Getting NLTK for Text Processing¶
This notebook introduces the Natural Language Toolkit (NLTK) which facilitates a broad range of tasks for text processing and representing results. It's part of the The Art of Literary Text Analysis and assumes that you've already worked through previous notebooks (Getting Setup, Getting Started and Getting Texts). In this notebook we'll look in particular at:
Installing the NLTK Library¶
The Anaconda bundle that we're using already includes NLTK, but the bundle doesn't include the NLTK data collections that are available. Fortunately, it's easy to download the data, and we can even do it within a notebook. Following the same steps as before, create a new notebook named "GettingNltk" and run this first code cell:
import nltk
nltk.download() # download NLTK data (we should only need to run this cell once)
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
True
This should cause a new window to appear (eventually) with a dialog box to download data collections. For the sake of simplicity, if possible select the "all" row and press "Download". Once the download is complete, you can close that window.
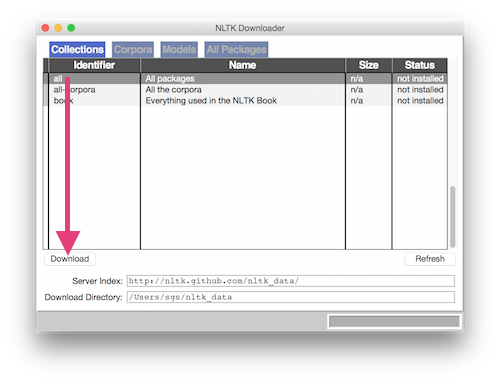
Now you're set! You can close and delete the temporary notebook used for installation.
Text Processing¶
Now that we have NLTK installed, let's use it for text processing.
We'll start by retrieving The Gold Bug plain text that we had saved locally in the Getting Texts notebook. If you need to recapitulate the essentials of the previous notebook, try running this to retrieve the text:
import urllib.request
# retrieve Poe plain text value
poeUrl = "http://www.gutenberg.org/files/2147/2147-0.txt"
poeString = urllib.request.urlopen(poeUrl).read().decode()```
And then this, in a separate <a href="Glossary.ipynb#cell" title="An input strucutre in a Notebook which runs either Markdown or Python code">cell</a> so that we don't read repeatedly from Gutenberg:
```python
import os
# isolate The Gold Bug
start = poeString.find("THE GOLD-BUG")
end = poeString.find("FOUR BEASTS IN ONE")
goldBugString = poeString[start:end]
# save the file locally
directory = "data"
if not os.path.exists(directory):
os.makedirs(directory)
with open("data/goldBug.txt", "w") as f:
f.write(goldBugString)```
Now we should be ready to retrieve the text:
with open("data/goldBug.txt", "r") as f:
goldBugString = f.read()
Now we will work toward showing the top frequency words in our plain text. This involves three major steps:
- processing our plain text to find the words (also known as tokenization)
- counting the frequencies of each word
- displaying the frequencies information
Tokenization¶
Tokenization is the basic process of parsing a string to divide it into smaller units of the same kind. You can tokenize text into paragraphs, sentences, words or other structures, but here we're focused on recognizing words in our text. For that, let's import the nltk library and use its convenient word_tokenize() function. NLTK actually has several ways of tokenizing texts, and for that matter we could write our own code to do it. We'll have a peek at the first ten tokens.
import nltk
goldBugTokens = nltk.word_tokenize(goldBugString)
goldBugTokens[:10]
['THE', 'GOLD-BUG', 'What', 'ho', '!', 'what', 'ho', '!', 'this', 'fellow']
We can see from the above that word_tokenize does a useful job of identifying words (including hyphenated words like "GOLD-BUG"), but also includes tokens like the exclamation mark. In some cases punctuation like this might be useful, but in our case we want to focus on word frequencies, so we should filter out punctuation tokens. (To be fair, nltk.word_tokenize() is expecting to work with sentences that have already been parsed so we're slightly misusing it here, but that's ok.)
To accomplish the filtering we will use a construct called list comprehension with a conditional test built in. Let's take it one step at a time, first using a loop structure like we've already seen in Getting Texts, and then doing the same thing with a list comprehension.
# technique 1 where we create a new list
loopList = []
for word in goldBugTokens[:10]:
loopList.append(word)
print(loopList, "(for loop technique)")
# technique 2 with list comprehension
print([word for word in goldBugTokens[:10]], "(list comprehension technique)")
['THE', 'GOLD-BUG', 'What', 'ho', '!', 'what', 'ho', '!', 'this', 'fellow'] (for loop technique) ['THE', 'GOLD-BUG', 'What', 'ho', '!', 'what', 'ho', '!', 'this', 'fellow'] (list comprehension technique)
Identical! So the general form of a list comprehension (which is very compact) is:
[expression(item) for item in list)]
We can now go a step further and add a condition to the list comprehension : we'll only include the word in the final list if the first character in the word is alphabetic as defined by the isalpha() function (word[0] – remember the string sequence technique).
