Mining the Social Web, 1st Edition - Hacking on Twitter Data (Chapter 1)¶
If you only have 10 seconds...
Twitter's new API will prevent you from running much of the code from Mining the Social Web, and this IPython Notebook shows you how to roll with the changes and adapt as painlessly as possible until an updated printing is available. In particular, it shows you how to authenticate before executing any API requests and demonstrates how to use the new search API.
If you have a couple of minutes...
Twitter is officially retiring v1.0 of their API as of March 2013 with v1.1 of the API being the new status quo. There are a few fundamental differences that social web miners that should consider (see Twitter's blog at https://dev.twitter.com/blog/changes-coming-to-twitter-api and https://dev.twitter.com/docs/api/1.1/overview) with the two changes that are most likely to affect an existing workflow being that authentication is now mandatory for all requests, rate-limiting being on a per resource basis (as opposed to an overall rate limit based on a fixed number of requests per unit time), various platform objects changing (for the better), and search semantics changing to a "pageless" approach. All in all, the v1.1 API looks much cleaner and more consistent, and it should be a good thing longer-term although it may cause interim pains for folks migrating to it.
The latest printing of Mining the Social Web (2012-02-22, Third release) reflects v1.0 of the API, and this document is intended to provide readers with updated information and examples that specifically related to Twitter requests from Chapter 1 of the book until a new printing provides updates.
I've tried to add some filler in between the examples below so that they flow and are easy to follow along; however, they'll make a lot more sense to you if you are following along with the text. The great news is that you can download the sample chapter that corresponds to this IPython Notebook at http://shop.oreilly.com/product/0636920010203.do free of charge!
IPython Notebooks are also available for Chapters 4 and 5. As a reader of my book, I want you to know that I'm committed to helping you in any way that I can, so please reach out on Facebook at https://www.facebook.com/MiningTheSocialWeb or on Twitter at http://twitter.com/SocialWebMining if you have any questions or concerns in the meanwhile. I'd also love your feedback on whether or not you think that IPython Notebook is a good tool for tinkering with the source code for the book, because I'm strongly considering it as a supplement for each chapter.
Regards - Matthew A. Russell
Examples Adapted From The Book¶
Twitter implements OAuth 1.0A as its standard authentication mechanism, and in order to use it to make requests to Twitter's API, you'll need to go to https://dev.twitter.com/apps and create a sample application. There are four primary identifiers you'll need to note for an OAuth 1.0A workflow: consumer key, consumer secret, access token, and access token secret. Note that you will need an ordinary Twitter account in order to login, create an app, and get these credentials.
The examples in this chapter take advantage of the excellent twitter package (See https://github.com/sixohsix/twitter), which you can install in a terminal with easy_install or pip as follows:
$
$ pip install twitter```
Once installed, you should be able to open up a Python interpreter (or better yet, your IPython interpreter) and get rolling. See http://ipython.org/ for more information on IPython if you're not already using it or viewing this file in IPython Notebook.
import twitter
# Go to http://twitter.com/apps/new to create an app and get these items
# See https://dev.twitter.com/docs/auth/oauth for more information on Twitter's OAuth implementation
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
OAUTH_TOKEN = ''
OAUTH_TOKEN_SECRET = ''
auth = twitter.oauth.OAuth(OAUTH_TOKEN, OAUTH_TOKEN_SECRET,
CONSUMER_KEY, CONSUMER_SECRET)
twitter_api = twitter.Twitter(domain='api.twitter.com',
api_version='1.1',
auth=auth
)
Example 1-3. Retrieving Twitter trends
# With an authenticated twitter_api in existence, you can now use it to query Twitter resources as usual.
# However, the trends resource is cleaned up a bit in v1.1, so requests are a bit simpler than in the latest
# printing. See https://dev.twitter.com/docs/api/1.1/get/trends/place
# The Yahoo! Where On Earth ID for the entire world is 1
WORLD_WOE_ID = 1
# Prefix id with the underscore for query string parameterization.
# Without the underscore, it's appended to the URL itself
world_trends = twitter_api.trends.place(_id=WORLD_WOE_ID)
print world_trends
IPython Notebook didn't display the output because the result of the API call was captured as a variable. Here's how you could print a readable version of the response.
import json
print json.dumps(world_trends, indent=1)
Now that you're authenticated and understand a bit more about making requests with Twitter's new API, let's look at some examples that involve search requests, which are a bit different with v1.1 of the API.
