Document Clustering with Python¶
In this guide, I will explain how to cluster a set of documents using Python. My motivating example is to identify the latent structures within the synopses of the top 100 films of all time (per an IMDB list). See the original post for a more detailed discussion on the example. This guide covers:
- tokenizing and stemming each synopsis
- transforming the corpus into vector space using [tf-idf](http://en.wikipedia.org/wiki/Tf%E2%80%93idf)
- calculating cosine distance between each document as a measure of similarity
- clustering the documents using the [k-means algorithm](http://en.wikipedia.org/wiki/K-means_clustering)
- using [multidimensional scaling](http://en.wikipedia.org/wiki/Multidimensional_scaling) to reduce dimensionality within the corpus
- plotting the clustering output using [matplotlib](http://matplotlib.org/) and [mpld3](http://mpld3.github.io/)
- conducting a hierarchical clustering on the corpus using [Ward clustering](http://en.wikipedia.org/wiki/Ward%27s_method)
- plotting a Ward dendrogram
- topic modeling using [Latent Dirichlet Allocation (LDA)](http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation)
Contents¶
- [Stopwords, stemming, and tokenization](#Stopwords,-stemming,-and-tokenizing)
- [Tf-idf and document similarity](#Tf-idf-and-document-similarity)
- [K-means clustering](#K-means-clustering)
- [Multidimensional scaling](#Multidimensional-scaling)
- [Visualizing document clusters](#Visualizing-document-clusters)
- [Hierarchical document clustering](#Hierarchical-document-clustering)
- [Latent Dirichlet Allocation (LDA)](#Latent-Dirichlet-Allocation)
But first, I import everything I am going to need up front
import numpy as np
import pandas as pd
import nltk
from bs4 import BeautifulSoup
import re
import os
import codecs
from sklearn import feature_extraction
import mpld3
Stopwords, stemming, and tokenizing¶
#import three lists: titles, links and wikipedia synopses
titles = open('title_list.txt').read().split('\n')
#ensures that only the first 100 are read in
titles = titles[:100]
links = open('link_list_imdb.txt').read().split('\n')
links = links[:100]
synopses_wiki = open('synopses_list_wiki.txt').read().split('\n BREAKS HERE')
synopses_wiki = synopses_wiki[:100]
synopses_clean_wiki = []
for text in synopses_wiki:
text = BeautifulSoup(text, 'html.parser').getText()
#strips html formatting and converts to unicode
synopses_clean_wiki.append(text)
synopses_wiki = synopses_clean_wiki
genres = open('genres_list.txt').read().split('\n')
genres = genres[:100]
print(str(len(titles)) + ' titles')
print(str(len(links)) + ' links')
print(str(len(synopses_wiki)) + ' synopses')
print(str(len(genres)) + ' genres')
100 titles 100 links 100 synopses 100 genres
synopses_imdb = open('synopses_list_imdb.txt').read().split('\n BREAKS HERE')
synopses_imdb = synopses_imdb[:100]
synopses_clean_imdb = []
for text in synopses_imdb:
text = BeautifulSoup(text, 'html.parser').getText()
#strips html formatting and converts to unicode
synopses_clean_imdb.append(text)
synopses_imdb = synopses_clean_imdb
synopses = []
for i in range(len(synopses_wiki)):
item = synopses_wiki[i] + synopses_imdb[i]
synopses.append(item)
# generates index for each item in the corpora (in this case it's just rank) and I'll use this for scoring later
ranks = []
for i in range(0,len(titles)):
ranks.append(i)
This section is focused on defining some functions to manipulate the synopses. First, I load NLTK's list of English stop words. Stop words are words like "a", "the", or "in" which don't convey significant meaning. I'm sure there are much better explanations of this out there.
# load nltk's English stopwords as variable called 'stopwords'
stopwords = nltk.corpus.stopwords.words('english')
Next I import the Snowball Stemmer which is actually part of NLTK. Stemming is just the process of breaking a word down into its root.
