trek(9):wars(6) 14: "ER|N$|F.R|Y|^N" noun(100):adj(98) 171: "m.n|a.e$|m$|in.$|en.$|ch.|^w.r|id|^g|io|s.n|o. ..." adj(98):noun(100) 152: "a.l|^..$|st$|et|re$|tl|en$|^al|ver$|nl|^a.o|ui ..." noun(100):verb(94) 173: "m.n|er$|am|es|^.ar|ho|.on|or.$|id|o.l|f.c|..h. ..." verb(94):noun(100) 175: "^..l|ak|v.$|s..n|^..$|in$|^fi|.pe|ut$|^tr|o.g| ..." rand(58):built(147) 74: "ia|and|^_.e|_s|_.o|.G|e_|P.$|_e|ets|lti|a..s|c ..." built(147):rand(58) 141: "ro|Wa|as|^i|^d|r..i|^o|li|m..$|a.s$|te.$|up|a. ..." dog(100):cat(91) 73: "E.S$|O.S$|DS|.AS|.HI|RD|.D.E|NS$|G.S|IES|N.S$| ..." cat(91):dog(100) 113: "AI.$|T$|AN$|EX|KO|L$|A..B|Y$|A$|M.I|NX|R$|H$|L ..." movie(100):tv(97) 160: "GO| . |^N|HIN|S O|NC.$|I.$|EM|U.K|RIV|ARD|TIO| ..." tv(97):movie(100) 152: "H.W|.CI|PR|R..$|D .E|IL.$|PE|^RO|.MO|^SE|T.C|D ..." sci(50):star(50) 70: "AL..|T..N|R.S|.KA|NN|VE|-|OS|^P|OD|MU|W.I|L.O| ..." star(50):sci(50) 76: "CA|T. |F..D|LI..|BU|LY| GA|LO.| R|UM|GR| ST|I. ..." Total characters: 1745 CPU times: user 4.83 s, sys: 45.1 ms, total: 4.87 s Wall time: 4.92 s
1745
In 5 seconds we solved 22 problems, getting a score of 1749 for the total number of characters in all the solutions.
(Note: if you run this, you might get a slightly different answer. Why? The algorithm has no random parts in it; shouldn't it return the same result every time? It will return the same results if you run it twice in the same Python. But when findregex evaluates max(pool, key=score) and two components are tied for the best score, Python chooses the one that comes first in the iteration of pool. And different versions of Python can iterate over pool in different orders.)
Analyzing¶
What can we do to understand the program better? Let's start by analyzing what the regex parts look like. We cached the solutions in SOLUTION, and we can start to examine the solutions and the parts they are made of. For example, how long are the parts that appears in solutions?
parts = [p for regex in SOLUTION.values() for p in regex.split('|')]
lengths = [len(p) for p in parts]
Counter(lengths)
Counter({1: 17, 2: 191, 3: 179, 4: 85, 7: 1, 10: 1})
This says that there are 17 parts of length 1, 198 parts of length 2, etc. There's also one part of length 10; that's such an outlier, I wonder if it is an error?
max(parts, key=len)
'^HAVANESE$'
I happen to own a Havanese, but I don't think the program knew that. Rather, the issue is that in the set of cats we have 'HAVANA BROWN' and 'JAVANESE', which means that any 4-letter-or-less subsequence of 'HAVANESE' matches one of these two. So the only component that doesn't match one of these two cats is the whole, '^HAVANESE$'.
What about the individual characters that make up the parts? Which ones are popular? We can see:
Counter(cat(parts)).most_common(20)
[('.', 197),
('$', 79),
('a', 68),
('r', 49),
('^', 47),
('o', 47),
('t', 41),
('e', 41),
('i', 36),
('n', 35),
('A', 34),
('l', 33),
('E', 29),
('R', 28),
('O', 27),
('s', 27),
('N', 26),
('S', 24),
('I', 24),
(' ', 23)]
I wonder if there are parts that appear in many solutions?
Counter(parts).most_common(20)
[('hu', 3),
('po', 3),
('oo', 2),
('lt', 2),
('j', 2),
('a.t', 2),
('ls', 2),
('rc', 2),
('an', 2),
('a.a', 2),
('li', 2),
('at$', 2),
('f$', 2),
('ut$', 2),
('^u', 2),
('nc', 2),
('Y', 2),
('EG', 2),
('ir', 2),
('ca', 2)]
Most parts appear in only 2 solutions or less.
Analyzing: Set Cover Theory¶
Now I want to think about this as a set cover problem. Wikipedia shows this diagram to explain set cover:
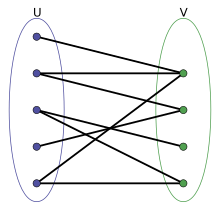
The idea is that each blue dot in set $u$ on the left represents a regex component, and each green dot in set $v$ represents a winner that is matched by the regex component. The problem is to pick some blue dots such that all the green dots are covered. In this example, we can see that picking the blue dots that are second and third from the top will do it.
But in general, what do our graphs look like? How many blue and green dots are there? How many links between them? Let's build a little tool to find out. We'll list the $N$ "most popular" blue and green dots—the ones with the most links to the other side. Then we'll show histograms of all the nodes and their numbers of links.
But first some explanation: I use the term multimap for a dictionary, like covers = {regex: {winner,...}}, that maps keys to collections. Then invert_multimap(covers) is of the form {winner: {regex, ...}}.
def show(W, L, N=10):
"Summarize the links between the set of winners, W, and its parts."
covers = regex_covers(W, L)
inv = invert_multimap(covers)
for ((n1, w), (n2, r)) in zip(top(N, covers), top(N, inv)):
print("{:8} {:2} | {:3}| {}".format(w, n1, n2, r))
print("TOTAL %5d | %3d TOTAL" % (len(covers), len(W)))
plt.subplot(1, 2, 1); histmm(covers, "parts", "winners")
plt.subplot(1, 2, 2); histmm(inv, "winners", "parts")
def top(N, multimap):
"The top N longest items in a dict of {key: {val,...})"
return sorted([(len(vals), key) for (key, vals) in multimap.items()], reverse=True)[:N]
def histmm(multimap, key, val):
"Display a histogram of how many values each key has."
plt.rcParams['figure.figsize'] = (8.0, 4.0)
plt.hist([len(v) for v in multimap.values()])
plt.xlabel('set size of {' + val + ',...}')
plt.ylabel('number of ' + key + ' mapping to that size')
def invert_multimap(multimap):
"Covert {key: {val,...}} to {val: [key,...]}."
result = defaultdict(set)
for key in multimap:
for val in multimap[key]:
result[val].add(key)
return result
show(winners, losers)
i..n 4 | 110| van-buren a.a 4 | 98| washington a..i 4 | 93| jefferson r.i. 3 | 93| eisenhower r.i 3 | 81| garfield oo.. 3 | 78| roosevelt oo. 3 | 72| buchanan oo 3 | 61| obama ma 3 | 61| kennedy li.. 3 | 59| jackson TOTAL 1615 | 34 TOTAL

What does this say? First the table says that there are only three regexes that have 4 winners; all the rest have 3 or fewer winners. So the links going left-to-right are rather sparse. There are more links going the other direction; 110 to van-buren, for example. The histograms give the whole picture mapping set sizes to the number of keys that have that set size. So, on the left we see that over 1400 regexes have a set size of one winner, and 100 or fewer have set sizes of 2 and 3, and we saw that only 3 regexes have a set size of 4 winners. On the right, the histogram shows a wide spread of winners that have set sizes between 1 and 110 regexes.
From looking at this I get two ideas:
I notice that both
'oo..'and'oo.'happen to match 3 winners. But even if I didn't know how many they matched, I would know that the winners matched by'oo..'must be a subset of the winners matched by'oo.'(remember that a set is a subset of itself). Furthermore,'oo.'is shorter. This suggests that we would never want to use'oo..'in a solution, because we could always make the solution one character shorter (and cover at least all the same winners) by substituting'oo.'. We say that * part A dominates B* if A is shorter and matches a superset of winners. We might as well throw out all dominated parts right at the start.It might be a good idea to pay special attention to the characters, like
'-', that appear in the winners but not the losers.
Let's look at another example:
show(dogs, cats)
E.S$ 41 | 186| SOFT COATED WHEATEN TERRIERS RS$ 34 | 184| STAFFORDSHIRE BULL TERRIERS ERS$ 34 | 175| GREATER SWISS MOUNTAIN DOGS .RS$ 34 | 162| TREEING WALKER COONHOUNDS IE.S 22 | 157| CAVALIER KING CHARLES SPANIELS E.RI 21 | 149| AMERICAN STAFFORDSHIRE TERRIERS T..R 20 | 147| WEST HIGHLAND WHITE TERRIERS IER. 19 | 146| STANDARD SCHNAUZERS IER 19 | 146| FLAT-COATED RETRIEVERS I.R. 19 | 146| CHESAPEAKE BAY RETRIEVERS TOTAL 4570 | 100 TOTAL

My immediate reaction to this is "there are a lot of retrievers and terriers." All ten of the parts in the table recognize this fact, but the left-hand histogram shows that almost all the parts match fewer than 5 dog breeds. In contrast, the right-hand histogram shows that most of the dog breeds have 9 or more parts that match them.