Example 1-4. Paging through Twitter search results
# Like all other APIs, search requests now require authentication and have a slightly different request and
# response format. See https://dev.twitter.com/docs/api/1.1/get/search/tweets
q = "SNL"
count = 100
search_results = twitter_api.search.tweets(q=q, count=count)
statuses = search_results['statuses']
# v1.1 of Twitter's API provides a value in the response for the next batch of results that needs to be parsed out
# and passed back in as keyword args if you want to retrieve more than one page. It appears in the 'search_metadata'
# field of the response object and has the following form:'?max_id=313519052523986943&q=NCAA&include_entities=1'
# The tweets themselves are encoded in the 'statuses' field of the response
# Here's how you would grab five more batches of results and collect the statuses as a list
for _ in range(5):
try:
next_results = search_results['search_metadata']['next_results']
except KeyError, e: # No more results when next_results doesn't exist
break
kwargs = dict([ kv.split('=') for kv in next_results[1:].split("&") ]) # Create a dictionary from the query string params
search_results = twitter_api.search.tweets(**kwargs)
statuses += search_results['statuses']
Just like before, here's how you could print out the results of the statuses, though beware that there are many of them. (Note that ipython pretty prints Python dictionary objects automatically in your terminal-based session.)
import json
print json.dumps(statuses[0:2], indent=1) # Only print a couple of tweets here in IPython Notebook
Example 1-5. Pretty-printing Twitter data as JSON
Python's list comprehensions are very useful indeed. Here's how to use a list comprehension to extract the text from the rather bloated status objects.
Example 1-6. A simple list comprehension in Python
tweets = [ status['text'] for status in statuses ]
print tweets[0]
Let's run a few basic calculations on the data and compute its lexical diversity.
Example 1-7. Calculating lexical diversity for tweets
words = []
for t in tweets:
words += [ w for w in t.split() ]
# total words
print len(words)
# unique words
print len(set(words))
# lexical diversity
print 1.0*len(set(words))/len(words)
# avg words per tweet
print 1.0*sum([ len(t.split()) for t in tweets ])/len(tweets)
If you've already installed the nltk package, you can use it to compute a frequency distribution. (Although you may receive a warning or error message about PyYaml during installation for certain environments, it is probably the case that you can safely ignore this error.) Recall that to install a package, you can use easy_install or pip as follows:
$ easy_install nltk
$ pip install nltk
Example 1-9. Using NLTK to perform basic frequency analysis
import nltk
freq_dist = nltk.FreqDist(words)
print freq_dist.keys()[:50] # 50 most frequent tokens
print freq_dist.keys()[-50:] # 50 least frequent tokens
In case you're running Python 2.7, note that you can use the new collections.Counter class to effectively do the same thing.
from collections import Counter
counter = Counter(words)
print counter.most_common(50)
print counter.most_common()[-50:] # doesn't have a least_common method, so get them all and slice
Although there are some additional ways to find retweets based on Twitter's evolved API (see https://dev.twitter.com/docs/platform-objects/tweets for some ideas), one way that operates on the text of a tweet itself is in parsing out features of the text that provide clues that the status is a retweet. Regular expressions are a good approach for this problem.
