# Utils
from scipy.stats import bernoulli
from scipy.stats import beta
import matplotlib.pyplot as plt
import numpy as np
from numpy.random import multinomial
from numpy.random import dirichlet
%matplotlib inline
Yet another very gentle Tutorial on Latent Dirichlet Allocation and Inference using Gibbs Sampling
by Călin-Rareș Turliuc (raresct @ Github)
A very gentle Introduction¶
Latent Dirichlet Allocation (LDA) is one of the probabilistic models proposed for topic modelling of a corpus of documents. Let's dissect this statement. A document is simply a list of words (or tokens if you prefer NLP terminology). A corpus of documents is simply a list of documents. Topic modelling aims to discover the underlying topics in a corpus. For example, we might have a corpus with documents related to politics and sports. To perform manual topic modelling, we have to read the whole corpus and classify the documents, and the resulting set of topics will be politics and sports. This is a tedious task which we aim to automate.
Why probablistic modelling? In our politics and sports example, we have made the distinction between politics and sports as mutually exclusive topic options, i.e. a document can either talk about politics, or about sports. However, perhaps in some documents, politics and sports are not mutually exclusive, e.g. the document is about the political impact of the outcome of a sporting event, or about a basketball player (like Dennis Rodman) meeting diplomatic officials of some country (like North Korea) et caetera. The point is we want to treat a document as a mixture of topics: some may have higher weights, some lower. For instance, if a document is ineed about sports and makes absolutely no reference to politics, we will give sports a very high weight, and politics a very low weight.
The vocabulary of a corpus is simply the set of all the words appearing in its documents. For humans, the term "topic of a document" has an intuitive semantics. For a computer, not so much. So let us define a topic in a quantified manner. A topic is represented by a categorical distribution on the vocabulary of the corpus. What does that mean? Let's look at only some possible words in our vocabulary: "baseball", "racket", "president", "parliament". The topics will assign different weights to these words: "baseball" will be assigned a very high weight by "sports" and a very low one by "politics". "Racket" will be assigned a high but no very high weight by "sports" and a low but not very low weight by "politics", due to its polysemy, i.e. tennis racket vs. racketeering. "President" will be assigned fairly similar weigths, perhaps a little higher weight by "politics", and parliament will be assigned a low weight by "sports" and a high weight by "politics". This is mapping our intuitive definition of the topics "politics" and "sports" to these particular words. LDA will help us uncover these topics automatically, and the results might not always correspond to one's intuition. After all, there is a degree of subjectivity in everything, and especially in problems of language and topic modelling.
The Genesis of Documents (Generative Story)¶
Unfortunately LDA cannot be described without probabilistic terminology. Fortunately, the distributions involved are only of two kinds: categorical and Dirichlet. The former distribution is easy to understand, as it corresponds to the chances of a $k$-sided die of landing on a particular side, i.e. $Cat(\frac{1}{6}, \frac{1}{6}, \frac{1}{6}, \frac{1}{6}, \frac{1}{6}, \frac{1}{6})$ is a categorical distribution describing the behaviour of a fair 6 sided die. The latter, i.e. Dirichlet, is harder to intuitively explain, but, briefly, it is a probability over the all the possible values of the probabilities of a categorical distribution. This concept of a probability of a probability can be a mindfuck for a non-Bayesian, but it is impossible to explain it in this tutorial, as it would take too long.
LDA, like any probabilistic model for topic modelling, describes a way in which a corpus is generated. It is not perfect, nor is it likely to be true from a neuro-scientific perspective. But that doesn't matter that much, because it is flexible, due to the Dirichlet priors. This story of the genesis of a corpus is called a generative story. For LDA, we assume that each document of the corpus is generated independently, so if we have created $0$ or $n>0$ documents, we have the same beliefs about the generation of the first, respectively of the $n+1$-th document. As we already established, each document will be characterized by a topic mixture, described as a categorical distribution over all the possible topics. Furthermore, each document consists of a list of words. How are these words generated? The LDA model states that each word has an associated unknown topic. We will prefer the terminology of a "latent topic (of a word)". The topic of a word is no longer a mixture, it is either "sports" or "politics", but the same word in a different position in a corpus (or even a document) can have a different latent topic. According to this topic, each word is chosen independently from the word distribution associated to the topic. What is this word distribution? Well, we have seen it already in an informal way, in the "baseball", "racket", "president", "parliament" example. The weights that we talked about are actually the probabilities (or parameters as we will prefer) of a categorical distribution over words, given a particular topic. Then, a word is chosen by tossing a $W$ sided weighted die (where $W$ is the number of words in the vocabulary) and observing the side, i.e. the word on which it lands. Similarly, the topic of a word is chosen by tossing a $T$ sided weighted die according to the topic distribution, where $T$ is the number of topics in the corpus. The generative story is completed by adding the priors on the word and topic distributions, i.e. the parameters of these distributions are sampled from a corresponding Dirichlet distribution. Usually, the Dirichlet priors for topic distributions are common for all documents, and the priors for word distributions are common for all topics.