Let's look at one more example:
show(adverbs, nouns)
a.l 12 | 94| especially a.ly 11 | 83| eventually a.l. 11 | 74| particularly .a.l 11 | 67| actually ll 9 | 65| quickly ^..$ 9 | 65| exactly .ll 9 | 65| directly ..ll 8 | 63| certainly all 7 | 61| usually st$ 6 | 57| recently TOTAL 2049 | 98 TOTAL

The pattern looks similar here. Almost all the parts match only one winner, but most of the winners are matched by many parts. What can I conclude from this?
- It would be good to think of new types of parts that match more winners.
- Most parts are 2 or 3 characters long and most match just 1 or 2 winners. That suggests that often we will have a tie in the
scorefunction, and greedy search will arbitrarily pick the one that comes first. But I'm worried that another choice might be better. Maybe we should replace greedy search with something that considers more than one choice.
Given all we've seen, I will shift my attention to understanding the search algorithm we have, and thinking about how to improve it.
Analyzing: Understanding Greedy vs. Exhaustive Search¶
findregex is a greedy search algorithm. In general, greedy search is used when you are trying to find a solution that is composed of parts. On each iteration you choose a part that looks good, and you never reconsider that choice; you just keep on adding parts until you get a complete solution.
The pseudo-code for a general greedy_search, described as a recursive function, is given below. It takes two arguments: a set of parts, and a partial solution indicating parts that have previously been chosen.
# Pseudocode
def greedy_search(parts, partial_solution=None):
if is_complete(partial_solution):
return partial_solution
else:
best = max(parts, key=score)
return greedy_search(parts - {best}, partial_solution + best)
An exhaustive search considers every possible choice of parts, and selects the best solution. On each iteration exhaustive search picks a part (just like greedy search), but then it considers both using the part and not using the part. You can see that exhaustive search is almost identical to greedy search, except that it has two recursive calls (on lines 7 and 8) instead of one (on line 7). (If you are viewing this in a iPython notebook, not just a web page, you can toggle line numbers by pressing 'ctrl-M L' within a cell.) How do we choose between the results of the two calls? We need a cost function that we are trying to minimize. (For regex golf the cost of a solution is the length of the string.)
# Pseudocode
def exhaustive_search(parts, partial_solution=None):
if is_complete(partial_solution):
return partial_solution
else:
best = max(parts, key=score)
return min(exhaustive_search(parts - {best}, partial_solution + best),
exhaustive_search(parts - {best}, partial_solution),
key=cost)
Here's an interesting piece of trivia: the first thing that exhaustive search does is a greedy search! Think about it: on each recursive call, exhaustive_search selects the best part, and then calls itself recursively with best chosen as part of the partial solution. It keeps going until it reaches a complete solution. That's exactly what greedy search does. But then exhaustive search does more: It also considers all the cases where it didn't choose the best part.
Here's something else to ponder: why should we bother with selecting the "best" part? If we're going to explore all possibilities, wouldn't it be the same if we just selected any part, not the "best" one?
Searching: Computational Complexity of Greedy and Exhaustive Search¶
Greedy search only considers one path towards the goal of finding a solution. Exhaustive search considers two paths on every iteration. How much work is that all together? If there are P parts, then there are $2^P$ subsets of parts. Now, we don't have to consider every one of these subsets, because the search ends when we cover all the winners. If there are $W$ winners, than an upper bound on the number of combinations we have to consider is the number of ways we can pick $W$ parts from a pool of $P$, which in math we write as ($P$ choose $W$). For the presidential candidates $W$, is 34, and $P$ is 1615.
So exhaustive search would have to consider roughly (1615 choose 34) = $10^{70}$ combinations, which is clearly too many. Don't even think about dogs versus cats, where $W$ = 100 and $P$ = 4570, so (4570 choose 100) = $10^{207}$. Fortunately, there is another way.
Searching: Branch and Bound Search¶
Branch and bound is a search strategy that gets the same answer as exhaustive search, but runs faster because it avoids considering many combinations that could not possibly lead to an optimal solution. Here's how and why it works:
- The branch part of the name means that, just like exhaustive search, on each iteration it picks a part, and considers two branches, one where the part is in the solution, and one where it is not.
- The bound part of the name means that the algorithm continually keeps track of the lowest-cost solution it has found so far. This serves as a bound on what the optimal solution can be.
- The trick is to notice that the cost of a partial solution always increases as we add more parts to it. Therefore, if we ever get to a partial solution whose cost is more than the lowest-cost solution we have found so far, then we can immediately discard the partial solution, and never consider all the other combinations that would have come from continuing the partial solution. If there are $MP$ parts left to consider, that means we just eliminated $2^P$ potential combinations all at once. "Eliminating potential combinations" is also called "pruning the search tree"—"pruning" means cutting off unwanted branches.
The pseudocode below uses a global variable called CHEAPEST to hold the lowest-cost solution found so far. Note that the two branches (two recursive calls in lines 7 and 8) communicate through this global variable. If the first branch sets CHEAPEST to an improved solution, then the second branch will see it. That is why it is important to choose good "best" parts—it means we are more likely to find a good solution early on, which makes it more likely that we can prune away branches.
# Pseudocode
def branch_and_bound_search(parts, partial_solution=None):
if is_complete(partial_solution):
CHEAPEST = min(CHEAPEST, partial_solution, key=cost)
elif cost(partial_solution) < cost(CHEAPEST):
best = select_best(parts)
branch_and_bound_search(parts - {best}, partial_solution + best)
branch_and_bound_search(parts - {best}, partial_solution)
return CHEAPEST
Searching: Anytime Branch and Bound Search¶
Even with all this pruning, we still may be presented with problems that require trillions of recursive calls. Who's got that kind of time? But if we stop the algorithm at any time, we still have our best solution stored in CHEAPEST. Algorithms that have the property that an answer is always available are called anytime algorithms; let's do that.
I can think of two easy ways to allow early stopping. We could use the threading.Timer class to run the search for a given number of seconds, then stop. Or we could have a counter which gets decremented every time we make a call, and when it hits zero, stop. I'll use the second approach.
Enough pseudocode—here is a real implementation. Since global variables are considered bad style, I decided to use a class, BranchBound, to hold the lowest-cost solution and the number of calls remaining. The class provides one method, search, which does the work.
class BranchBound(object):
"Hold state information for a branch and bound search."
def __init__(self, winners, max_num_calls, k=4):
self.cheapest = trivial(winners)
self.calls = max_num_calls
self.k = k
def search(self, covers, partial=None):
"""Recursively extend partial regex until it matches all winners in covers.
Try all reasonable combinations until we run out of calls."""
if self.calls <= 0:
return self.cheapest
self.calls -= 1
covers, partial = simplify_covers(covers, partial)
if not covers: # Nothing left to cover; solution is complete
self.cheapest = min(partial, self.cheapest, key=len)
elif len(OR(partial, min(covers, key=len))) < len(self.cheapest):
def score(p): return self.k * len(covers[p]) - len(p)
best = max(covers, key=score) # Best part
covered = covers[best] # Set of winners covered by best
covers.pop(best)
# Try with and without the greedy-best part
self.search({c:covers[c]-covered for c in covers}, OR(partial, best))
self.search(covers, partial)
return self.cheapest
Simplifying Covers¶
There's a new function introduced above, simplify_covers. The idea is that you pass it a covers dict and a partial regex, and it does a triage process to divide the components in covers into three categories:
- Useless components: could never appear in an optimal solution.
- Necessary components: must appear in any solution (because no other component covers some winner).
- Remaining components: neither useless nor necessary.
The necessary components are joined to the partial regex that is passed in, to yield a new partial regex that the function returns. The useless components are eliminated, and the remaining ones are returned in a new covers dict.
simplify_covers works by first eliminating useless components, and then selecting necessary components. We keep repeating this process of eliminating and selecting until there are no more changes to covers:
def simplify_covers(covers, partial=None):
"Eliminate dominated regexes, and select ones that uniquely cover a winner."
previous = None
while covers != previous:
previous = covers
covers = eliminate_dominated(covers)
covers, necessary = select_necessary(covers)
partial = OR(partial, necessary)
return covers, partial
For convenience we modified the function OR slightly; we made it work just like the function max in that you can call it two ways: either with a single argument, which is a collection of components, or with 2 or more arguments, each a component. We also made it ignore components that are None, so that OR(None, 'a') equals 'a', but OR('a', 'b') equals 'a|b', as does OR(['a', 'b'])
def OR(*regexes):
"""OR together component regexes. Ignore 'None' components.
Allows both OR(a, b, c) and OR([a, b, c]), similar to max."""
if len(regexes) == 1:
regexes = regexes[0]
return '|'.join(r for r in regexes if r)
Simplifying Covers: Eliminating Dominated Components¶
We defined the notion of a regex being dominated if there is some other regex that is shorter (or at least not longer) and covers a superset of winners. How can we efficiently compute which parts are dominated? Here's one simple approach: go through each regex part, p, and every time we find one that is not dominated by any another regex part p2, add p (and its winners) to a new dict that we are building up. This approach works, but it is $O(n^2)$.