# load nltk's SnowballStemmer as variabled 'stemmer'
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("english")
Below I define two functions:
- *tokenize_and_stem*: tokenizes (splits the synopsis into a list of its respective words (or tokens) and also stems each token
- *tokenize_only*: tokenizes the synopsis only
I use both these functions to create a dictionary which becomes important in case I want to use stems for an algorithm, but later convert stems back to their full words for presentation purposes. Guess what, I do want to do that!
# here I define a tokenizer and stemmer which returns the set of stems in the text that it is passed
def tokenize_and_stem(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
stems = [stemmer.stem(t) for t in filtered_tokens]
return stems
def tokenize_only(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word.lower() for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
return filtered_tokens
Below I use my stemming/tokenizing and tokenizing functions to iterate over the list of synopses to create two vocabularies: one stemmed and one only tokenized.
totalvocab_stemmed = []
totalvocab_tokenized = []
for i in synopses:
allwords_stemmed = tokenize_and_stem(i)
totalvocab_stemmed.extend(allwords_stemmed)
allwords_tokenized = tokenize_only(i)
totalvocab_tokenized.extend(allwords_tokenized)
Using these two lists, I create a pandas DataFrame with the stemmed vocabulary as the index and the tokenized words as the column. The benefit of this is it provides an efficient way to look up a stem and return a full token. The downside here is that stems to tokens are one to many: the stem 'run' could be associated with 'ran', 'runs', 'running', etc. For my purposes this is fine--I'm perfectly happy returning the first token associated with the stem I need to look up.
vocab_frame = pd.DataFrame({'words': totalvocab_tokenized}, index = totalvocab_stemmed)
Tf-idf and document similarity¶
Here, I define term frequency-inverse document frequency (tf-idf) vectorizer parameters and then convert the synopses list into a tf-idf matrix.
To get a Tf-idf matrix, first count word occurrences by document. This is transformed into a document-term matrix (dtm). This is also just called a term frequency matrix. An example of a dtm is here at right.
Then apply the term frequency-inverse document frequency weighting: words that occur frequently within a document but not frequently within the corpus receive a higher weighting as these words are assumed to contain more meaning in relation to the document.
A couple things to note about the parameters I define below:
- max_df: this is the maximum frequency within the documents a given feature can have to be used in the tfi-idf matrix. If the term is in greater than 80% of the documents it probably cares little meanining (in the context of film synopses)
- min_idf: this could be an integer (e.g. 5) and the term would have to be in at least 5 of the documents to be considered. Here I pass 0.2; the term must be in at least 20% of the document. I found that if I allowed a lower min_df I ended up basing clustering on names--for example "Michael" or "Tom" are names found in several of the movies and the synopses use these names frequently, but the names carry no real meaning.
- ngram_range: this just means I'll look at unigrams, bigrams and trigrams. See [n-grams](http://en.wikipedia.org/wiki/N-gram)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=200000,
min_df=0.2, stop_words='english',
use_idf=True, tokenizer=tokenize_and_stem, ngram_range=(1,3))
%time tfidf_matrix = tfidf_vectorizer.fit_transform(synopses)
print(tfidf_matrix.shape)
CPU times: user 29 s, sys: 468 ms, total: 29.4 s Wall time: 35.9 s (100, 563)
terms = tfidf_vectorizer.get_feature_names()
from sklearn.metrics.pairwise import cosine_similarity
dist = 1 - cosine_similarity(tfidf_matrix)
K-means clustering¶
Now onto the fun part. Using the tf-idf matrix, you can run a slew of clustering algorithms to better understand the hidden structure within the synopses. I first chose k-means. K-means initializes with a pre-determined number of clusters (I chose 5). Each observation is assigned to a cluster (cluster assignment) so as to minimize the within cluster sum of squares. Next, the mean of the clustered observations is calculated and used as the new cluster centroid. Then, observations are reassigned to clusters and centroids recalculated in an iterative process until the algorithm reaches convergence.
