Overfitting, revisited¶
What is overfitting? Here are a few ways of explaining it:
- Building a model that matches the training set too closely.
- Building a model that does well on the training data, but doesn't generalize to out-of-sample data.
- Learning from the noise in the data, rather than just the signal.
Overfitting¶
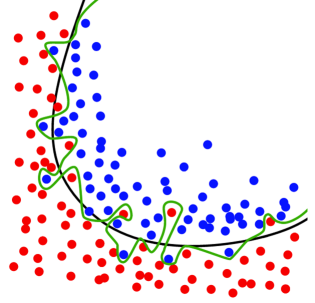
Underfitting vs Overfitting¶
What are some ways to overfit the data?
- Train and test on the same data
- Create a model that is overly complex (one that doesn't generalize well)
- Example: KNN in which K is too low
- Example: Decision tree that is grown too deep
An overly complex model has low bias but high variance.
Linear Regression, revisited¶
Question: Are linear regression models high bias/low variance, or low bias/high variance?
Answer: High bias/low variance (generally speaking)
Great! So as long as we don't train and test on the same data, we don't have to worry about overfitting, right? Not so fast....
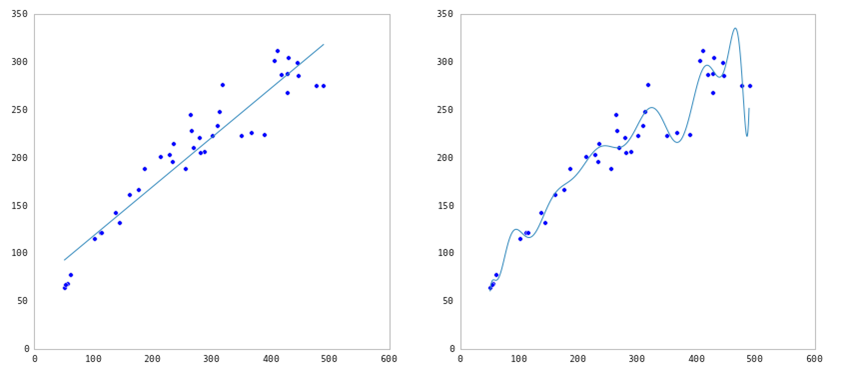
Overfitting with Linear Regression (part 1)¶
Linear models can overfit if you include irrelevant features.
Question: Why would that be the case?
Answer: Because it will learn a coefficient for any feature you feed into the model, regardless of whether that feature has the signal or the noise.
This is especially a problem when p (number of features) is close to n (number of observations), because that model will naturally have high variance.
Overfitting with Linear Regression (part 2)¶
Linear models can also overfit when the included features are highly correlated. From the scikit-learn documentation:
"...coefficient estimates for Ordinary Least Squares rely on the independence of the model terms. When terms are correlated and the columns of the design matrix X have an approximate linear dependence, the design matrix becomes close to singular and as a result, the least-squares estimate becomes highly sensitive to random errors in the observed response, producing a large variance."
Overfitting with Linear Regression (part 3)¶
Linear models can also overfit if the coefficients are too large.
Question: Why would that be the case?
Answer: Because the larger the absolute value of the coefficient, the more power it has to change the predicted response. Thus it tends toward high variance, which can result in overfitting.
Regularization¶
Regularization is a method for "constraining" or "regularizing" the size of the coefficients, thus "shrinking" them towards zero. It tends to reduce variance more than it increases bias, and thus minimizes overfitting.
Common regularization techniques for linear models:
- Ridge regression (also known as "L2 regularization"): shrinks coefficients toward zero (but they never reach zero)
- Lasso regularization (also known as "L1 regularization"): shrinks coefficients all the way to zero
- ElasticNet regularization: balance between Ridge and Lasso
Lasso regularization is useful if we believe many features are irrelevant, since a feature with a zero coefficient is essentially removed from the model. Thus, it is a useful technique for feature selection.
How does regularization work?
- A tuning parameter alpha (or sometimes lambda) imposes a penalty on the size of coefficients.
- Instead of minimizing the "loss function" (mean squared error), it minimizes the "loss plus penalty".
- A tiny alpha imposes no penalty on the coefficient size, and is equivalent to a normal linear model.
- Increasing the alpha penalizes the coefficients and shrinks them toward zero.
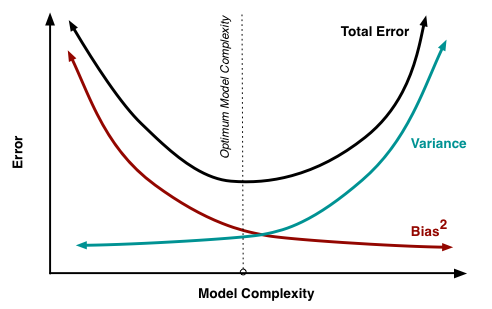
Bias-variance trade-off¶
Our goal is to locate the optimum model complexity, and thus regularization is useful when we believe our model is too complex.