Here's an alternative that is faster: First, sort all the regexes so that the ones that match more winners come first (in case of tie, put the shorter ones first). (In other words, "best" first.) Initialize a new dict to empty, and go through the sorted regexes, p, one at a time. For each p, compare it only to the regexes, p2, that we have already added to the new dict; if none of them dominate p, then add p. This is still $O(n^2)$, but if, say, 99 out of 100 regexes are eliminated, we will only need $n^2/100$ comparisons.
The code for eliminate_dominated is a slight variant on the version by Stefan Pochmann (because his version turned out to be better than my first version). Note that the function signature represents a regex as a pair of numbers, the negative of the number of winners and the length in characters. The smaller (in lexicographical order) this pair is, the "better" the regex is. Why is it important to put the regexes in sorted order? So that we know that the only possible dominators are the ones that came before, not ones that come after. Note that, as we are going through the component regexes, p, in sorted order, if we ever hit a p that covers no winners, then we know that all the remaining p will also cover no winners (because we're going in best-first order), so we can break out of the loop immediately. And one more thing: the expression covers[p2] >= covers[p] asks if p2 covers a superset of the winners that p covers.
def eliminate_dominated(covers):
"""Given a dict of {regex: {winner...}}, make a new dict with only the regexes
that are not dominated by any others. A regex part p is dominated by p2 if p2 covers
a superset of the matches covered by p, and rp is shorter."""
newcovers = {}
def signature(p): return (-len(covers[p]), len(p))
for p in sorted(covers, key=signature):
if not covers[p]: break # All remaining r must not cover anything
# r goes in newcache if it is not dominated by any other regex
if not any(covers[p2] >= covers[p] and len(p2) <= len(p)
for p2 in newcovers):
newcovers[p] = covers[p]
return newcovers
Simplifying Covers: Selecting Necessary Components¶
If some winner is covered by only one part, then we know that part must be part of the solution. The function select_necessary finds all such parts, ORs them together, and returns that, along with a dict of the remaining covers, after removing the necessary parts (and removing all the winners that are covered by the neccessary parts).
def select_necessary(covers):
"""Select winners covered by only one part; remove from covers.
Return a pair of (covers, necessary)."""
counts = Counter(w for p in covers for w in covers[p])
necessary = {p for p in covers if any(counts[w] == 1 for w in covers[p])}
if necessary:
covered = {w for p in necessary for w in covers[p]}
covers = {p: covers[p] - covered
for p in covers if p not in necessary}
return covers, OR(necessary)
else:
return covers, None
Testing and Benchmarking: Branch and Bound¶
Let's make up a test suite (showing some examples of how these functions work). Then let's see if findregex works with the new branch and bound search.
def test_bb():
assert OR(['a', 'b', 'c']) == OR('a', 'b', 'c') == 'a|b|c'
assert OR(['a|b', 'c|d']) == OR('a|b', 'c|d') == 'a|b|c|d'
assert OR(None, 'c') == 'c'
covers1 = {'a': {'ann', 'abe'}, 'ab': {'abe'}}
assert eliminate_dominated(covers1) == {'a': {'ann', 'abe'}}
assert simplify_covers(covers1) == ({}, 'a')
covers2 = {'a': {'abe', 'cab'}, 'b': {'abe', 'cab', 'bee'},
'c': {'cab', 'cee'}, 'c.': {'cab', 'cee'}, 'abe': {'abe'},
'ab': {'abe', 'cab'}, '.*b': {'abe', 'cab', 'bee'},
'e': {'abe', 'bee', 'cee'}, 'f': {}, 'g': {}}
assert eliminate_dominated(covers2) == simplify_covers(covers2)[0] == {
'c': {'cab', 'cee'}, 'b': {'cab', 'abe', 'bee'}, 'e': {'cee', 'abe', 'bee'}}
covers3 = {'1': {'w1'}, '.1': {'w1'}, '2': {'w2'}}
assert eliminate_dominated(covers3) == {'1': {'w1'}, '2': {'w2'}}
assert simplify_covers(covers3) in (({}, '2|1'), ({}, '1|2'))
covers, nec = select_necessary({'a': {'abe'}, 'c': {'cee'}})
assert covers == {} and (nec == 'c|a' or nec == 'a|c')
assert {0, 1, 2} >= {1, 2}
assert {1, 2} >= {1, 2}
assert not ({1, 2, 4} >= {1, 3})
return 'test_bb passes'
test_bb()
'test_bb passes'
Let's investigate how much the cover simplification process is helping:
covers = regex_covers(winners, losers)
len(covers)
1615
covers2, partial = simplify_covers(covers)
len(covers2)
49
1 - len(covers2)/len(covers)
0.9696594427244583
We see that simplify_covers gives us a 97% reduction in the number of parts! What do the remaining covers look like?
simplify_covers(covers)
({'-': frozenset({'van-buren'}),
'.b': frozenset({'obama', 'van-buren'}),
'.f': frozenset({'garfield', 'taft'}),
'.h.n': frozenset({'buchanan', 'washington'}),
'.se': frozenset({'eisenhower', 'roosevelt'}),
'a..i': frozenset({'garfield', 'harding', 'harrison', 'washington'}),
'a.a': frozenset({'adams', 'buchanan', 'obama', 'reagan'}),
'a.t': frozenset({'carter', 'grant', 'taft'}),
'ad': frozenset({'adams', 'madison'}),
'am': frozenset({'adams', 'obama'}),
'an.$': frozenset({'cleveland', 'grant'}),
'ay.': frozenset({'hayes', 'taylor'}),
'bu': frozenset({'buchanan', 'bush', 'van-buren'}),
'di': frozenset({'harding', 'madison'}),
'el.$': frozenset({'garfield', 'roosevelt'}),
'g..n': frozenset({'grant', 'washington'}),
'ga': frozenset({'garfield', 'reagan'}),
'h..e': frozenset({'eisenhower', 'hayes'}),
'ho': frozenset({'eisenhower', 'hoover'}),
'i..n': frozenset({'eisenhower', 'harrison', 'madison', 'nixon'}),
'i..o': frozenset({'clinton', 'lincoln', 'wilson'}),
'i.l': frozenset({'garfield', 'mckinley'}),
'i.o': frozenset({'harrison', 'madison', 'nixon'}),
'ie.': frozenset({'garfield', 'pierce'}),
'is.': frozenset({'eisenhower', 'harrison', 'madison'}),
'li': frozenset({'clinton', 'coolidge', 'lincoln'}),
'ls': frozenset({'wilson'}),
'm..i': frozenset({'madison', 'mckinley'}),
'ma': frozenset({'madison', 'obama', 'truman'}),
'n..o': frozenset({'nixon', 'washington'}),
'n.e': frozenset({'kennedy', 'mckinley'}),
'ni': frozenset({'nixon'}),
'nl': frozenset({'mckinley'}),
'nn': frozenset({'kennedy'}),
'oe': frozenset({'monroe'}),
'oo': frozenset({'coolidge', 'hoover', 'roosevelt'}),
'r..s': frozenset({'harrison', 'roosevelt'}),
'r.e$': frozenset({'monroe', 'pierce'}),
'r.i': frozenset({'garfield', 'harding', 'harrison'}),
'r.n': frozenset({'grant', 'van-buren'}),
'ra': frozenset({'grant'}),
'rc': frozenset({'pierce'}),
'rt': frozenset({'carter'}),
'sh': frozenset({'bush', 'washington'}),
'ta': frozenset({'taft', 'taylor'}),
'to': frozenset({'clinton', 'washington'}),
'u..n': frozenset({'truman', 'van-buren'}),
'vel': frozenset({'cleveland', 'roosevelt'}),
'ye': frozenset({'hayes'})},
'j|po')
Now let's benchmark branch and bound. I'm going to introduce a modified version of benchmark, called bbenchmark, to print the number of calls taken. The easiest way to do that is to introduce a new version of findregex, called bb_findregex, that returns the BranchBound object it creates, rather than returning the solution. (In general, I tend to introduce a new function when I change the call/return signature, but not when I just improve the mechanism.)
def bbenchmark(examples=EXAMPLES, calls=10**4):
"Run these data sets; print summaries; return total of solution lengths."
totalchars = 0
for (W, Wname, Lname, L) in examples: # Do both ways
re.purge()
bb = bb_findregex(W, L, calls)
SOLUTION[W, L] = bb.cheapest
assert not mistakes(bb.cheapest, W, L)
legend = '{}({}):{}({})'.format(Wname, len(W), Lname, len(L))
print('{:20} {:6} calls, {:3}: "{}"'.format(
legend, (calls - bb.calls), len(bb.cheapest), truncate(bb.cheapest, 45)))
totalchars += len(bb.cheapest)
return totalchars
def bb_findregex(winners, losers, calls=10**4):
"Return a BranchBound object which contains the shortest regex that covers winners but not losers."