I found it took several runs for the algorithm to converge a global optimum as k-means is susceptible to reaching local optima.
from sklearn.cluster import KMeans
num_clusters = 5
km = KMeans(n_clusters=num_clusters)
%time km.fit(tfidf_matrix)
clusters = km.labels_.tolist()
CPU times: user 210 ms, sys: 1.72 ms, total: 212 ms Wall time: 216 ms
from sklearn.externals import joblib
#joblib.dump(km, 'doc_cluster.pkl')
km = joblib.load('doc_cluster.pkl')
clusters = km.labels_.tolist()
import pandas as pd
films = { 'title': titles, 'rank': ranks, 'synopsis': synopses, 'cluster': clusters, 'genre': genres }
frame = pd.DataFrame(films, index = [clusters] , columns = ['rank', 'title', 'cluster', 'genre'])
frame['cluster'].value_counts()
4 26 0 25 2 21 1 16 3 12 dtype: int64
grouped = frame['rank'].groupby(frame['cluster'])
grouped.mean()
cluster 0 47.200000 1 58.875000 2 49.380952 3 54.500000 4 43.730769 dtype: float64
from __future__ import print_function
print("Top terms per cluster:")
print()
order_centroids = km.cluster_centers_.argsort()[:, ::-1]
for i in range(num_clusters):
print("Cluster %d words:" % i, end='')
for ind in order_centroids[i, :6]:
print(' %s' % vocab_frame.ix[terms[ind].split(' ')].values.tolist()[0][0].encode('utf-8', 'ignore'), end=',')
print()
print()
print("Cluster %d titles:" % i, end='')
for title in frame.ix[i]['title'].values.tolist():
print(' %s,' % title, end='')
print()
print()
Top terms per cluster: Cluster 0 words: family, home, mother, war, house, dies, Cluster 0 titles: Schindler's List, One Flew Over the Cuckoo's Nest, Gone with the Wind, The Wizard of Oz, Titanic, Forrest Gump, E.T. the Extra-Terrestrial, The Silence of the Lambs, Gandhi, A Streetcar Named Desire, The Best Years of Our Lives, My Fair Lady, Ben-Hur, Doctor Zhivago, The Pianist, The Exorcist, Out of Africa, Good Will Hunting, Terms of Endearment, Giant, The Grapes of Wrath, Close Encounters of the Third Kind, The Graduate, Stagecoach, Wuthering Heights, Cluster 1 words: police, car, killed, murders, driving, house, Cluster 1 titles: Casablanca, Psycho, Sunset Blvd., Vertigo, Chinatown, Amadeus, High Noon, The French Connection, Fargo, Pulp Fiction, The Maltese Falcon, A Clockwork Orange, Double Indemnity, Rebel Without a Cause, The Third Man, North by Northwest, Cluster 2 words: father, new, york, new, brothers, apartments, Cluster 2 titles: The Godfather, Raging Bull, Citizen Kane, The Godfather: Part II, On the Waterfront, 12 Angry Men, Rocky, To Kill a Mockingbird, Braveheart, The Good, the Bad and the Ugly, The Apartment, Goodfellas, City Lights, It Happened One Night, Midnight Cowboy, Mr. Smith Goes to Washington, Rain Man, Annie Hall, Network, Taxi Driver, Rear Window, Cluster 3 words: george, dance, singing, john, love, perform, Cluster 3 titles: West Side Story, Singin' in the Rain, It's a Wonderful Life, Some Like It Hot, The Philadelphia Story, An American in Paris, The King's Speech, A Place in the Sun, Tootsie, Nashville, American Graffiti, Yankee Doodle Dandy, Cluster 4 words: killed, soldiers, captain, men, army, command, Cluster 4 titles: The Shawshank Redemption, Lawrence of Arabia, The Sound of Music, Star Wars, 2001: A Space Odyssey, The Bridge on the River Kwai, Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb, Apocalypse Now, The Lord of the Rings: The Return of the King, Gladiator, From Here to Eternity, Saving Private Ryan, Unforgiven, Raiders of the Lost Ark, Patton, Jaws, Butch Cassidy and the Sundance Kid, The Treasure of the Sierra Madre, Platoon, Dances with Wolves, The Deer Hunter, All Quiet on the Western Front, Shane, The Green Mile, The African Queen, Mutiny on the Bounty,
#This is purely to help export tables to html and to correct for my 0 start rank (so that Godfather is 1, not 0)
frame['Rank'] = frame['rank'] + 1
frame['Title'] = frame['title']
#export tables to HTML
print(frame[['Rank', 'Title']].loc[frame['cluster'] == 1].to_html(index=False))
Multidimensional scaling¶
import os # for os.path.basename
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.manifold import MDS
MDS()
