Machine Learning and Optimization with Python
This part of the advanced tutorial focuses more on some specific packages. The topics covered in this part are:
- Easy and effective Machine Learning in Python with Scikit-Learn. Presented by Maruan Al-Shedivat.
- Optimization in Python with OpenOpt. Presented by Yiannis Hadjimichael.
Prerequisites: Basic and Intermediate tutorials or some experience with Python, Numpy, Scipy, Matplotlib (optional). Basic knowledge in machine learning and optimization.
1. Machine Learning in Python¶
Machine learning is a hot and popular topic nowadays. It is about building programs with tunable parameters that are adjusted automatically by adapting to previously seen data. It intervenes literally every sphere of our life ranging from science, engineering, and industry to economics, sociology, and even personal relationships. So if it is applicable everywhere, we need to have handy tools for doing machine learning.
# Start pylab inline mode, so figures will appear in the notebook
%pylab inline
1.1. Quick Overview of Scikit-Learn¶
Adapted from http://scikit-learn.org/stable/tutorial/basic/tutorial.html
# Load a dataset already available in scikit-learn
from sklearn import datasets
digits = datasets.load_digits()
type(digits)
digits.data
digits.target
from sklearn import svm
clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(digits.data[:-1], digits.target[:-1])
print "Original label:", digits.target[5]
print "Predicted label:", clf.predict(digits.data[5])
plt.figure(figsize=(3, 3))
plt.imshow(digits.images[5], interpolation='nearest', cmap=plt.cm.binary)
1.2. Data representation in Scikit-learn¶
Adapted from https://github.com/jakevdp/sklearn_scipy2013
Data in scikit-learn, with very few exceptions, is assumed to be stored as a two-dimensional array, of size [n_samples, n_features], and most of machine learning algorithms implemented in scikit-learn expect data to be stored this way.
- n_samples: The number of samples: each sample is an item to process (e.g. classify). A sample can be a document, a picture, a sound, a video, an astronomical object, a row in database or CSV file, or whatever you can describe with a fixed set of quantitative traits.
- n_features: The number of features or distinct traits that can be used to describe each item in a quantitative manner. Features are generally real-valued, but may be boolean or discrete-valued in some cases.
The number of features must be fixed in advance. However it can be very high dimensional (e.g. millions of features) with most of them being zeros for a given sample. This is a case where scipy.sparse matrices can be useful, in that they are much more memory-efficient than numpy arrays.
1.2.1. Example: iris dataset¶
To understand these simple concepts better, let's work with an example: iris-dataset.
# Don't know what iris is? Run this code to generate some pictures.
from IPython.core.display import Image, display
display(Image(filename='figures/iris_setosa.jpg'))
print "Iris Setosa\n"
display(Image(filename='figures/iris_versicolor.jpg'))
print "Iris Versicolor\n"
display(Image(filename='figures/iris_virginica.jpg'))
print "Iris Virginica"
# Load the dataset from scikit-learn
from sklearn.datasets import load_iris
iris = load_iris()
type(iris) # The resulting dataset is a Bunch object
iris.keys()
print iris.DESCR
# Number of samples and features
iris.data.shape
print "Number of samples:", iris.data.shape[0]
print "Number of features:", iris.data.shape[1]
print iris.data[0]
# Target (label) names
print iris.target_names
# Visualize the data
x_index = 0
y_index = 1
# this formatter will label the colorbar with the correct target names
formatter = plt.FuncFormatter(lambda i, *args: iris.target_names[int(i)])
plt.figure(figsize=(7, 5))
plt.scatter(iris.data[:, x_index], iris.data[:, y_index], c=iris.target)
plt.colorbar(ticks=[0, 1, 2], format=formatter)
plt.xlabel(iris.feature_names[x_index])
plt.ylabel(iris.feature_names[y_index])
Quick Exercise:
Change x_index and y_index and find the 2D projection of the data which maximally separate all three classes.
# your code goes here
1.2.2. Other available datasets¶
Scikit-learn makes available a host of datasets for testing learning algorithms. They come in three flavors:
- Packaged Data: these small datasets are packaged with the scikit-learn installation, and can be downloaded using the tools in
sklearn.datasets.load_* - Downloadable Data: these larger datasets are available for download, and scikit-learn includes tools which streamline this process. These tools can be found in
sklearn.datasets.fetch_* - Generated Data: there are several datasets which are generated from models based on a random seed. These are available in the
sklearn.datasets.make_*
# Where the downloaded datasets via fetch_scripts are stored
from sklearn.datasets import get_data_home
get_data_home()
# How to fetch an external dataset
from sklearn import datasets
Now you can type datasets.fetch_<TAB> and a list of available datasets will pop up.
Exercise:¶
Fetch the dataset olivetti_faces. Visualize various 2D projections for the data. Find the best in terms of separability.
from sklearn.datasets import fetch_olivetti_faces
# your code goes here
# fetch the faces data
# Use a script like above to plot the faces image data.
# Hint: plt.cm.bone is a good colormap for this data.
#%load solutions/sklearn_vis_data.py
1.3. Linear regression and classification¶
In this section, we explain how to use scikit-learn library for regression and classification. We discuss Estimator class - the base class for many of the scikit-learn models - and work through some examples.
from sklearn.datasets import load_boston
data = load_boston()
print data.DESCR
# Plot histogram for real estate prices
plt.hist(data.target)
plt.xlabel('price ($1000s)')
plt.ylabel('count')
Quick Exercise: Try sctter-plot several 2D projections of the data. What you can infer from the plots?
# your code goes here
Every algorithm is exposed in scikit-learn via an Estimator object. For instance a linear regression is:
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(data.data, data.target)
predicted = clf.predict(data.data)
# Plot the predicted price vs. true price
plt.scatter(data.target, predicted)
plt.plot([0, 50], [0, 50], '--k')
plt.axis('tight')
plt.xlabel('True price ($1000s)')
plt.ylabel('Predicted price ($1000s)')
Examples of regression type problems in machine learning:
- Sales: given consumer data, predict how much they will spend
- Advertising: given information about a user, predict the click-through rate for a web ad.
- Collaborative Filtering: given a collection of user-ratings for movies, predict preferences for other movies & users.
- Astronomy: given observations of galaxies, predict their mass or redshift
Another example of regularized linear regression on a synthetic data set.
import numpy as np
from sklearn.linear_model import LinearRegression
rng = np.random.RandomState(0)
x = 2 * rng.rand(100) - 1
f = lambda t: 1.2 * t ** 2 + .1 * t ** 3 - .4 * t ** 5 - .5 * t ** 9
y = f(x) + .4 * rng.normal(size=100)
plt.figure(figsize=(7, 5))
plt.scatter(x, y, s=4)
x_test = np.linspace(-1, 1, 100)
for k in [4, 9]:
X = np.array([x**i for i in range(k)]).T
X_test = np.array([x_test**i for i in range(k)]).T
order4 = LinearRegression()
order4.fit(X, y)
plt.plot(x_test, order4.predict(X_test), label='%i-th order'%(k))
plt.legend(loc='best')
plt.axis('tight')
plt.title('Fitting a 4th and a 9th order polynomial')
# Let's look at the ground truth
plt.figure()
plt.scatter(x, y, s=4)
plt.plot(x_test, f(x_test), label="truth")
plt.axis('tight')
plt.title('Ground truth (9th order polynomial)')
Let's use Ridge regression (with l1-norm regularization)
from sklearn.linear_model import Ridge
for k in [20]:
X = np.array([x**i for i in range(k)]).T
X_test = np.array([x_test**i for i in range(k)]).T
order4 = Ridge(alpha=0.3)
order4.fit(X, y)
plt.plot(x_test, order4.predict(X_test), label='%i-th order'%(k))
plt.plot(x_test, f(x_test), label="truth")
plt.scatter(x, y, s=4)
plt.legend(loc='best')
plt.axis('tight')
plt.title('Fitting a 4th and a 9th order polynomial')
plt.ylim?
Exercise:¶
For this exercise, you need to classify iris data with nearest neighbors classifier and with linear support vector classifier (LinearSVC).
In order to measure the performance, calculate the accuracy or just use clf.score function built-in into the Estimator object.
from __future__ import division # turn off division truncation -- division will be floating point by default
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
iris = load_iris()
# Splitting the data into train and test sets
indices = np.random.permutation(range(iris.data.shape[0]))
train_sz = floor(0.8*iris.data.shape[0])
X, y = iris.data[indices[:train_sz],:], iris.target[indices[:train_sz]]
Xt, yt = iris.data[indices[train_sz:],:], iris.target[indices[train_sz:]]
# your code goes here
#%load solutions/iris_classification.py
1.4. Approaches to validation and testing¶
It is usually an arduous and time consuming task to write cross-validation or other testing wrappers for your models. Scikit-learn allows you validate your models out-of-the-box. Let's have a look at how to do this.
from sklearn import cross_validation
X, Xt, y, yt = cross_validation.train_test_split(iris.data, iris.target, test_size=0.4, random_state=0)
print X.shape, y.shape
print Xt.shape, yt.shape
# Cross-validating your models in one line
scores = cross_validation.cross_val_score(svc, iris.data, iris.target, cv=5,)
print scores
print scores.mean()
cross_validation.cross_val_score?
# Calculate F1-measure (or any other score)
from sklearn import metrics
f1_scores = cross_validation.cross_val_score(svc, iris.data, iris.target, cv=5, scoring='f1')
print f1_scores
print f1_scores.mean()
Quick Exercise: Do the same CV-evaluation of the KNN classifier. Find the best number of nearest neighbors.
1.5. What to learn next?¶
If you would like to start using Scikit-learn for your machine learning tasks, the most right way is to jump into it and refer to the documentation from time to time. When you acquire enough skills in it, you can go and check out the following resources:
- A tutorial from PyCon 2013
- A tutorial from SciPy 2013 conference (check out the advanced track!)
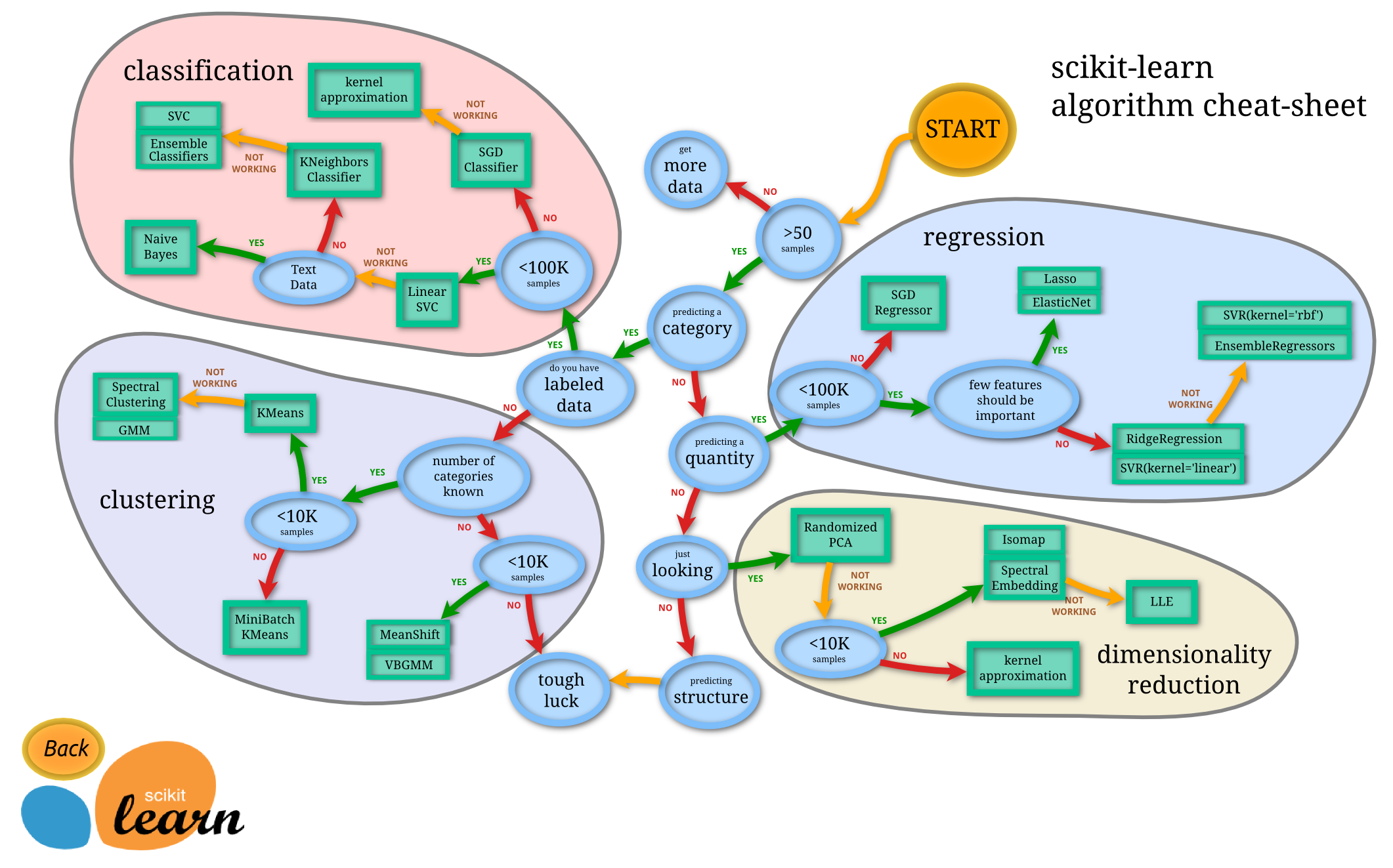
2. Optimization in Python with OpenOpt¶
In this part, we'll learn how to solve optimization problems using the OpenOpt package.
OpenOpt is a free-source package (under the license: BSD) for numerical optimization of a variety of linear, nonlinear problems, least-square problems, network and stochastic problems.
It contains more than 30 different solvers (both free and commercial) including solvers written in C and Fortran.
Some solvers are already included in the OpenOpt package (e.g. ralg,
gsubg, interalg) and other rely on other packagess
(e.g. scipy, IPOPT, ALGENCAN)
In this demonstration we are considering solvers existing in OpenOpt and SciPy. The library workstations have already OpenOpt installed and Scipy is included in the Python distribution. For instructions how to install OpenOpt on other machines go to: http://openopt.org/Install.
Acknowledgements:
- OpenOpt's website.
Optimization formulation¶
The general formulation of an optimization problem is to An optimization problem can be expressed in the following way:
- Given: a function $f : A \to R$ from some set $A$ to the set of real numbers
- Want to find a solution $x_0 \in A$ such that $f(x_0)$ is the minimum (or maximum) of $f(x)$ for all $x \in A$.
For example the standard form of a continuous optimization problem is:
$ \text{max (or min) } \mathbf{f(x)} $
$ \text{subject to } \\ $
$ \mathbf{lb} \le \mathbf{x} \le \mathbf{ub} \\ \mathbf{A x} \le \mathbf{b} \\ \mathbf{A}_\mathbf{eq} \mathbf{x} = \mathbf{b}_\mathbf{eq} \\ \mathbf{c_i(x) \le 0} \quad \forall i=0,...,I \\ \mathbf{h_j(x) = 0} \quad \forall i=0,...,J \\ \mathbf{x \in R^n} $
where $\mathbf{f, c_i, h_j} :R^n \to R$.
According to the type of the objective function $\mathbf{f(x)}$ and constraints the optimization problem is either linear, quadratic, nonlinear, unconstrained, constrained etc.
OpenOpt syntax¶
In OpenOpt optimization problems are assigned in the following way:
from openopt import NLP
or other constructor names: LP, MILP, QP, etc according to the problem
Then we use
p = NLP(*args, **kwargs)
to assign the constructor to object p.
Each constructor class has its own arguments
e.g. for NLP it is least f and x0, the objective function and the initial guess.
thus using
p = NLP(objfun, initialguess)
will assign objfun to f and initialguess to x0.
We can use
p.kwargs
to change any kwargs defined in the constructor.
Finally we solve the problem by
r = p.solve(nameOfSolver, otherParameters)
Object r contains all results, i.e. the minimizer, the objective function at solution and output parameters.
Adding OpenOpt path to PYTHONPATH¶
The best way to see how it works is to go through some examples.
But since OpenOpt is an additional package not included in the Python distribution we use first we need to include its path to the PYTHONPATH.
If you are using a library workstation this can be done in the notebook by running:
import sys
sys.path.append('/Library/Python/2.7/site-packages/openopt-0.52-py2.7.egg')
On other machines (Linux or Mac) add the following line in the .bashrc (Linux) or .bash_profile (Mac):
export OPENOPT=path-where-the-OOSuite-is
export PYTHONPATH=$PYTHONPATH:$OPENOPT
If you don't have such a file then create one.
Example 1 : Linear problem¶
A linear optimization problem has the following form:
$ \text{max (or min) } \mathbf{c}^T\mathbf{x} $
$ \text{subject to } \\ $
$ \mathbf{lb} \le \mathbf{x} \le \mathbf{ub} \\ \mathbf{A x} \le \mathbf{b} \\ \mathbf{A}_\mathbf{eq} \mathbf{x} = \mathbf{b}_\mathbf{eq} \\ \mathbf{x \in R^n} $
Consider the following problem adapted from OpenOpt examples on Linear Problems:
"""
Example:
Let's concider the problem
15x1 + 8x2 + 80x3 -> min (1)
subjected to
x1 + 2x2 + 3x3 <= 15 (2)
8x1 + 15x2 + 80x3 <= 80 (3)
8x1 + 80x2 + 15x3 <=150 (4)
-100x1 - 10x2 - x3 <= -800 (5)
80x1 + 8x2 + 15x3 = 750 (6)
x1 + 10x2 + 100x3 = 80 (7)
x1 >= 4 (8)
-8 >= x2 >= -80 (9)
"""
from numpy import *
from openopt import LP
f = array([15, 8, 80])
A = array([[1, 2, 3], [8, 15, 80], [8, 80, 15], [-100, -10, -1]])
b = array([15, 80, 150, -800])
Aeq = array([[80, 8, 15], [1, 10, 100]])
beq = array([750, 80])
lb = array([4, -80, -inf])
ub = array([inf, -8, inf])
p = LP(f, A=A, Aeq=Aeq, b=b, beq=beq, lb=lb, ub=ub)
#or p = LP(f=f, A=A, Aeq=Aeq, b=b, beq=beq, lb=lb, ub=ub)
#r = p.minimize('glpk') # CVXOPT must be installed
#r = p.minimize('lpSolve') # lpsolve must be installed
r = p.minimize('pclp')
#search for max: r = p.maximize('glpk') # CVXOPT & glpk must be installed
print('objFunValue: %f' % r.ff) # should print 204.48841578
print('x_opt: %s' % r.xf) # should print [ 9.89355041 -8. 1.5010645 ]
We can easily verify that solution satisfies the constraints:
import numpy as np
print np.linalg.norm(np.dot(Aeq,r.xf)- beq)
print np.dot(A,r.xf)- b <= 0
Example 2: Solving nonlinear equations¶
Solving nonlinear equations can be formulated as minimizing the 2-norm of the vector of equations.
Below is a script solving a system of three equations (from OpenOpt examples on Non-linear least squares).
"""
Let us solve the overdetermined nonlinear equations:
a^2 + b^2 = 15
a^4 + b^4 = 100
a = 3.5
Let us concider the problem as
x[0]**2 + x[1]**2 - 15 = 0
x[0]**4 + x[1]**4 - 100 = 0
x[0] - 3.5 = 0
Now we will solve the one using solver scipy_leastsq
"""
%pylab inline --no-import-all
from openopt import NLLSP
from openopt import NLP
f = lambda x: ((x**2).sum() - 15, (x**4).sum() - 100, x[0]-3.5)
# other possible f assignments:
# f = lambda x: [(x**2).sum() - 15, (x**4).sum() - 100, x[0]-3.5]
#f = [lambda x: (x**2).sum() - 15, lambda x: (x**4).sum() - 100, lambda x: x[0]-3.5]
# f = (lambda x: (x**2).sum() - 15, lambda x: (x**4).sum() - 100, lambda x: x[0]-3.5)
# f = lambda x: asfarray(((x**2).sum() - 15, (x**4).sum() - 100, x[0]-3.5))
#optional: gradient
def df(x):
r = zeros((3,2))
r[0,0] = 2*x[0]
r[0,1] = 2*x[1]
r[1,0] = 4*x[0]**3
r[1,1] = 4*x[1]**3
r[2,0] = 1
return r
# init esimation of solution - sometimes rather pricise one is very important
x0 = [1.5, 8]
#p = NLLSP(f, x0, diffInt = 1.5e-8, xtol = 1.5e-8, ftol = 1.5e-8)
# or
# p = NLLSP(f, x0)
# or
p = NLLSP(f, x0, xtol = 1.5e-8, ftol = 1.5e-8)
#optional: user-supplied gradient check:
#p.checkdf() # requires DerApproximator to be installed
r = p.solve('scipy_leastsq', plot=1, iprint = 1)
print 'x_opt:', r.xf # 2.74930862, +/-2.5597651
print 'funcs Values:', p.f(r.xf) # [-0.888904734668, 0.0678251418575, -0.750691380965]
print 'f_opt:', r.ff, '; sum of squares (should be same value):', (p.f(r.xf) ** 2).sum() # 1.35828942657
Example 3: Least square problem¶
Consider some 2D data. We would like to find a model to the measured data that minimizes the discrepancy between model predictions and the data. This can be formulated by minimizing the sum of the squares of the difference between values of model and measured data.
First create some data and plot them:
import matplotlib.pyplot as plt
n = 200
X = np.linspace(0,2,n)
m = lambda X : 0.8*np.exp(-1.5*X)+1.2*np.exp(-0.8*X)
perturb = 0.2*np.random.uniform(0,1,n)
Y = m(X)*(1.0+perturb)
plt.figure(figsize=(15,10), dpi=100) # changing figure's shape
plt.plot(X,Y,'.')
plt.xlabel('$X$',fontsize=16) # horizontal axis name
plt.ylabel('Y',fontsize=16) # vertical axis name
plt.title('Sample data',fontsize=18) # title
plt.grid(True) # enabling grid
Now let's solve the least square problem:
"""
In the DFP example we will search for z=(a, b, c, d)
that minimizes Sum_i || F(z, X_i) - Y_i ||^2
for the function
F(x) = a*exp(-b*x) + c*exp(-d*x)
"""
from openopt import DFP
f = lambda z, X: z[0]*exp(-z[1]*X[0]) + z[2]*exp(-z[3]*X[0])
initEstimation = [0.2, 0.9, 1.9, 0.9]
lb = [-np.inf, -np.inf, -np.inf, -np.inf]
ub = [np.inf, np.inf, np.inf, np.inf]
p = DFP(f, initEstimation, X, Y, lb=lb, ub=ub)
p.df = lambda z, X: [exp(-z[1]*X[0]), -z[0]*z[1]*exp(-z[1]*X[0]), exp(-z[3]*X[0]), -z[2]*z[3]*exp(-z[3]*X[0])]
r = p.solve('nlp:ralg', plot=1, iprint = 10)
f = lambda z, X: z[0]*exp(-z[1]*X) + z[2]*exp(-z[3]*X)
print('solution: '+str(r.xf)+'\n||residuals||^2 = '+str(r.ff))
fun = lambda z, X: z[0]*exp(-z[1]*X) + z[2]*exp(-z[3]*X)
plt.figure(figsize=(15,10), dpi=100) # changing figure's shape
plt.plot(X,Y,'.')
plt.plot(X,fun(r.xf,X),'r-',linewidth=1.5)
plt.xlabel('$X$',fontsize=16) # horizontal axis name
plt.ylabel('Y',fontsize=16) # vertical axis name
plt.title('Sample data',fontsize=18) # title
plt.grid(True) # enabling grid
Example 4: Nonlinear problem¶
Finally, the following is an example of a non-linear problem (from OpenOpt non-linear examples) as described at the beginning of this part.
"""
Example:
(x0-5)^2 + (x2-5)^2 + ... +(x149-5)^2 -> min
subjected to
# lb<= x <= ub:
x4 <= 4
8 <= x5 <= 15
# Ax <= b
x0+...+x149 >= 825
x9 + x19 <= 3
x10+x11 <= 9
# Aeq x = beq
x100+x101 = 11
# c(x) <= 0
2*x0^4-32 <= 0
x1^2+x2^2-8 <= 0
# h(x) = 0
(x[149]-1)**6 = 0
(x[148]-1.5)**6 = 0
"""
from openopt import NLP
from numpy import cos, arange, ones, asarray, zeros, mat, array
N = 150
# objective function:
f = lambda x: ((x-5)**2).sum()
# objective function gradient (optional):
df = lambda x: 2*(x-5)
# start point (initial estimation)
x0 = 8*cos(arange(N))
# c(x) <= 0 constraints
c = [lambda x: 2* x[0] **4-32, lambda x: x[1]**2+x[2]**2 - 8]
# dc(x)/dx: non-lin ineq constraints gradients (optional):
dc0 = lambda x: [8 * x[0]**3] + [0]*(N-1)
dc1 = lambda x: [0, 2 * x[1], 2 * x[2]] + [0]*(N-3)
dc = [dc0, dc1]
# h(x) = 0 constraints
def h(x):
return (x[N-1]-1)**6, (x[N-2]-1.5)**6
# other possible return types: numpy array, matrix, Python list, tuple
# or just h = lambda x: [(x[149]-1)**6, (x[148]-1.5)**6]
# dh(x)/dx: non-lin eq constraints gradients (optional):
def dh(x):
r = zeros((2, N))
r[0, -1] = 6*(x[N-1]-1)**5
r[1, -2] = 6*(x[N-2]-1.5)**5
return r
# lower and upper bounds on variables
lb = -6*ones(N)
ub = 6*ones(N)
ub[4] = 4
lb[5], ub[5] = 8, 15
# general linear inequality constraints
A = zeros((3, N))
A[0, 9] = 1
A[0, 19] = 1
A[1, 10:12] = 1
A[2] = -ones(N)
b = [7, 9, -825]
# general linear equality constraints
Aeq = zeros(N)
Aeq[100:102] = 1
beq = 11
# required constraints tolerance, default for NLP is 1e-6
contol = 1e-7
# If you use solver algencan, NB! - it ignores xtol and ftol; using maxTime, maxCPUTime, maxIter, maxFunEvals, fEnough is recommended.
# Note that in algencan gtol means norm of projected gradient of the Augmented Lagrangian
# so it should be something like 1e-3...1e-5
gtol = 1e-7 # (default gtol = 1e-6)
# Assign problem:
# 1st arg - objective function
# 2nd arg - start point
p = NLP(f, x0, df=df, c=c, dc=dc, h=h, dh=dh, A=A, b=b, Aeq=Aeq, beq=beq,
lb=lb, ub=ub, gtol=gtol, contol=contol, iprint = 50, maxIter = 10000, maxFunEvals = 1e7, name = 'NLP_1')
#optional: graphic output, requires pylab (matplotlib)
p.plot = True
solver = 'ralg'
#solver = 'scipy_slsqp'
# solve the problem
r = p.solve(solver, plot=1) # string argument is solver name
# r.xf and r.ff are optim point and optim objFun value
# r.ff should be something like 132.05
print r.ff
Copyright 2014, Maruan Al-Shedivat and Yiannis Hadjimichael, ACM Student Chapter Members.