bb = BranchBound(winners, calls)
bb.search(regex_covers(winners, losers))
return bb
def findregex(winners, losers): return bb_findregex(winners, losers).cheapest
Remember, the old benchmark took about 5 seconds and totaled 1749 characters. Let's see how the branch and bound benchmark compares:
%time bbenchmark(calls=1000)
win(34):lose(34) 1000 calls, 52: "j|po|a.a|a..i|bu|ma|li|ls|a.t|vel|ho|ni|a ..." lose(34):win(34) 1000 calls, 58: "ss|^ki|^s|ox|^d|go|^.re|ry|hu|ai|o.d|n.y| ..." boy(10):girl(10) 9 calls, 11: "de|a.$|c|as" girl(10):boy(10) 13 calls, 10: "a$|a.i|e.i" drug(10):city(10) 3 calls, 15: "en|ir|o.$|b|x|q" city(10):drug(10) 17 calls, 11: "ri|an|h|a.e" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 223 calls, 24: "k|b|ld|...n|ah|ar|or|z|A" wars(6):trek(9) 27 calls, 9: " T|E..H|B" trek(9):wars(6) 9 calls, 13: "IS|Y|RA|CT| F" noun(100):adj(98) 1000 calls, 167: "law|rt$|o.y|ca|l.v|^g|ot$|^h.a|m.$|jo|^da ..." adj(98):noun(100) 809 calls, 146: "far|hu|f$|at$|urs|r.t|re$|b.t|a.l|^v|wh|s ..." noun(100):verb(94) 1000 calls, 168: "^ar|^en|ace|h.ng|.as|ot|er$|gu|h..d|m.n|k ..." verb(94):noun(100) 1000 calls, 170: "sa|rr|nk|p.y|nc|tar|b.y|ru|^u|wi|lay|ed$| ..." rand(58):built(147) 1000 calls, 73: "_p|ia|_e|ee|^sa|^u|and|ets|lti|^_.e|_s|_. ..." built(147):rand(58) 1000 calls, 130: "^range$|^i|Y|se.$|..E|^d|Wa|w$|ev|c$|xt|b ..." dog(100):cat(91) 1000 calls, 69: "^HAVANESE$|E.S$|O.S$|N.S$|.AS|GS|.HI|RD|B ..." cat(91):dog(100) 505 calls, 104: "SN|NX|EX|H$|JAV|^TH|Y$|AN$|BAL|T$|R$|MES| ..." movie(100):tv(97) 1000 calls, 158: "^GR|DY |^CI|WAR|GO| . |AP.|^N|^RA|HIN|E I ..." tv(97):movie(100) 1000 calls, 146: "OAP|EER|MAS|^.OS|4|WIR|H.W|6|.CI|X.$|,|MY ..." sci(50):star(50) 1000 calls, 67: "AL..|T..N|R.S| TO|.KA|KN|OS|NN|MU|W.I|IG. ..." star(50):sci(50) 1000 calls, 76: "UM|WES|CA|T. | ST|YN|F..D|LI..|GR|BU| GA| ..." CPU times: user 7.09 s, sys: 73.7 ms, total: 7.17 s Wall time: 7.24 s
1680
This is encouraging! We took about 2 seconds longer, but improved on the total number of characters by about 4%. For 10 of the 22 cases we didn't reach the cutoff of 1000 calls, which means that we searched every feasible combination of the parts we have. Let's try with 10,000 calls:
%time bbenchmark(calls=10000)
win(34):lose(34) 1599 calls, 52: "j|po|a.a|a..i|bu|ma|li|ls|a.t|vel|ho|ni|a ..." lose(34):win(34) 3123 calls, 57: "ss|^ki|^s|ox|i.$|go|^f|de|br|hu|d.l|n.y|k ..." boy(10):girl(10) 9 calls, 11: "de|a.$|c|as" girl(10):boy(10) 13 calls, 10: "a$|a.i|e.i" drug(10):city(10) 3 calls, 15: "en|ir|o.$|b|x|q" city(10):drug(10) 17 calls, 11: "ri|an|h|a.e" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 223 calls, 24: "k|b|ld|...n|ah|ar|or|z|A" wars(6):trek(9) 27 calls, 9: " T|E..H|B" trek(9):wars(6) 9 calls, 13: "IS|Y|RA|CT| F" noun(100):adj(98) 2055 calls, 167: "law|rt$|o.y|ca|l.v|^g|ot$|^h.a|m.$|jo|^da ..." adj(98):noun(100) 809 calls, 146: "far|hu|f$|at$|urs|r.t|re$|b.t|a.l|^v|wh|s ..." noun(100):verb(94) 10000 calls, 168: "^ar|^en|ace|h.ng|.as|ot|er$|gu|h..d|m.n|k ..." verb(94):noun(100) 3205 calls, 170: "sa|rr|nk|p.y|nc|tar|b.y|ru|^u|wi|lay|ed$| ..." rand(58):built(147) 1425 calls, 73: "_p|ia|_e|ee|^sa|^u|and|ets|lti|^_.e|_s|_. ..." built(147):rand(58) 10000 calls, 130: "^range$|^i|Y|se.$|ro|^d|Wa|w$|ev|xt|bo|^o ..." dog(100):cat(91) 10000 calls, 69: "^HAVANESE$|E.S$|O.S$|N.S$|.AS|GS|.HI|RD|B ..." cat(91):dog(100) 505 calls, 104: "SN|NX|EX|H$|JAV|^TH|Y$|AN$|BAL|T$|R$|MES| ..." movie(100):tv(97) 10000 calls, 158: "^GR|DY |^CI|WAR|GO| . |AP.|^N|^RA|HIN|E I ..." tv(97):movie(100) 10000 calls, 146: "OAP|EER|MAS|^.OS|4|WIR|H.W|6|.CI|X.$|,|MY ..." sci(50):star(50) 10000 calls, 67: "AL..|T..N|R.S| TO|.KA|KN|OS|NN|MU|W.I|IG. ..." star(50):sci(50) 10000 calls, 76: "UM|WES|CA|T. | ST|YN|F..D|GR|LO.|H.P| GA| ..." CPU times: user 17.7 s, sys: 251 ms, total: 17.9 s Wall time: 18.3 s
1679
We doubled the time and gained a few characters. How about 100,000 calls?
%time bbenchmark(calls=100000)
win(34):lose(34) 1599 calls, 52: "j|po|a.a|a..i|bu|ma|li|ls|a.t|vel|ho|ni|a ..." lose(34):win(34) 3123 calls, 57: "ss|^ki|^s|ox|i.$|go|^f|de|br|hu|d.l|n.y|k ..." boy(10):girl(10) 9 calls, 11: "de|a.$|c|as" girl(10):boy(10) 13 calls, 10: "a$|a.i|e.i" drug(10):city(10) 3 calls, 15: "en|ir|o.$|b|x|q" city(10):drug(10) 17 calls, 11: "ri|an|h|a.e" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 223 calls, 24: "k|b|ld|...n|ah|ar|or|z|A" wars(6):trek(9) 27 calls, 9: " T|E..H|B" trek(9):wars(6) 9 calls, 13: "IS|Y|RA|CT| F" noun(100):adj(98) 2055 calls, 167: "law|rt$|o.y|ca|l.v|^g|ot$|^h.a|m.$|jo|^da ..." adj(98):noun(100) 809 calls, 146: "far|hu|f$|at$|urs|r.t|re$|b.t|a.l|^v|wh|s ..." noun(100):verb(94) 100000 calls, 167: "^ar|^en|ace|h.ng|.as|ot|er$|gu|h..d|m.n|k ..." verb(94):noun(100) 3205 calls, 170: "sa|rr|nk|p.y|nc|tar|b.y|ru|^u|wi|lay|ed$| ..." rand(58):built(147) 1425 calls, 73: "_p|ia|_e|ee|^sa|^u|and|ets|lti|^_.e|_s|_. ..." built(147):rand(58) 82973 calls, 127: "^range$|^i|Y|se.$|ro|^d|Wa|w$|ev|xt|bo|^o ..." dog(100):cat(91) 100000 calls, 69: "^HAVANESE$|E.S$|O.S$|N.S$|.AS|GS|.HI|RD|B ..." cat(91):dog(100) 505 calls, 104: "SN|NX|EX|H$|JAV|^TH|Y$|AN$|BAL|T$|R$|MES| ..." movie(100):tv(97) 100000 calls, 154: "^GR|DY |^CI|WAR|GO| . |AP.|^N|^RA|HIN|E I ..." tv(97):movie(100) 100000 calls, 146: "OAP|EER|MAS|^.OS|4|WIR|H.W|6|.CI|X.$|,|MY ..." sci(50):star(50) 100000 calls, 67: "AL..|T..N|I$|.KA|KN|OS|VE|I.O| .RE| TO|LE ..." star(50):sci(50) 100000 calls, 75: "UM|WES|CA|GR|LO.|F..D|^B|DEA|I.L|^O| GA|H ..." CPU times: user 2min 53s, sys: 2.24 s, total: 2min 55s Wall time: 2min 59s
1670
We're slowly decreasing the total number of characters, but at the expense of increasing run time. I think if we want to make more progress, it is time to stop worrying about the search algorithm, and start worrying about what we're searching over.
New Parts: Repetition Characters¶
Following a suggestion by Stefan Pochmann, I will generate two new classes of parts that use the repetition characters '*', '+', and '?':
pairs: parts of the form
'A.*B'where'A'and'B'are any two non-special characters that appear anywhere in any winner, the dot is always the second character, and the third character is one of the repetition characters.reps: given a part such as
'a.c', insert any repetition character after any character in the part (yielding, for example,'a*.c').
Don't insert after '^' or '$', and don't allow redundant parts like '..*c'.
Here is a new version of regex_covers that adds the new parts:
def regex_covers(winners, losers):
"""Generate regex components and return a dict of {regex: {winner...}}.
Each regex matches at least one winner and no loser."""
losers_str = '\n'.join(losers)
wholes = {'^'+winner+'$' for winner in winners}
parts = {d for w in wholes for p in subparts(w) for d in dotify(p)}
reps = {r for p in parts for r in repetitions(p)}
pool = wholes | parts | pairs(winners) | reps
searchers = {p:re.compile(p, re.MULTILINE).search for p in pool}
return {p: Set(filter(searchers[p], winners))
for p in pool
if not searchers[p](losers_str)}
def pairs(winners, special_chars=Set('*+?^$.[](){}|\\')):
chars = Set(cat(winners)) - special_chars
return {A+'.'+q+B
for A in chars for B in chars for q in '*+?'}
def repetitions(part):
"""Return a set of strings derived by inserting a single repetition character
('+' or '*' or '?'), after each non-special character.
Avoid redundant repetition of dots."""
splits = [(part[:i], part[i:]) for i in range(1, len(part)+1)]
return {A + q + B
for (A, B) in splits
# Don't allow '^*' nor '$*' nor '..*' nor '.*.'
if not (A[-1] in '^$')
if not A.endswith('..')
if not (A.endswith('.') and B.startswith('.'))
for q in '*+?'}
def test_new_parts():
assert repetitions('a') == {'a+', 'a*', 'a?'}
assert repetitions('ab') == {'a+b', 'a*b', 'a?b',
'ab+', 'ab*', 'ab?'}
assert repetitions('a.c') == {'a+.c', 'a*.c', 'a?.c',
'a.c+', 'a.*c', 'a.?c',
'a.+c', 'a.c*', 'a.c?'}
assert repetitions('^a..d$') == {'^a+..d$', '^a*..d$', '^a?..d$',
'^a..d+$', '^a..d*$', '^a..d?$'}
assert pairs({'ab', 'c'}) == {
'a.*a', 'a.*b', 'a.*c',
'a.+a', 'a.+b', 'a.+c',
'a.?a', 'a.?b', 'a.?c',
'b.*a', 'b.*b', 'b.*c',
'b.+a', 'b.+b', 'b.+c',
'b.?a', 'b.?b', 'b.?c',
'c.*a', 'c.*b', 'c.*c',
'c.+a', 'c.+b', 'c.+c',
'c.?a', 'c.?b','c.?c'}
assert len(pairs({'1...2...3', '($2.34)', '42', '56', '7-11'})) == 8 * 8 * 3
covers = regex_covers({'one', 'on'}, {'won', 'wuan', 'juan'})
assert (eliminate_dominated(covers) == {'e': {'one'}, '^o': {'on', 'one'}})
return 'test_new_parts passes'
test_new_parts()
'test_new_parts passes'
Let's take our new parts out for a spin and see what they can do:
findregex(starwars, startrek)
' T|P.*E'
Awesome!
Remember, Randall had a ten character regex in the strip (see below); we previously got it down to nine, but we now have it down to seven!

Update(Nov 2015): There are two new movies in the works; let's see what they do to our golf score:
starwars = starwars | {'THE FORCE AWAKENS'}
startrek = startrek | {'BEYOND'}
findregex(starwars, startrek)
' T|P.*E|CE'
Too bad; back to ten characters.
How much more work are we doing with these additional parts? Before, regex_covers(winners, losers) gave 1615 regexes, which were reduced to 49 by simplify_covers. Now:
covers = regex_covers(winners, losers)
len(covers)
13200
covers2, partial = simplify_covers(covers)
len(covers2)
90
So the total number of regexes is increased almost 10-fold, but after simplification the number is only double what it was before. (To put it another way, simplify_covers eliminated 99.3% of the parts.) That's not too bad; let's add more components.
New Parts: Longer Ones¶
Previously we generated parts of length up to 4 characters. Why not say "we're doing 5"? The implementation is easy:
SUBPARTS = 5 # Maximum length of a subpart
def subparts(word):
"Return a set of subparts of word, consecutive characters up to length 5."
return set(word[i:i+1+s] for i in range(len(word)) for s in range(SUBPARTS))
But how many more regex components does this give us?
covers = regex_covers(winners, losers)
len(covers)
39537
covers2, partial = simplify_covers(covers)
len(covers2)
112
In the end the longer parts add only 22 new components, rejecting nearly 40,000 other parts. It is time to benchmark again. Remember our previous best was Branch and Bound with 100,000 calls, which yielded 1669 total characters in 170 seconds.
%time bbenchmark(calls=1000)
win(34):lose(34) 1000 calls, 47: "i.*o|o.*o|a.a|po|a.t|j|bu|ce|n.e|r.i|v.l| ..." lose(34):win(34) 1000 calls, 59: "r.*y|i.e?$|^s|d..t?e|r.$|la.$|^f|n.*k|d.n ..." boy(10):girl(10) 29 calls, 11: "a.$|de|c|as" girl(10):boy(10) 21 calls, 9: "a$|^..d*i" drug(10):city(10) 87 calls, 15: "o.$|x|ir|en|b|q" city(10):drug(10) 43 calls, 11: "ri|a.*e|h|k" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 1000 calls, 23: "^...a|k|...n|b|ld|or|ar" wars(6):trek(9) 25 calls, 7: " T|P.*E" trek(9):wars(6) 165 calls, 12: "I.?S|RA| F|Y" noun(100):adj(98) 1000 calls, 160: "v.l|^wa|m.*n|me?$|.i.*d|....o|an*.e$|..k$ ..." adj(98):noun(100) 1000 calls, 137: "e.+y|^..l*$|l.*s|rs*e$|a.l|ei?t|st$|en$|f ..." noun(100):verb(94) 1000 calls, 165: "h..g|mo?.n|p.*r|..h.|mb?e|ea*s|^k?i|.ne|o ..." verb(94):noun(100) 1000 calls, 163: "rr|tar|omb|^..p*l|^f?..$|b.y|^fi|f$|as*k| ..." rand(58):built(147) 1000 calls, 69: "ee|^_.+n|sam|ia|an*d.|^_.?e|ets|_a?.o|ga| ..." built(147):rand(58) 1000 calls, 126: "^.ang|r...$|c.*t|r.x*i|al*s|eb|^l*i|o.*p. ..." dog(100):cat(91) 1000 calls, 43: "E.+S$|I.*S$|H.+N.S|.HI|G.?S|.SO|W |TES|O.D." cat(91):dog(100) 1000 calls, 105: "J.V|RA?$|R.*A.$|LI?$|N.*X|M$|T$|DW|S.+E$| ..." movie(100):tv(97) 1000 calls, 149: " TH.+N| A*. |R...R|GR?O|UC*. |^N|AN?C.$|A ..." tv(97):movie(100) 1000 calls, 148: "4|HT?.W|..CH?I|XI$|PO*R|R..AN|MAS|..AY.|O ..." sci(50):star(50) 1000 calls, 70: "AN?L..|T..E?N|S.+HA|.KA|RM*.S|N.*RE|LER|G ..." star(50):sci(50) 1000 calls, 73: "U.*R.|GR|LO.|F.+D|I.Y?N| T*R|G.+Y|AE?.W|E ..." CPU times: user 3min 43s, sys: 4.52 s, total: 3min 47s Wall time: 3min 52s
1605
We reduced the total characters by about 4%, although it did take longer, even with only 1,000 calls. And notice we no longer need '^HAVANESE$'; instead we have 'H.*N.S', which saves 4 characters, and, look how many breeds it matches:
matches('H.*N.S', dogs)
{'AFGHAN HOUNDS',
'BASSET HOUNDS',
'BLOODHOUNDS',
'CHINESE CRESTED',
'CHINESE SHAR-PEI',
'DACHSHUNDS',
'HAVANESE',
'IRISH WOLFHOUNDS',
'ITALIAN GREYHOUNDS',
'TREEING WALKER COONHOUNDS'}
Let's continue benchmarking:
%time bbenchmark(calls=10000)
win(34):lose(34) 10000 calls, 46: "i.*o|o.*o|bu|a.t|j|ma|po|n.e|ie.|ay.|e.?a ..." lose(34):win(34) 10000 calls, 55: "r.*y|i.e?$|^s|go|de|^f|do|la.$|al|n.*k|k. ..." boy(10):girl(10) 29 calls, 11: "a.$|de|c|as" girl(10):boy(10) 21 calls, 9: "a$|^..d*i" drug(10):city(10) 87 calls, 15: "o.$|x|ir|en|b|q" city(10):drug(10) 43 calls, 11: "ri|a.*e|h|k" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 5709 calls, 23: "^...a|k|...n|b|ld|or|ar" wars(6):trek(9) 25 calls, 7: " T|P.*E" trek(9):wars(6) 165 calls, 12: "I.?S|RA| F|Y" noun(100):adj(98) 10000 calls, 160: "v.l|^wa|m.*n|me?$|.i.*d|....o|an*.e$|..k$ ..." adj(98):noun(100) 10000 calls, 136: "e.+y|^..l*$|l.*s|rs*e$|a.l|ei?t|st$|en$|f ..." noun(100):verb(94) 10000 calls, 162: "h..g|mo?.n|p.*r|..h.|mb?e|ea*s|^k?i|.ne|o ..." verb(94):noun(100) 10000 calls, 162: "rr|tar|omb|^..p*l|^f?..$|b.y|^fi|f$|as*k| ..." rand(58):built(147) 10000 calls, 69: "ee|^_.+n|sam|ia|an*d.|^_.?e|ets|.G|_s|_.o ..." built(147):rand(58) 10000 calls, 124: "^.ang|r...$|c.*t|r.x*i|al*s|eb|^l*i|o.*p. ..." dog(100):cat(91) 10000 calls, 43: "E.+S$|I.*S$|H.+N.S|.HI|G.?S|.SO|W |TES|O.D." cat(91):dog(100) 10000 calls, 104: "J.V|RA?$|R.*A.$|LI?$|N.*X|M$|T$|DW|S.+E$| ..." movie(100):tv(97) 10000 calls, 149: " TH.+N| A*. |R...R|GR?O|UC*. |^N|AN?C.$|A ..." tv(97):movie(100) 10000 calls, 148: "4|HT?.W|..CH?I|XI$|PO*R|R..AN|MAS|..AY.|O ..." sci(50):star(50) 10000 calls, 69: "AN?L..|T..E?N|S.+HA|.KA|RM*.S|N.*RE|LER|^ ..." star(50):sci(50) 10000 calls, 73: "U.*R.|GR|LO.|F.+D|I.Y?N| T*R|G.+Y|AE?.W|E ..." CPU times: user 3min 39s, sys: 2 s, total: 3min 41s Wall time: 3min 43s
1591
We're making good progress. What next? We now have so many parts, that many of the searches do not complete. Suppose one of our first choices was wrong, and the search took a part that does not belong in an optimal solution. We might well spend all our calls on the half of the search tree that keeps the part, never exploring a part of the tree without it. I'd like to alter the search algorithm to get us out of that rut.
Searching: Random Restart¶
One way out of the rut is to run the search for a while, then stop it, and run a different search, that explores a different part of the search space. This is called a random restart search. How do we get a different search when we restart? I can think of two easy things to vary:
- The '4' in the
scorefunction. That is, vary the tradeoff between number of winners matched and number of characters in a regex. - The tie-breaker. In case of a tie on
max(covers, key=score), Python always picks the first component. Let's make it choose a different one each time.
The first of these is easy; we can use the random.choice function to choose an integer, K, to serve as the tradeoff factor. The second is easy too. We could write an alternative to the max function, say max_random_tiebreaker. That would work, but an easier approach is to build the tiebreaker into the score function. In addition to awarding points for matching winners, and subtracting a point for each character in the solution, we will have score add in a random number. We'll call this the "fuzz factor" and use the variable F to determine how big it is. If the fuzz factor is a random number between 0 and 1, then all it does is serve as a tiebreaker. But if it is a random number that can be larger than 1, then sometimes it will cause max to pick a best part that does not have quite the best score. We're not sure how much randomness is best, so we'll let the values of K and F vary from one choice to the next.
def bb_findregex(winners, losers, calls=10000, restarts=10):
"Find the shortest disjunction of regex components that covers winners but not losers."
bb = BranchBoundRandomRestart(winners, calls)
covers = eliminate_dominated(regex_covers(winners, losers))
for _ in range(restarts):
bb.calls = calls
bb.search(covers.copy())
if bb.calls > 0: # If search was not cut off, we have optimal solution
return bb
return bb
class BranchBoundRandomRestart(BranchBound):
def search(self, covers, partial=None):
"""Recursively extend partial regex until it matches all winners in covers.
Try all reasonable combinations until we run out of calls."""
if self.calls <= 0:
return partial, covers
self.calls -= 1
covers, partial = simplify_covers(covers, partial)
if not covers: # Nothing left to cover; solution is complete
self.cheapest = min(partial, self.cheapest, key=len)
elif len(OR(partial, min(covers, key=len))) < len(self.cheapest):
# Try with and without the greedy-best component
K = random.choice((2, 3, 4, 4, 4, 5, 6))
F = random.choice((0.1, 0.1, 2.0))
def score(c): return K * len(covers[c]) - len(c) + random.uniform(0., F)
best = max(covers, key=score) # Best component
covered = covers[best] # Set of winners covered by r
covers.pop(best)
self.search({c:covers[c]-covered for c in covers}, OR(partial, best))
self.search(covers, partial)
return self.cheapest
%time bbenchmark(calls=100)
win(34):lose(34) 100 calls, 47: "i.*o|o.*o|a.a|po|a.t|j|bu|ce|r.i|ay.|ma|n ..." lose(34):win(34) 100 calls, 56: "r.*y|i.e?$|^s|go|d..e|^f|....k|la.$|d.n$| ..." boy(10):girl(10) 31 calls, 11: "a.$|de|c|as" girl(10):boy(10) 25 calls, 9: "a$|^..d*i" drug(10):city(10) 87 calls, 15: "o.$|x|ir|en|b|q" city(10):drug(10) 47 calls, 11: "ri|a.*e|h|k" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 100 calls, 23: "..r..|^...a|k|A|...n|ld" wars(6):trek(9) 23 calls, 7: " T|P.*E" trek(9):wars(6) 100 calls, 12: "I.?S|RA| F|Y" noun(100):adj(98) 100 calls, 159: "v.l|^wa|m.*n|me?$|....o|i.*n.$|an|..k$|a. ..." adj(98):noun(100) 100 calls, 128: "e.+y|^o?..$|l.*s|ll|rs*e$|en$|ei?t|st$|fa ..." noun(100):verb(94) 100 calls, 164: "h..g|mo?.n|p.*r|..h.|mb?e|ea*s|or.?$|^k?i ..." verb(94):noun(100) 100 calls, 157: "rr|tar|omb|^..p*l|^s*..$|b.y|f$|as*k|r.ad ..." rand(58):built(147) 100 calls, 69: "ee|^_.+n|sam|ia|an*d.|^_.?e|ets|.G|_a?.o| ..." built(147):rand(58) 100 calls, 121: "^.ang|r...$|c.*t|Wa|^d?i|al*s|eb|o.*p..|Y ..." dog(100):cat(91) 100 calls, 43: "E.+S$|I.*S$|H.+N.S|.HI|G.?S|.SO|W |TES|O.D." cat(91):dog(100) 100 calls, 96: "J.V|RA?$|T$|LI?$|AN*$|N.*X|DW|M$|Y$|S.+E$ ..." movie(100):tv(97) 100 calls, 142: " TH.+N| .E* |R...R|GO|^N|UC*. |AN?C.$|A.N ..." tv(97):movie(100) 100 calls, 146: "4|HT?.W|.CI|XI$|PO*R|R..AN|.MO|..AY.|AL.+ ..." sci(50):star(50) 100 calls, 67: "AN?L..|T..E?N|.S.+H|.KA|IL*.O|N.*RE|OS|LE ..." star(50):sci(50) 100 calls, 71: "U.*R.|GR|LO.|F.+D|I.N|G.+Y| T*R|ES? D|AE? ..." CPU times: user 3min 42s, sys: 2.19 s, total: 3min 44s Wall time: 3min 45s
1557
Remember, when it says "100 calls" here, it really means 1,000 calls, because we are doing 10 random restarts. This looks very promising; even with only 100 calls per restart, we're doing better than 100,000 calls without restarts. Let's continue:
%time bbenchmark(calls=1000)
win(34):lose(34) 1000 calls, 47: "i.*o|o.*o|a.a|po|a.t|j|bu|ay.|ma|di|n.e|i ..." lose(34):win(34) 1000 calls, 53: "^d|r.*y|^s|go|^f|c.?c|.k.?e|nd.|^.la|k.*g ..." boy(10):girl(10) 27 calls, 11: "a.$|c|de|as" girl(10):boy(10) 25 calls, 9: "a$|^..d*i" drug(10):city(10) 121 calls, 15: "o.$|x|ir|en|b|q" city(10):drug(10) 47 calls, 11: "ri|a.*e|h|k" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 1000 calls, 23: "k|^...a|...n|b|ld|ar|or" wars(6):trek(9) 25 calls, 7: " T|P.*E" trek(9):wars(6) 159 calls, 12: "I.?S|H |ER|Y" noun(100):adj(98) 1000 calls, 158: "v.l|^wa|m.*n|me?$|....o|.i.*d|a.ea?$|^g|^ ..." adj(98):noun(100) 1000 calls, 128: "e.+y|^o?..$|l.*s|ll|rs*e$|ei?t|st$|en$|fa ..." noun(100):verb(94) 1000 calls, 162: "h..g|mo?.n|er.?$|p.*r|ti*o|.ne|me|^k?i|f. ..." verb(94):noun(100) 1000 calls, 158: "rr|tar|omb|^..p*l|^s*..$|b.y|f$|as*k|r.ad ..." rand(58):built(147) 1000 calls, 69: "ee|^_.+n|sam|ia|an*d.|^_.?e|ets|_s|.G|_.o ..." built(147):rand(58) 1000 calls, 122: "^.ang|r...$|c.*t|r.t*i|^l*i|al*s|eb|^m*a| ..." dog(100):cat(91) 1000 calls, 43: "E.+S$|I.*S$|H.+N.S|.HI|G.?S|TES|.SO|W |O.D." cat(91):dog(100) 1000 calls, 96: "J.V|RA?$|T$|LD*$|AN*$|N.*X|M$|S.+E$|Y$|M. ..." movie(100):tv(97) 1000 calls, 139: " TH.+N| A*. |R...R|GO|^N|UC*. |AN?C.$|A.N ..." tv(97):movie(100) 1000 calls, 148: "4|HT?.W|..CH?I|XI$|PO*R|..AY.|R..AN|MAS|. ..." sci(50):star(50) 1000 calls, 67: "AN?L..|T..E?N|.S.+H|.KA|IL*.O|N.*RE|OS|M. ..." star(50):sci(50) 1000 calls, 72: "U.*R.|GR|LO.|I.+H$|F.+D| T*R|G.+Y| M?.T|W ..." CPU times: user 3min 55s, sys: 3.07 s, total: 3min 58s Wall time: 3min 59s
1553
%time bbenchmark(calls=10000)