print([word for word in goldBugTokens[:10] if word[0].isalpha()])
['THE', 'GOLD-BUG', 'What', 'ho', 'what', 'ho', 'this', 'fellow']
Word Frequencies¶
Now that we've had a first pass at word tokenization (keeping only word tokens), let's look at counting word frequencies. Essentially we want to go through the tokens and tally the number of times each one appears. Not surprisingly, the NLTK has a very convenient method for doing just this, which we can see in this small sample (the first 10 word tokens):
goldBugRealWordTokensSample = [word for word in goldBugTokens[:10] if word[0].isalpha()]
goldBugRealWordFrequenciesSample = nltk.FreqDist(goldBugRealWordTokensSample)
goldBugRealWordFrequenciesSample
Counter({'GOLD-BUG': 1,
'THE': 1,
'What': 1,
'fellow': 1,
'ho': 2,
'this': 1,
'what': 1})
This FreqDist object is a kind of dictionary, where each word is paired with its frequency (separated by a colon), and each pair is separated by a comma. This kind of dictionary also has a very convenient way of displaying results as a table:
goldBugRealWordFrequenciesSample.tabulate()
ho what GOLD-BUG fellow What THE this 2 1 1 1 1 1 1
The results are displayed in descending order of frequency (two occurrences of "ho"). One of the things we can notice is that "What" and "what" are calculated separately, which in some cases may be good, but for our purposes probably isn't. This might lead us to rethink our steps until now and consider the possibility of converting our string to lowercase during tokenization.
goldBugTokensLowercase = nltk.word_tokenize(goldBugString.lower()) # use lower() to convert entire string to lowercase
goldBugRealWordTokensLowercaseSample = [word for word in goldBugTokensLowercase[:10] if word[0].isalpha()]
goldBugRealWordFrequenciesSample = nltk.FreqDist(goldBugRealWordTokensLowercaseSample)
goldBugRealWordFrequenciesSample.tabulate(20)
what ho gold-bug the fellow this 2 2 1 1 1 1
Good, now we have "what" and "What" as the same word form counted twice. (There are disadvantages to this as well, such as more difficulty in identifying proper names and the start of sentences, but text mining is often a set of compromises.)
Let's redo our entire workflow with the full set of tokens (not just a sample).
goldBugTokensLowercase = nltk.word_tokenize(goldBugString.lower())
goldBugRealWordTokensLowercase = [word for word in goldBugTokensLowercase if word[0].isalpha()]
goldBugRealWordFrequencies = nltk.FreqDist(goldBugRealWordTokensLowercase)
One simple way of measuring the vocabulary richness of an author is to calculate the ratio of the total number of words and the number of unique words. If an author repeats words more often, it may be because he or she is drawing on a smaller vocabulary (either deliberately or not), which is a measure of style. There are several factors to consider, such as the length of the text, but in the simplest terms we can calculate the lexical diversity of an author by dividng the number of word forms (types) by the total number of tokens. We already have the necessary ingredients:
- types: number of different words (number of word: count pairs in
goldBugRealWordFrequencies) - tokens: total number of word tokens (length of
goldBugRealWordTokensLowercase
print("number of types: ", len(goldBugRealWordFrequencies))
print("number of tokens: ", len(goldBugRealWordTokensLowercase))
print("type/token ratio: ", len(goldBugRealWordFrequencies)/len(goldBugRealWordTokensLowercase))
number of types: 2681 number of tokens: 13508 type/token ratio: 0.1984749777909387
We haven't yet looked at our output for the top frequency lowercase words.
goldBugRealWordFrequencies.tabulate(20) # show a sample of the top frequency terms
the of and i to a in it you was that with for as had at he but this we 877 465 359 336 329 327 238 213 162 137 130 114 113 113 110 108 103 99 99 98
We tokenized, filtered and counted in three lines of code, and then a fourth to show the top frequency terms, but the results aren't necessarily very exciting. There's not much in these top frequency words that could be construed as especially characteristic of The Gold Bug, in large part because the most frequent words are similar for most texts of a given language: they're so-called function words that have more of a syntactic (grammatical) function rather than a semantic (meaning-bearing) value.
Fortunately, our NLTK library contains a list of stop-words for English (and other languages). We can load the list and look at its contents.