The rest of this tutorial consists of a formal description of LDA and a common example used to concretely illustrate LDA.
The Probabilistic Model¶
Let us recapitulate the generative story, introducing some notation. Feel free to skip to the plate model or to the example if you get bored. Let $D$ denote the number of documents in the corpus and each document has a length of $L_d$ words and a topic distribution $\theta_d$, a categorical distribution with $T$ categories. Each topic $t$ has a word distribution $\phi_t$, a categorical distribution with $W$ categories. To generate a document, we generate each word independently. For each document $d$ and word position $l$, a topic $z_{dl}$ corresponding to that position is sampled from the topic distribution:
$P(z_{dl} = t) = \theta_d(t)$
According to the sampled topic, the word $w_{dl}$ is generated according to:
$P(w_{dl} = w) = \phi_{z_{dl}}(w)$
We place Dirichlet conjugate priors on $\theta$:
$\theta \sim Dirichlet(\alpha)$
and $\phi$:
$\phi \sim Dirichlet(\beta)$.
Furthermore, to simplify things, we assume $\alpha$ and $\beta$ are symmetric priors, and in experiments we initalize them to $1$.
The probabilistic model in plate model notation is illustrated below:
lda_pm = Image(filename='images/lda_pm.png')
lda_pm

Our goal is to infer $\phi$, and possibly $\theta$. We will focus on $\phi$ in the following example. The inference algorithm we will use is Gibbs Sampling. To keep things decoupled, we have chosen to describe it in a very gentle tutorial fashion in a separate notebook found at this link. Therefore, we shall dive right in to an example.
A common example of Gibbs sampling for LDA¶
In this example, we will play with artificial data, and in a future notebook we will look at real data. So, for now, our purpose is to choose a $\phi$, generate a corpus according to it, use it as input to our Gibbs sampler, and check that the output $\hat{\phi}$ is somewhat similar to the original $\phi$.
Let's assume we have a 25 word vocabulary, 10 topics, 100 documents, and 100 words per document. We arrange the word distribution $\phi$ in a 5X5 matrix and plot it as an image (the blacker the pixel, the lower the probability).
# 25 word vocabulary
W = 25
# image size
L = np.sqrt(W)
# 10 topics
T = 10
# 100 documents
D = 100
# 100 words per document
N = 100
# phi is given as the horizontal and vertical topics on the 5X5 images
phi = [np.zeros((L, L)) for i in range(T)]
line = 0
for phi_t in phi:
if line >= L:
trueLine = int(line - L)
phi_t[:,trueLine] = 1/L*np.ones(L)
else:
phi_t[line] = 1/L*np.ones(L)
line += 1
We chose the topics to be parallel or perpendicular to each other simply for the purpose of identifying them easily by just looking at the images.
# plot the topics
f, axs = plt.subplots(1,T+1,figsize=(15,1))
ax = axs[0]
ax.text(0,0.4, "Topics: ", fontsize = 16)
ax.axis("off")
ax.get_yaxis().set_visible(False)
ax.get_xaxis().set_visible(False)
for (ax, (i,phi_t)) in zip(axs[1:], enumerate(phi)):
ax.get_yaxis().set_visible(False)
ax.get_xaxis().set_visible(False)
ax.imshow(phi_t, interpolation='none', cmap='Greys_r')

Next we sample $\theta$ from its prior $\alpha$. (Note that we could have done the same thing for $\phi$, but for visualization purposes, we chose a particular $\phi$.