win(34):lose(34) 10000 calls, 46: "i.*o|o.*o|bu|a.t|j|ma|po|ay.|n.e|ie.|ar?d ..." lose(34):win(34) 10000 calls, 55: "r.*y|i.e?$|^s|go|^f|de|do|n.*k|al|la.$|k. ..." boy(10):girl(10) 27 calls, 11: "a.$|c|de|as" girl(10):boy(10) 21 calls, 9: "a$|^..d*i" drug(10):city(10) 89 calls, 15: "o.$|x|ir|b|^.?e" city(10):drug(10) 47 calls, 11: "ri|an|ca|id" foo(21):bar(21) 1 calls, 3: "f.o" bar(21):foo(21) 6183 calls, 23: "^...a|k|...n|b|ld|ar|or" wars(6):trek(9) 21 calls, 7: " T|P.*E" trek(9):wars(6) 149 calls, 12: "I.?S|RA| F|Y" noun(100):adj(98) 10000 calls, 158: "v.l|^wa|m.*n|me?$|....o|.i.*d|an*.e$|^g|^ ..." adj(98):noun(100) 10000 calls, 128: "e.+y|^o?..$|ll|l.*s|rs*e$|ei?t|st$|en$|fa ..." noun(100):verb(94) 10000 calls, 160: "h..g|mo?.n|p.*r|..h.|me|^k?i|.ne|or.?$|f. ..." verb(94):noun(100) 10000 calls, 157: "rr|tar|omb|^..p*l|^s*..$|b.y|f$|as*k|r.ad ..." rand(58):built(147) 10000 calls, 69: "ee|^_.+n|sam|ia|an*d.|^_.?e|ets|.G|_.o|_s ..." built(147):rand(58) 10000 calls, 119: "^.ang|r...$|c.*t|Wa|^d?i|al*s|eb|li|o.*p. ..." dog(100):cat(91) 10000 calls, 43: "E.+S$|I.*S$|H.+N.S|.HI|G.?S|.SO|W |TES|O.D." cat(91):dog(100) 10000 calls, 96: "J.V|RA?$|T$|LI?$|AN*$|N.*X|DW|M$|S.+E$|Y$ ..." movie(100):tv(97) 10000 calls, 144: " TH.+N| B*. |R...R|GR?O|UC*. |AN?C.$|^N|A ..." tv(97):movie(100) 10000 calls, 146: "4|HT?.W|.CI|XI$|PO*R|R..AN|..AY.|O.+L.$|I ..." sci(50):star(50) 10000 calls, 67: "AN?L..|T..E?N|.S.+H|.KA|IL*.O|N.*RE|OS|MU ..." star(50):sci(50) 10000 calls, 72: "U.*R.|GR|LO.|F.+D|I.+H$| T*R|G.+Y|^B|YN|P ..." CPU times: user 6min 22s, sys: 13.1 s, total: 6min 35s Wall time: 6min 39s
1551
Just One More Thing: Negative Lookahead¶
In the foo versus bar example, we have a big asymmetry in the solution lengths: three letter for 'foo' compared to 23 characters in the other direction. But if you are a real regular expression superhero, then you might know about negative lookahead assertions and you could solve bar versus foo like this:
not_foo = '^(?!.*foo)'
not mistakes(not_foo, bar, foo)
True
Whoa—what just happened there? The form '^(?!.*foo)' means "starting from the beginning of the line, look ahead for '.*foo' (that is, any number of characters followed by 'foo'). If it is there, then fail, else succeeed." That's just what we need to match all the non-foo strings in the bar collection. Let's apply this idea to the complete benchmark and see how many characters we save. We'll use the SOLUTION dict that was compiled by the previous call to benchmark:
def consider_negative_lookahead(W, L):
"Return either SOLUTION[W, L] or negative lookup of SOLUTION[L, W], whichever is shorter."
solution = min(SOLUTION[W, L], '^(?!.*(' + SOLUTION[L, W] + '))',
key=len)
assert not mistakes(solution, W, L)
return solution
%time sum(len(consider_negative_lookahead(W, L)) for (W, _, _, L) in EXAMPLES)
CPU times: user 13.8 ms, sys: 564 µs, total: 14.4 ms Wall time: 14.6 ms
1434
Very nice! We've improved from 1163 to 1079 characters, and it took almost no time at all.
Summary of Results¶
# Algorithm Line Times Total character counts
DATA = [('Greedy', 'gD-', [6], [1740]),
('BB (1/10/100K)', 'bo-', [8, 21, 196], [1676, 1674, 1669]),
('BB + Parts (1/10K)', 'kd-', [272, 288], [1595, 1587]),
('BB Restart (1/10/100K)', 'rs-', [289, 303, 493], [1560, 1556, 1547]),
('BB Restart NegLook (100K)','m*-', [493], [1426])]
def display(data=DATA):
fig = plt.figure()
ax = fig.add_subplot(111)
for (label, line, times, counts) in data:
plt.plot(times, counts, line, label=label)
x, y = times[-1], counts[-1]
offset = (-22, -15) if line in ('rs-', 'm*-') else (10, -5)
ax.annotate(str(y), xy=(x, y), xytext=offset, textcoords='offset points')
plt.xlabel('Time (seconds)'); plt.ylabel('Solution size (total chars)')
plt.legend(loc='lower left');
display()

We've made great strides, decreasing the total solution length by 20%. (It is up to you whether that 20% improvement is worth the increase in time from 6 seconds to 8 minutes.)
Profiling Again¶
Now where does the time go? Let's check again:
cProfile.run('findregex(adverbs, nouns)', sort='cumulative')
58868388 function calls (58523178 primitive calls) in 31.743 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 31.743 31.743 {built-in method builtins.exec}
1 0.000 0.000 31.743 31.743 <string>:1(<module>)
1 0.001 0.001 31.743 31.743 <ipython-input-42-69eab5774964>:21(findregex)
1 0.089 0.089 31.742 31.742 <ipython-input-58-6db5f5ee7e3e>:1(bb_findregex)
100168/10 0.669 0.000 21.789 2.179 <ipython-input-58-6db5f5ee7e3e>:13(search)
100000 0.502 0.000 17.521 0.000 <ipython-input-31-c9c277f8c298>:1(simplify_covers)
206952 1.544 0.000 10.482 0.000 <ipython-input-33-2d740317bec1>:1(eliminate_dominated)
1 0.007 0.007 9.192 9.192 <ipython-input-46-6a20b4de3330>:1(regex_covers)
3912459 2.945 0.000 8.547 0.000 {built-in method builtins.any}
1 0.094 0.094 7.017 7.017 <ipython-input-46-6a20b4de3330>:9(<dictcomp>)
89666 0.042 0.000 6.922 0.000 re.py:222(compile)
89666 0.418 0.000 6.880 0.000 re.py:278(_compile)
206951 0.597 0.000 6.729 0.000 <ipython-input-34-656b8fb485f1>:1(select_necessary)
89666 0.371 0.000 6.368 0.000 sre_compile.py:531(compile)
18021115 4.283 0.000 4.514 0.000 <ipython-input-33-2d740317bec1>:10(<genexpr>)
89666 0.286 0.000 3.301 0.000 sre_parse.py:819(parse)
206951 0.988 0.000 2.941 0.000 <ipython-input-34-656b8fb485f1>:5(<setcomp>)
206951 0.505 0.000 2.721 0.000 __init__.py:505(__init__)
89666 0.175 0.000 2.655 0.000 sre_parse.py:429(_parse_sub)
50079 0.526 0.000 2.642 0.000 {built-in method builtins.max}
89666 0.147 0.000 2.492 0.000 sre_compile.py:516(_code)
89666 0.995 0.000 2.376 0.000 sre_parse.py:491(_parse)
206952 1.066 0.000 2.302 0.000 {built-in method builtins.sorted}
206951 0.298 0.000 2.194 0.000 __init__.py:574(update)
629833 0.840 0.000 2.116 0.000 <ipython-input-58-6db5f5ee7e3e>:26(score)
1 1.632 1.632 2.045 2.045 <ipython-input-46-6a20b4de3330>:10(<dictcomp>)
89666 0.448 0.000 1.257 0.000 sre_compile.py:412(_compile_info)
2102604 0.892 0.000 1.235 0.000 <ipython-input-33-2d740317bec1>:6(signature)
206951 0.575 0.000 1.221 0.000 {built-in method _collections._count_elements}
629833 1.108 0.000 1.167 0.000 random.py:342(uniform)
4571891 1.131 0.000 1.131 0.000 <ipython-input-34-656b8fb485f1>:5(<genexpr>)
171350/89666 0.649 0.000 1.077 0.000 sre_compile.py:64(_compile)
420715 0.359 0.000 1.022 0.000 <ipython-input-32-308f8216e1f8>:1(OR)
11197547/11115863 0.957 0.000 0.982 0.000 {built-in method builtins.len}
1145385 0.296 0.000 0.796 0.000 {built-in method builtins.isinstance}
2893272 0.645 0.000 0.645 0.000 <ipython-input-34-656b8fb485f1>:4(<genexpr>)
438739 0.442 0.000 0.624 0.000 {method 'join' of 'str' objects}
480786 0.197 0.000 0.610 0.000 sre_parse.py:247(get)
253034/171350 0.487 0.000 0.585 0.000 sre_parse.py:167(getwidth)
206951 0.317 0.000 0.500 0.000 abc.py:178(__instancecheck__)
570452 0.475 0.000 0.475 0.000 sre_parse.py:226(__next)
490104 0.295 0.000 0.418 0.000 sre_parse.py:157(__getitem__)
89666 0.413 0.000 0.413 0.000 {method 'search' of '_sre.SRE_Pattern' objects}
532234 0.287 0.000 0.287 0.000 {built-in method builtins.min}
2239948 0.278 0.000 0.278 0.000 {method 'append' of 'list' objects}
100158 0.090 0.000 0.248 0.000 random.py:250(choice)
75442 0.224 0.000 0.224 0.000 <ipython-input-34-656b8fb485f1>:8(<dictcomp>)
399102 0.139 0.000 0.202 0.000 sre_parse.py:165(append)
81684 0.119 0.000 0.198 0.000 sre_compile.py:386(_simple)
89666 0.123 0.000 0.196 0.000 sre_parse.py:217(__init__)
413902 0.183 0.000 0.183 0.000 _weakrefset.py:70(__contains__)