Standardizing features¶
It's usually recommended to standardize your features when using regularization.
Question: Why would that be the case?
Answer: If you don't standardize, features would be penalized simply because of their scale. Also, standardizing avoids penalizing the intercept (which wouldn't make intuitive sense).
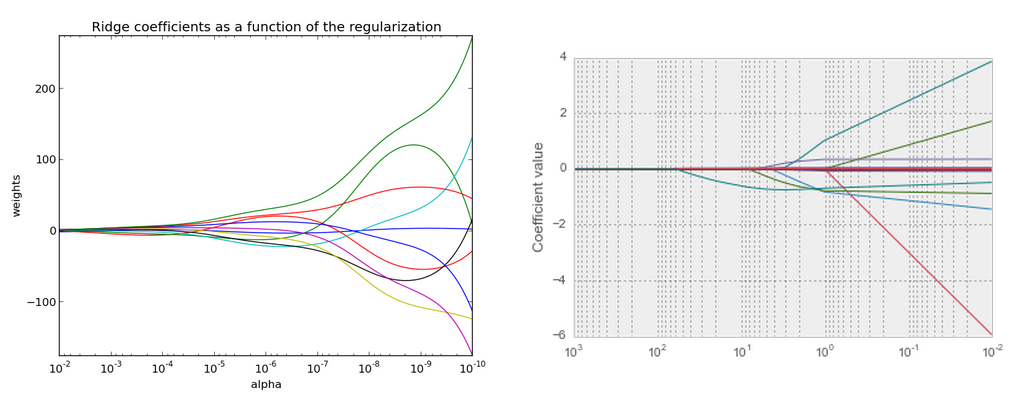
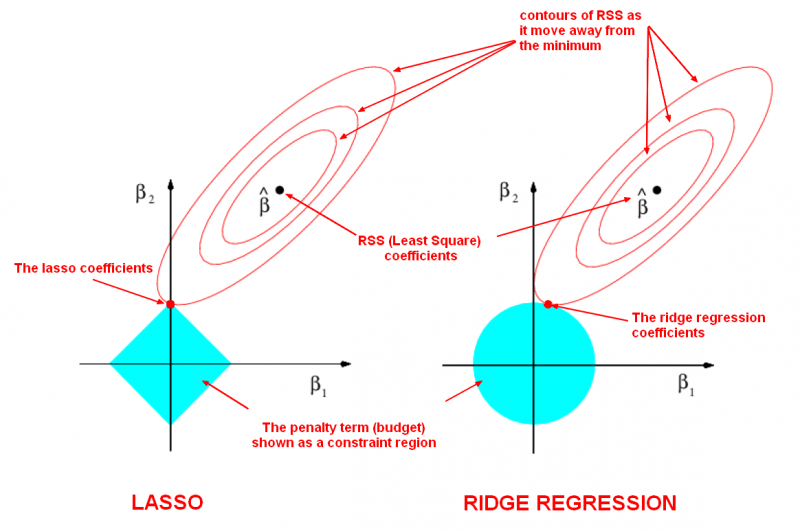
Ridge vs Lasso Coefficient Plots¶
Below is a visualization of what happens when you apply regularization. The general idea is that you are restricting the "space" in which your coefficients can be fit. This means you are shriking the coefficient space. You still want the coefficients that give the "best" model (as determined by you metric, e.g. RMSE, accuracy, AUC, etc), but you are restricting the area in which you can evaluate coefficients.
In this specific image, we are fitting a model with two predictors, B1 and B2. The x-axis shows B1 and the y-axis shows B2. There is a third dimension here, our evaluation metric. For the sake of example, we can assume this is linear regression, so we are trying to minimize our Root Mean Squared Error (RMSE). B-hat represents the set of coefficients, B1 and B2, where RMSE is minimized. While this is the "best" model according to our criterion, we've imposed a penalty that restricts the coefficients to the blue box. So we want to find the point (representing two coeffcients B1 and B2) where RMSE is minimized within our blue box. Technically, the RMSE will be higher here, but it will be the lowest within our penalized box. Due to the shape or space for the regression problem and the shape of our penalty box, many of the "optimal" coefficients will be close to zero for Ridge Regression and exactly zero for LASSO Regression.
Ridge vs Lasso path diagrams¶
Larger alpha (on the left here) means more regularization, which means more coefficients close to zero.