*Example 1-10. Using regular expressions to find retweets*
import re
rt_patterns = re.compile(r"(RT|via)((?:\b\W*@\w+)+)", re.IGNORECASE)
example_tweets = ["RT @SocialWebMining Justin Bieber is on SNL 2nite. w00t?!?",
"Justin Bieber is on SNL 2nite. w00t?!? (via @SocialWebMining)"]
for t in example_tweets:
print rt_patterns.findall(t)
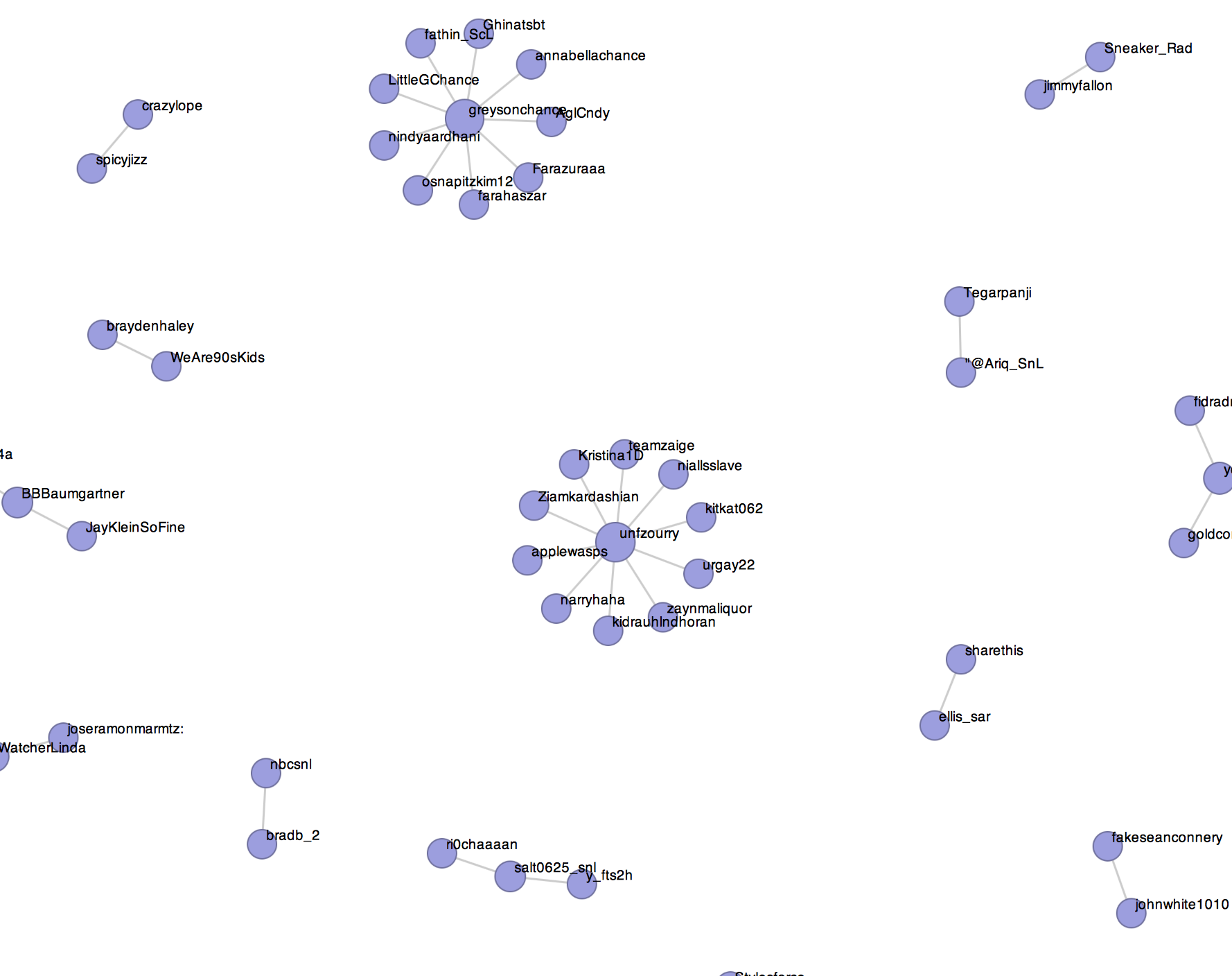
The possibilities with what you could do with Twitter data is endless. Here's some sample code that gets you started in building a graph of who retweeted whom that you could use as a starting point for further exploration.
*Example 1-11. Building and analyzing a graph describing who retweeted whom*
import networkx as nx
import re
g = nx.DiGraph()
def get_rt_sources(tweet):
rt_patterns = re.compile(r'(RT|via)((?:\b\W*@\w+)+)', re.IGNORECASE)
return [ source.strip()
for tuple in rt_patterns.findall(tweet)
for source in tuple
if source not in ("RT", "via") ]
for status in statuses:
rt_sources = get_rt_sources(status['text'])
if not rt_sources: continue
for rt_source in rt_sources:
g.add_edge(rt_source, status['user']['screen_name'], {'tweet_id' : status['id']})
print nx.info(g)
print g.edges(data=True)[0]
print len(nx.connected_components(g.to_undirected()))
print sorted(nx.degree(g).values())
In the Mining the Social Web's GitHub repository, there a thorough sample file that takes all of the concepts that have been presented and weaves them into a more comprehensive turn-key example and visualization. Visit https://github.com/ptwobrussell/Mining-the-Social-Web and, in particular, run the sample file located at https://github.com/ptwobrussell/Mining-the-Social-Web/blob/master/python_code/introduction__retweet_visualization.py which should automatically launch your web browser and provide you with an interactive visualization similar to the following: