
Course of talk¶
- What is Stream processing and it's challenges !
- How Apache storm fits in !
- Getting to know components of Apache Storm !
- Apache Storm with Python !
- Wikipedia edit logs : Building a working topology in Python
- Need for Kafka ?
- Advanced features of Storm !
- Monitoring and Deployment !
- Resources and Guides !
Stream processing framework challenges :¶
" Stream processing frameworks are not only for real-time computation but an infrastructure for never ending continuous data processing "
- They are essentially abstraction over messaging systems that address variety of challenges and use-cases.
- Store message while consumers consume it, replay them, multiple consumers for same messages.
- Configuring what message goes where, how to deploy / parallelize workers.
- Fault-Tolerance :
- Making sure workers and Queues are always up.
- If worker machine goes down, make sure message is treated as unprocessed.
- Incase workers goes down, what happens to the counts / messages.
- What if the underlying messaging system sends you the same message twice or loses a message ? : Both the scenarios will account for incorrect counts.
- Scaling for high-throughput.
- From what point should the processor run when it restarts.
- What if you want to count grouped by the key, eg: group by user id.
- Distribute the computation across multiple machines when single machine is not able to handle.
How storm fits in :¶
- Extremely broad set of use cases
- Scalable
- Guarantees no data loss
- Extremely robust
- Fault-tolerant
- Programming language agnostic
- Achieve parallelism across components.
Extremely broad set of use cases: Storm can be used for processing messages and updating databases (stream processing), doing a continuous query on data streams and streaming the results into clients (continuous computation), parallelizing an intense query like a search query on the fly (distributed RPC), and more. Storm’s small set of primitives satisfy a stunning number of use cases.
Scalable: Storm scales to massive numbers of messages per second. To scale a topology, all you have to do is add machines and increase the parallelism settings of the topology. As an example of Storm’s scale, one of Storm’s initial applications processed 1,000,000 messages per second on a 10 node cluster, including hundreds of database calls per second as part of the topology. Storm’s usage of Zookeeper for cluster coordination makes it scale to much larger cluster sizes.
Guarantees no data loss: A realtime system must have strong guarantees about data being successfully processed. A system that drops data has a very limited set of use cases. Storm guarantees that every message will be processed, and this is in direct contrast with other systems like S4.
Extremely robust: Unlike systems like Hadoop, which are notorious for being difficult to manage, Storm clusters just work. It is an explicit goal of the Storm project to make the user experience of managing Storm clusters as painless as possible.
Fault-tolerant: If there are faults during execution of your computation, Storm will reassign tasks as necessary. Storm makes sure that a computation can run forever (or until you kill the computation).