1087726 0.182 0.000 0.182 0.000 <ipython-input-32-308f8216e1f8>:6(<genexpr>)
50079 0.177 0.000 0.177 0.000 <ipython-input-58-6db5f5ee7e3e>:30(<dictcomp>)
100158 0.110 0.000 0.150 0.000 random.py:220(_randbelow)
245052 0.082 0.000 0.106 0.000 sre_parse.py:153(__len__)
1 0.019 0.019 0.100 0.100 <ipython-input-46-6a20b4de3330>:7(<setcomp>)
179332 0.077 0.000 0.100 0.000 sre_compile.py:513(isstring)
171350 0.098 0.000 0.098 0.000 sre_parse.py:105(__init__)
171350 0.079 0.000 0.097 0.000 sre_parse.py:276(tell)
38126 0.084 0.000 0.090 0.000 sre_compile.py:391(_generate_overlap_table)
89666 0.074 0.000 0.085 0.000 sre_parse.py:797(fix_flags)
7902 0.012 0.000 0.081 0.000 <ipython-input-46-6a20b4de3330>:19(repetitions)
89666 0.079 0.000 0.079 0.000 sre_parse.py:70(__init__)
179332 0.063 0.000 0.079 0.000 sre_parse.py:75(groups)
89666 0.071 0.000 0.071 0.000 {built-in method _sre.compile}
629833 0.060 0.000 0.060 0.000 {method 'random' of '_random.Random' objects}
7902 0.043 0.000 0.056 0.000 <ipython-input-46-6a20b4de3330>:23(<setcomp>)
75442 0.046 0.000 0.046 0.000 <ipython-input-34-656b8fb485f1>:7(<setcomp>)
171350 0.046 0.000 0.046 0.000 sre_parse.py:242(match)
123848 0.030 0.000 0.030 0.000 {method 'getrandbits' of '_random.Random' objects}
246020 0.027 0.000 0.027 0.000 {built-in method builtins.ord}
1 0.004 0.004 0.022 0.022 <ipython-input-46-6a20b4de3330>:6(<setcomp>)
81684 0.022 0.000 0.022 0.000 sre_parse.py:161(__setitem__)
76384 0.018 0.000 0.018 0.000 {method 'extend' of 'list' objects}
2433 0.006 0.000 0.016 0.000 <ipython-input-2-f5df3c47a125>:57(dotify)
7902 0.012 0.000 0.012 0.000 <ipython-input-46-6a20b4de3330>:22(<listcomp>)
176 0.012 0.000 0.012 0.000 {method 'clear' of 'dict' objects}
61211 0.012 0.000 0.012 0.000 {method 'endswith' of 'str' objects}
89666 0.011 0.000 0.011 0.000 {method 'items' of 'dict' objects}
100158 0.010 0.000 0.010 0.000 {method 'bit_length' of 'int' objects}
49204 0.009 0.000 0.009 0.000 {method 'get' of 'dict' objects}
2433 0.006 0.000 0.009 0.000 <ipython-input-2-f5df3c47a125>:60(<setcomp>)
50079 0.008 0.000 0.008 0.000 {method 'pop' of 'dict' objects}
98 0.001 0.000 0.002 0.000 <ipython-input-52-5391d2372e48>:3(subparts)
9029 0.002 0.000 0.002 0.000 {method 'startswith' of 'str' objects}
3568 0.002 0.000 0.002 0.000 <ipython-input-52-5391d2372e48>:5(<genexpr>)
6431 0.002 0.000 0.002 0.000 <ipython-input-2-f5df3c47a125>:62(replacements)
1 0.000 0.000 0.001 0.001 <ipython-input-46-6a20b4de3330>:14(pairs)
1 0.001 0.001 0.001 0.001 <ipython-input-46-6a20b4de3330>:16(<setcomp>)
10 0.000 0.000 0.000 0.000 {method 'copy' of 'dict' objects}
1 0.000 0.000 0.000 0.000 <ipython-input-30-cf018e1cb457>:3(__init__)
1 0.000 0.000 0.000 0.000 <ipython-input-2-f5df3c47a125>:74(trivial)
1 0.000 0.000 0.000 0.000 <ipython-input-46-6a20b4de3330>:5(<setcomp>)
1 0.000 0.000 0.000 0.000 weakref.py:102(remove)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
We see that the majority of the time is in simplify_covers, and within that, half the time goes to eliminate_dominated. That gives us some ideas of where speedups could be made, but gains will be harder now than before.
Speculating: Other Ideas¶
I'm going to stop here, but I'll briefly mention some other ideas that I didn't get to investigate. Perhaps you can play with some of these, or with other ideas.
Completely different approach: Thomas Breuel suggested doing minimization of weighted finite state transducers.
Character classes: We never considered character classes, such as
'[abc]'. It is not obvious they would help, but it is possible. Consider the fragment'ld|la', which shows up in one of the solutions. We could replace that with a single component,'l[da]'. But we haven't gained anything; both are 5 characters long. If we had had'l.d|l.c|l.b|l.a'then the replacement'l.[a-d]'would save 8 characters, but I don't see many opportunities like that. It might also be possible to use negative character classes, likel[^y]to explicitly avoid something in the losers set.Prefilter parts: Currently,
regex_coversgenerates a huge set of components, then eliminates the ones that match losers (or don't match winners), and then eliminates the ones that are dominated. We could makeregex_coversfaster by not generating components that can't possibly contribute. Suppose we're considering a subpart, say'ab'. If it matches no losers, then there is no reason to extend it to a longer subpart, such as'abc', because we know that'abc'is dominated by'ab'. By filtering out dominated parts before we have to check them, I estimate we should be able to cut the time forregex_coversin half, maybe better.Better component choice: We pick the "best" component based on how many winners it covers and how many characters it takes. Maybe we could have a better measure; perhaps taking into account whether it covers winners that are "easy" to cover by other regexes, or "hard" to cover.
Tuning: We have the two parameters
KandF, which are randomly chosen from a fairly arbitrary distribution. We could measure which values of the parameters perform better and pick those values more often.Post-editing: We concentrated on the task of generating a solution from scratch; another task is to improve an existing solution. For example, take the set of components in a solution, and see if one component could be dropped—it is possible that all the winners covered by that component might accidentally have been covered by other components, making it unnecessary. Or take all pairs of components, and see if they could be replaced by a shorter set of components.
Better bounds: Branch and Bound search works best if the bounds are tight. If we can recognize early that the path we are on cannot possibly be as good as the best solution found so far then we can cut off search early and save time. But the bound estimate we are using now is a poor one. We estimate the cost of a solution as the cost of the partial solution plus the cost of the shortest component remaining. We use this estimate because all we know for sure is that we need at least one more component. Here's one way to get a better bound by recognizing that in many cases we will need more than one more component. We'll define the following quantities:
- P = the length of the partial solution, plus the "|", if needed. So if the partial solution is
None, then P = 0, else P is the length plus 1. - S = the length of the shortest regex component in
covers. - W = the number of winners still in
covers. - C = the largest number of winners covered by any regex in
covers.
The current estimate is P + S. We can see that a better estimate is P + S × ceil(W / C).
- P = the length of the partial solution, plus the "|", if needed. So if the partial solution is
I hope you had fun seeing how I (and Stefan) attacked this problem; now go out and solve some problems of your own.
[*Peter Norvig*](http://norvig.com), Feb. 2014