# sample theta from alpha = 1
theta = [dirichlet(np.ones(T)) for i in range(D)]
B = []
# sample documents from theta and phi
for d in range(D):
doc = np.zeros(W)
theta_sample = multinomial(N, theta[d])
for t,count in enumerate(theta_sample):
doc += multinomial(count, phi[int(t)].flatten())
doc = doc.reshape(L,L)
B.append(doc)
We now have all the ingredients to generate some artificial data. A document will also be represented by a 5X5 image, and a word or pixel will be blacker the less frequently it appears in the document.
# plot the documents
j = int(np.sqrt(D))
for row in range(j):
f, axs = plt.subplots(1,j+1,figsize=(10,1))
ax = axs[0]
if row==0:
ax.text(0,0.4, "Docs: ", fontsize = 12)
ax.axis("off")
ax.get_yaxis().set_visible(False)
ax.get_xaxis().set_visible(False)
for (ax, doc) in zip(axs[1:], B[row*j:row*j+j]):
ax.get_yaxis().set_visible(False)
ax.get_xaxis().set_visible(False)
ax.imshow(doc, interpolation='none', cmap='Greys_r')










Notice that some of the documents in our corpus have a clear dominant topic (or even 2). However, there are many documents that are difficult to decipher topic-wise based on visual inspection.
# convert from bag of words to word list
words = []
for b in B:
doc = []
for idx,el in enumerate(b.flatten()):
doc += [idx]*el
words += doc
Now we are ready to feed the corpus to the Gibbs sampler. Note that this is a particularly bad implementation, for multiple reasons: it is not OO, it is written in Python without any help from our C cousin or other optimization options and I'm sure you can find many more programming flaws. However, it is a quick and dirty readable close-to-pseudocode implementation, so we'll have to settle for it in this small example.
# naive implementation of the LDA Gibbs Sampler
def ldaGibbsSampler(maxIt,words,T,D,N, W, alpha, beta):
# initialize z
theta = [dirichlet(alpha*np.ones(T)) for i in range(D)]
z = np.zeros(D*N)
for i in range(D):
for j in range(N):
cat_val = multinomial(1, theta[i])
z[i*N+j] = np.flatnonzero(cat_val>0)[0]
CWT, CDT, sum_CWT, sum_CDT = compute_counts(words, z, N, W, T, D)
# iterate the sampler
phis, phi_iter = [], []
for it in range(maxIt):
if it%10 == 0:
phi_l, theta_l = uncollapse(CWT, CDT, sum_CWT, sum_CDT, alpha, beta, T, W, D)
phis.append(phi_l)
phi_iter.append(it)
for i in range(D):
for j in range(N):
idx = i*N+j
CWT, CDT = update_counts(False, CWT, CDT, sum_CWT, sum_CDT, words, z, idx, N)
z_ij = update_conditional(idx, CWT, CDT, sum_CWT, sum_CDT, alpha, beta, W, T)
z[idx] = z_ij
CWT, CDT = update_counts(True, CWT, CDT, sum_CWT, sum_CDT, words, z, idx, N)
phi_l, theta_l = uncollapse(CWT, CDT, sum_CWT, sum_CDT, alpha, beta, T, W, D)
phis.append(phi_l)
phi_iter.append(maxIt)
return CWT, CDT, sum_CWT, sum_CDT, phis, phi_iter
def update_counts(increment, CWT, CDT, sum_CWT, sum_CDT, words, z, idx, N):
w = words[idx]
t = int(z[idx])
d = idx/N
if increment:
CWT[w,t] += 1
CDT[d,t] += 1
sum_CWT[t] += 1
sum_CDT[d] += 1
else:
CWT[w,t] -= 1
CDT[d,t] -= 1
sum_CWT[t] -= 1
sum_CDT[d] -= 1
return CWT, CDT
def compute_counts(words, z, N, W, T, D):
CWT = np.zeros((W,T))
CDT = np.zeros((D,T))
sum_CWT = np.zeros(T)
sum_CDT = np.zeros(D)
for (idx, (t, w)) in enumerate(zip(z, words)):
t = int(t)
CWT[w,t] += 1
sum_CWT[t] += 1
d = idx/N
CDT[d,t] += 1
sum_CDT[d] += 1
return CWT, CDT, sum_CWT, sum_CDT
def update_conditional(idx, CWT, CDT, sum_CWT, sum_CDT, alpha, beta, W, T, eps = 10**-10):
probs = np.zeros(T)
sum_probs = 0
w = words[idx]
d = idx/N
for k in range(T):
val = (CWT[w,k]+beta)*(CDT[d,k]+alpha)/(sum_CWT[k]+beta*W+eps)/(sum_CDT[d]+alpha*T+eps)
probs[k] = val
sum_probs += val
probs_norm = probs/sum_probs
z_ij_cat = multinomial(1, probs_norm)
return np.flatnonzero(z_ij_cat>0)[0]
def uncollapse(CWT, CDT, sum_CWT, sum_CDT, alpha, beta, T, W, D):
phi_learned = np.zeros((T, W))
theta_learned = np.zeros((D, T))
for w in range(W):
for t in range(T):
f1 = CWT[w,t]+beta
f2 = sum_CWT[t]+beta*W
phi_learned[t,w] = f1/f2
for d in range(D):
for t in range(T):
g1 = CDT[d,t]+alpha
g2 = sum_CDT[d]+alpha*T
theta_learned[d,t] = g1/g2
return phi_learned, theta_learned
Let's run it!