import nltk
stopwords = nltk.corpus.stopwords.words("english")
print(sorted(stopwords)) # sort them alphabetically before printing
['a', 'about', 'above', 'after', 'again', 'against', 'all', 'am', 'an', 'and', 'any', 'are', 'as', 'at', 'be', 'because', 'been', 'before', 'being', 'below', 'between', 'both', 'but', 'by', 'can', 'did', 'do', 'does', 'doing', 'don', 'down', 'during', 'each', 'few', 'for', 'from', 'further', 'had', 'has', 'have', 'having', 'he', 'her', 'here', 'hers', 'herself', 'him', 'himself', 'his', 'how', 'i', 'if', 'in', 'into', 'is', 'it', 'its', 'itself', 'just', 'me', 'more', 'most', 'my', 'myself', 'no', 'nor', 'not', 'now', 'of', 'off', 'on', 'once', 'only', 'or', 'other', 'our', 'ours', 'ourselves', 'out', 'over', 'own', 's', 'same', 'she', 'should', 'so', 'some', 'such', 't', 'than', 'that', 'the', 'their', 'theirs', 'them', 'themselves', 'then', 'there', 'these', 'they', 'this', 'those', 'through', 'to', 'too', 'under', 'until', 'up', 'very', 'was', 'we', 'were', 'what', 'when', 'where', 'which', 'while', 'who', 'whom', 'why', 'will', 'with', 'you', 'your', 'yours', 'yourself', 'yourselves']
We can test whether one word is an item in another list with the following syntax, here using our small sample.
print("sample words: ", goldBugRealWordTokensLowercaseSample)
print("sample words not in stopwords list: ", [word for word in goldBugRealWordTokensLowercaseSample if not word in stopwords])
sample words: ['the', 'gold-bug', 'what', 'ho', 'what', 'ho', 'this', 'fellow'] sample words not in stopwords list: ['gold-bug', 'ho', 'ho', 'fellow']
So we can now tweak our word filter with an additional condition, adding the and operator between the test for the alphabetic first character and the test for presence in the stopword list. We add a slash () character to treat the code as if it were on one line. Alternatively, we could have done this in two steps (perhaps less efficient but arguably easier to read):
# first filter tokens with alphabetic characters
gbWords = [word for word in goldBugTokensLowercase if word[0].isalpha()]
# then filter stopwords
gbContentWords = [word for word in gbWords if word not in stopwords]```
goldBugRealContentWordTokensLowercase = [word for word in goldBugTokensLowercase \
if word[0].isalpha() and word not in stopwords]
goldBugRealContentWordFrequencies = nltk.FreqDist(goldBugRealContentWordTokensLowercase)
goldBugRealContentWordFrequencies.tabulate(20) # show a sample of the top
upon de jupiter legrand one said well massa could bug skull parchment tree made first time two much us beetle 81 73 53 47 38 35 35 34 33 32 29 27 25 25 24 24 23 23 23 22
Now we have words that seem a bit more meaningful (even if the table format is a bit off). The first word ("upon") could be considered a function word (a preposition) that should be in the stop-word list, though it's less common in modern English. The second word ("de") would be in a French stop-word list, but seems striking here in English. The third word "'s" is actually an artifact of possessive forms – sometimes tokenization keeps possessives together with the word, sometimes not. The next words ("jupiter" and "legrand") merit closer inspection, they may be proper names that have been transformed to lowercase. We can continue on like this with various observations and hypotheses, but really we probably want to have a closer look at individual occurences to see what's happening. For that, we'll build a concordance.
Building a Simple Concordance¶
A concordance allows us to see each occurrence of a term in its context. It has a rich history in textual scholarship, dating back to well before the advent of computers. It's a tool for studying word usage in context.
The easiest way to build a concordance is to create an NLTK Text object from a list of word tokens (in this case we'll use the unfiltered list so that we can better read the text). So, for instance, we can ask for a concordance of "de" to try to better understand why it occurs so often in this English text.
goldBugText = nltk.Text(goldBugTokens)
goldBugText.concordance("de", lines=10)
Displaying 10 of 73 matches: ou , '' here interrupted Jupiter ; `` de bug is a goole bug , solid , ebery bi is your master ? '' `` Why , to speak de troof , massa , him not so berry well aint find nowhar -- dat 's just whar de shoe pinch -- my mind is got to be be taint worf while for to git mad about de matter -- Massa Will say noffin at al -- Massa Will say noffin at all aint de matter wid him -- but den what make h a gose ? And den he keep a syphon all de time -- '' '' Keeps a what , Jupiter , Jupiter ? '' `` Keeps a syphon wid de figgurs on de slate -- de queerest fi ' `` Keeps a syphon wid de figgurs on de slate -- de queerest figgurs I ebber syphon wid de figgurs on de slate -- de queerest figgurs I ebber did see . Is vers . Todder day he gib me slip fore de sun up and was gone de whole ob de bl
In the concordance view above all the occurrences of "de" are aligned to make scanning each occurrence easier.
Next Steps¶
Here are some tasks to try:
- Show a table of the top 20 words
- Choose 3 words to add to the stop-words list using list concatenation
- Regenerate the list of the top 20 words using your new stop-words list
- Instead of testing for presence in the stopword list, how would you test for words that contain 10 characters or more?
- Determine whether or not the word provided to the concordance function is case sensitive
In the next notebook we're going to get Graphical.
CC BY-SA From The Art of Literary Text Analysis by Stéfan Sinclair & Geoffrey Rockwell. Edited and revised by Melissa Mony.
Created February 7, 2015 and last modified January 14, 2018 (Jupyter 4)