Programming language agnostic: Robust and scalable realtime processing shouldn’t be limited to a single platform. Storm topologies and processing components can be defined in any language, making Storm accessible to nearly anyone.
Achieve parallelism across components.
Storm Components:¶
Conceptual view
- Stream
- Spout
- Bolts
- Topology
Physical View
- Nimbus
- ZoopKeeper
- Supervisor
- Storm-UI
SPOUT¶
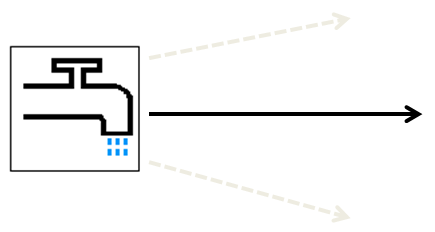
import itertools
from streamparse.spout import Spout
class SentenceSpout(Spout):
def initialize(self, stormconf, context):
self.sentences = [
"She advised him to take a long holiday, so he immediately quit work and took a trip around the world",
"I was very glad to get a present from her",
"He will be here in half an hour",
"She saw him eating a sandwich",
]
self.sentences = itertools.cycle(self.sentences)
def next_tuple(self):
sentence = next(self.sentences)
self.emit([sentence])
def ack(self, tup_id):
pass # if a tuple is processed properly, do nothing
def fail(self, tup_id):
pass # if a tuple fails to process, do nothing
if __name__ == '__main__':
SentenceSpout().run()
Stream¶

Bolt¶
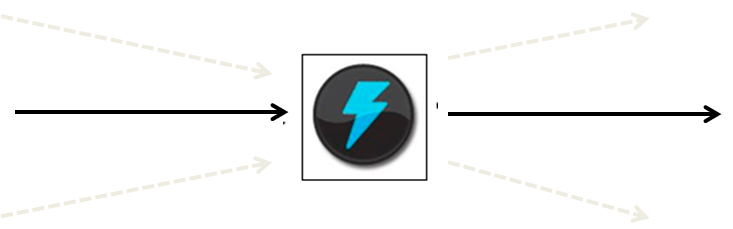
import re
from streamparse.bolt import Bolt
class SentenceSplitterBolt(Bolt):
def process(self, tup):
sentence = tup.values[0] # extract the sentence
sentence = re.sub(r"[,.;!\?]", "", sentence) # get rid of punctuation
words = [[word.strip()] for word in sentence.split(" ") if word.strip()]
if not words:
# no words to process in the sentence, fail the tuple
self.fail(tup)
return
self.emit_many(words)
self.ack(tup) # tell Storm the tuple has been processed successfully
if __name__ == '__main__':
SentenceSplitterBolt().run()
Topology¶
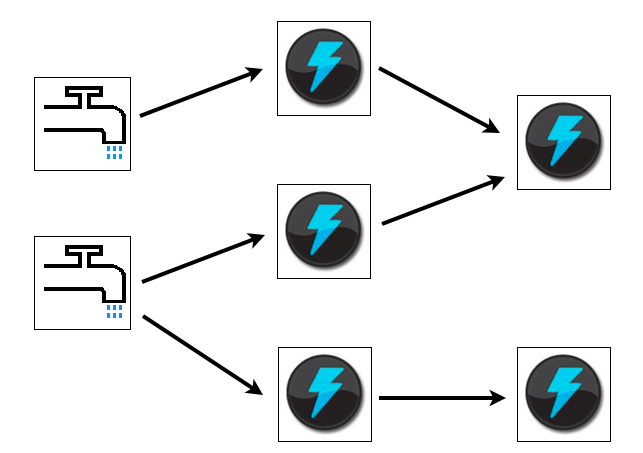
{"sentence-splitter" (shell-bolt-spec
;; inputs, where does this bolt recieve it's tuples from?
{"word-spout-1" :shuffle
}
;; command to run
["python" "sentence_splitter.py"]
;; output spec, what tuples does this bolt emit?
["word"]
;; configuration parameters
:p 2)
"word-counter" (shell-bolt-spec
;; recieves tuples from "sentence-splitter", grouped by word
{"sentence-splitter" ["word"]}
["python" "word_counter.py"]
["word" "count"])
"word-count-saver" (shell-bolt-spec
{"word-counter" :shuffle}
["python" "word_saver.py"]
;; does not emit any fields
[])}
** Grouping **
How that stream should be partitioned among the bolt’s tasks.
There are variety of ways you can use, but the most common one's used are :
- Shuffle grouping
- Fields grouping
Note: For detailed list please refer to URL : http://storm.incubator.apache.org/documentation/Concepts.html#stream-groupings
** Physical View **
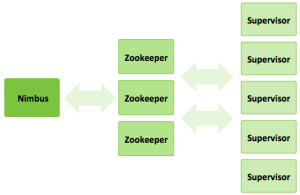
- Nimbus node :
- Manage, Monitor, coordinate topologies running on the cluster.
- Deployment of topology.
- Task assignment and re-assignment in case of failure.
- ZooKeeper nodes – coordinates the Storm cluster
- Supervisor nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus
Storm & Python¶
- StreamParse
- Petrel
- Integration using Jython
- Native multilang topology.
My <3 for StreamParse¶
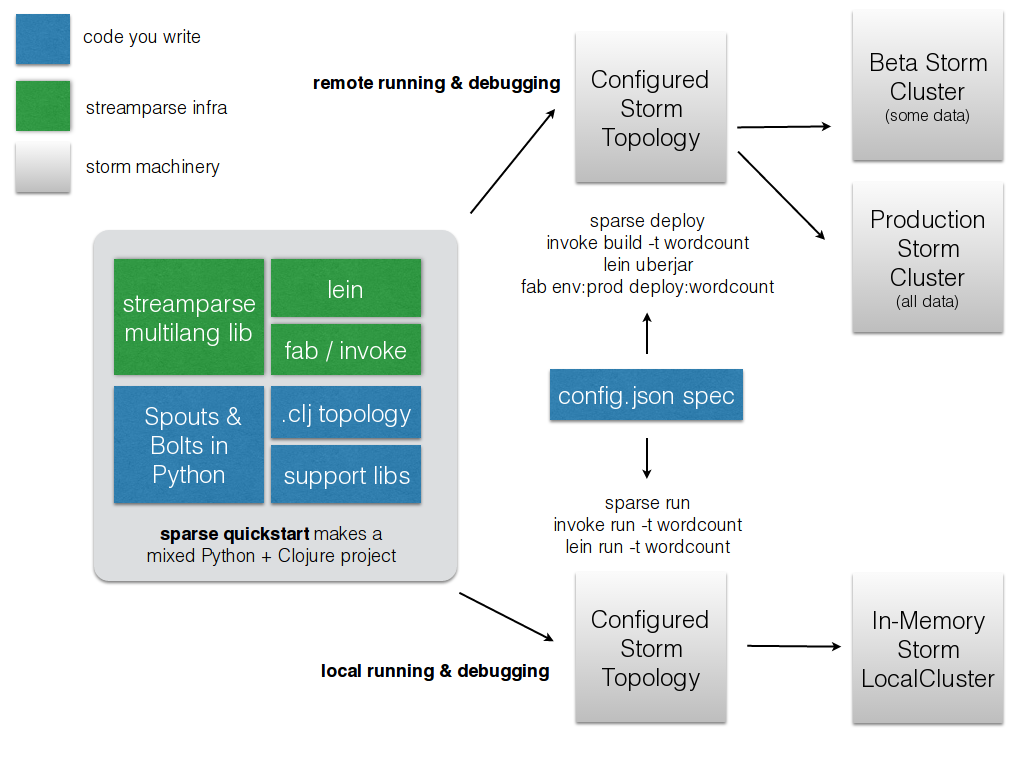
- Clean project layout
| File/Folder | Contents |
|---|---|
| config.json | Configuration information for all of your topologies. |
| fabfile.py | Optional custom fabric tasks. |
| project.clj | leiningen project file, can be used to add external JVM dependencies |
| src/ | Python source files (bolts/spouts/etc.) for topologies. |
| tasks.py | Optional custom invoke tasks. |
| topologies/ | Contains topology definitions written using the Clojure DSL for Storm. |
| virtualenvs/ | Contains pip requirements files in order to install dependencies on remote Storm servers. |
#DSL for defining topologies
#----------------------------
(ns wordcount
(:use [backtype.storm.clojure])
(:gen-class))
(def wordcount
[
;; spout configuration
{"word-spout" (shell-spout-spec
["python" "words.py"]
["word"]
)
}
;; bolt configuration
{"count-bolt" (shell-bolt-spec
{"word-spout" :shuffle}
["python" "wordcount.py"]
["word" "count"]
:p 2
)
}
]
)
** Enough of talking, now let's build something. **
Wikipedia edit trends¶
- Human vs Bots.
- LoggedIN vs Anonymous.
- Action wise split.
Sample message
--------------
{
"action": "edit",
"change_size": 98,
"flags": null,
"is_anon": false,
"is_bot": false,
"is_minor": false,
"is_new": false,
"is_unpatrolled": false,
"ns": "Main",
"page_title": "Abu Bakr al-Baghdadi",
"parent_rev_id": "615788913",
"rev_id": "615784505",
"summary": "/* As Caliph of the Islamic State */ this should have pointed out that some sources deny this was al-Baghdadi - Wikipedia cannot say in its own voice that this is genuine while it is contested",
"url": "http://en.wikipedia.org/w/index.php?diff=615788913&oldid=615784505",
"user": "Dougweller"
}
[user@localhost opt]# sparse quickstart wikipedia_editLogs_trends
%%bash
cd /opt/wikipedia_editLogs_trends/
ls
_build config.json fabfile.py log-cleaner.log project.clj README.md _resources src tasks.py topologies virtualenvs zookeeper.out
#src/KafkaSpout.py
from streamparse.spout import Spout
from kafka.client import KafkaClient
from kafka.consumer import SimpleConsumer
class KafkaSpout(Spout):
def initialize(self, stormconf, context):
self.kafka = KafkaClient('127.0.0.1:9092')
self.consumer = SimpleConsumer(self.kafka,"SpoutTopologyGroup","WikiPediaLogs")
def next_tuple(self):
for message in self.consumer:
self.emit([message])
if __name__ == '__main__':
KafkaSpout().run()
#src/ParseJson.py
from collections import Counter
from streamparse.bolt import Bolt
import json
import time
class ParseJson(Bolt):
def initialize(self, conf, ctx):
self.counts = Counter()
def process(self, tup):
# Few castings
null = ""
true = True
false = False
##Main Logic
list_words = []
json_object = json.loads(str(tup.values[0]))
action_str = "g2_" + str(json_object['action'])
list_words.append([action_str])
##Bot or Not
if json_object['is_bot']:
list_words.append(["bot"])
else:
list_words.append(["human"])
##Anon or LoggedIN
if json_object['is_anon']:
list_words.append(["g3_Anon"])
else:
list_words.append(["g3_LoggedIN"])
self.emit_many(list_words)
if __name__ == '__main__':
ParseJson().run()
#src/Counts
from collections import Counter
from collections import defaultdict
from streamparse.bolt import Bolt
from websocket import create_connection
import json
import time
class WordCounter(Bolt):
def initialize(self, conf, ctx):
#self.counts = Counter()
self.counts = defaultdict(int)
self.ws = create_connection("ws://localhost:2546")
def process(self, tup):
word = tup.values[0]
self.counts[word] += 1
self.ws.send(json.dumps(self.counts))
self.emit([word,self.counts[word]])
if __name__ == '__main__':
WordCounter().run()
#Topology
(ns wikipediaEditLogs
(:use [backtype.storm.clojure])
(:gen-class))
(def wordcount
[
;; spout configuration
{"kafka-spout" (shell-spout-spec
["python" "KafkaSpout.py"]
["word"]
)
}
;; bolt configuration
{"parse-bolt" (shell-bolt-spec
{"kafka-spout" :shuffle}
["python" "ParseJson.py"]
["word"]
:p 2
)
;; bolt configuration
"count-bolt" (shell-bolt-spec
{"parse-bolt" ["word"]}
["python" "wordcount.py"]
["word" "count"]
:p 2
)
}
]
)
[user@localhost opt]# sparse run
[user@localhost opt]# sparse submit --name topology_name
Need for Kafka¶
- Kafka is a High-Throughput, Distributed, Persistent Messaging (Publish-Subscribe) system.
- Let's you think in a log-centric way.
Important-Concepts¶
- Cluster: Set of brokers
- Broker : Individual node in the cluster
- Topic : Group of related messages
- Partition: part of topic, used for replication
- offset : Point from where consumer needs to read.
Rethinking how logs work¶
Kafka with Python¶
- python-kafka
- Samsa
- Kafka + Storm
Advanced features of Storm¶
- DRPC
- Transacational topologies
- Trident topologies
Resources¶
- streamparse : https://github.com/Parsely/streamparse
- Storm official docs : https://storm.incubator.apache.org/
- Kafka offical docs : http://kafka.apache.org/
- Python Kafka libraries :
- kafka-python : https://github.com/mumrah/kafka-python
- samsa : https://github.com/mumrah/kafka-python
- Other interesting reads:
- Understanding storm paralleism : http://www.michael-noll.com/blog/2012/10/16/understanding-the-parallelism-of-a-storm-topology/