%%time
CWT, CDT, sum_CWT, sum_CDT, phis, phi_iter = ldaGibbsSampler(100,words,T,D,N,W,1,1)
CPU times: user 3min 48s, sys: 564 ms, total: 3min 49s Wall time: 3min 48s
As you can see, it is indeed very bad in terms of performance, but let's not worry about that for now. Let's see if we managed to recover $\phi$! We have traced $\phi$ along the iterations of the sampler, and we plot it as a series of images, then as a gif.
%%bash
mkdir -p phi_gif
rm phi_gif/*.png
# let's plot phi
for (row, (it,phi_learned)) in enumerate(zip(phi_iter, phis)):
f, axs = plt.subplots(1,T+1,figsize=(15,1))
ax = axs[0]
ax.text(0,0.4, "Iter. {}".format(it), fontsize = 16)
ax.axis("off")
ax.get_yaxis().set_visible(False)
ax.get_xaxis().set_visible(False)
for ((i,phi_t),ax) in zip(enumerate(phi_learned),axs[1:]):
i += 1
ax.get_yaxis().set_visible(False)
ax.get_xaxis().set_visible(False)
ax.imshow(phi_t.reshape(5,5), interpolation='none', cmap='Greys_r')
f.savefig('phi_gif/{0:04d}.png'.format(row), format='png')











%%bash
convert -delay 60 -loop 0 phi_gif/*.png phi_gif/phi.gif
Pretty gif time! @_@
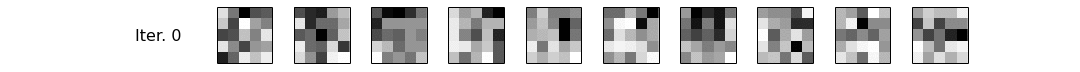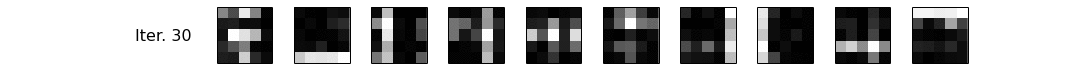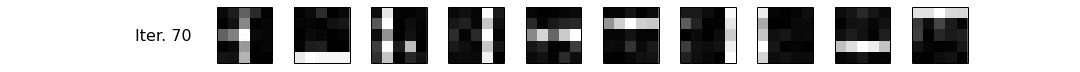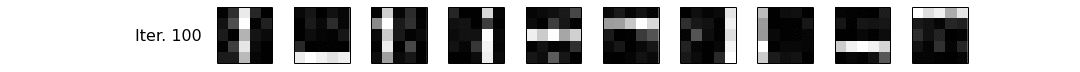
Conclusions¶
Alright, let's interpret what we have just seen. Notice that at iteration 0, our $\phi$ is garbage, and by garbage, I mean random. Then, using necromancy, we summon Reverend Thomas Bayes and Josiah Willard Gibbs from their graves, and give them some pen and paper to constantly improve our $\phi$, based on the evidence, i.e. the corpus we have generated. ...Uhm, forget that, I mean we let the number crunching magic do its work! We can see the patterns become clearer and clearer, and by the end of our small sampling routine (100 iterations is a very small number for a sampler), we have mostly recovered our original topics. Hurray! Let's go get some ice-cream and celebrate. Oh, and in a future notebook, we'll use a proper implementation to learn topics from documents written by pesky humans rather than generating them artificially. See ya, tschüß and au revoir!