# two components as we're plotting points in a two-dimensional plane
# "precomputed" because we provide a distance matrix
# we will also specify `random_state` so the plot is reproducible.
mds = MDS(n_components=2, dissimilarity="precomputed", random_state=1)
pos = mds.fit_transform(dist) # shape (n_components, n_samples)
xs, ys = pos[:, 0], pos[:, 1]
#strip any proper nouns (NNP) or plural proper nouns (NNPS) from a text
from nltk.tag import pos_tag
def strip_proppers_POS(text):
tagged = pos_tag(text.split()) #use NLTK's part of speech tagger
non_propernouns = [word for word,pos in tagged if pos != 'NNP' and pos != 'NNPS']
return non_propernouns
Visualizing document clusters¶
#set up colors per clusters using a dict
cluster_colors = {0: '#1b9e77', 1: '#d95f02', 2: '#7570b3', 3: '#e7298a', 4: '#66a61e'}
#set up cluster names using a dict
cluster_names = {0: 'Family, home, war',
1: 'Police, killed, murders',
2: 'Father, New York, brothers',
3: 'Dance, singing, love',
4: 'Killed, soldiers, captain'}
%matplotlib inline
#create data frame that has the result of the MDS plus the cluster numbers and titles
df = pd.DataFrame(dict(x=xs, y=ys, label=clusters, title=titles))
#group by cluster
groups = df.groupby('label')
# set up plot
fig, ax = plt.subplots(figsize=(17, 9)) # set size
ax.margins(0.05) # Optional, just adds 5% padding to the autoscaling
#iterate through groups to layer the plot
#note that I use the cluster_name and cluster_color dicts with the 'name' lookup to return the appropriate color/label
for name, group in groups:
ax.plot(group.x, group.y, marker='o', linestyle='', ms=12, label=cluster_names[name], color=cluster_colors[name], mec='none')
ax.set_aspect('auto')
ax.tick_params(\
axis= 'x', # changes apply to the x-axis
which='both', # both major and minor ticks are affected
bottom='off', # ticks along the bottom edge are off
top='off', # ticks along the top edge are off
labelbottom='off')
ax.tick_params(\
axis= 'y', # changes apply to the y-axis
which='both', # both major and minor ticks are affected
left='off', # ticks along the bottom edge are off
top='off', # ticks along the top edge are off
labelleft='off')
ax.legend(numpoints=1) #show legend with only 1 point
#add label in x,y position with the label as the film title
for i in range(len(df)):
ax.text(df.ix[i]['x'], df.ix[i]['y'], df.ix[i]['title'], size=8)
plt.show() #show the plot
#uncomment the below to save the plot if need be
#plt.savefig('clusters_small_noaxes.png', dpi=200)

plt.close()
The clustering plot looks great, but it pains my eyes to see overlapping labels. Having some experience with D3.js I knew one solution would be to use a browser based/javascript interactive. Fortunately, I recently stumbled upon mpld3 a matplotlib wrapper for D3. Mpld3 basically let's you use matplotlib syntax to create web interactives. It has a really easy, high-level API for adding tooltips on mouse hover, which is what I am interested in.
It also has some nice functionality for zooming and panning. The below javascript snippet basicaly defines a custom location for where the zoom/pan toggle resides. Don't worry about it too much and you actually don't need to use it, but it helped for formatting purposes when exporting to the web later. The only thing you might want to change is the x and y attr for the position of the toolbar.
#define custom toolbar location
class TopToolbar(mpld3.plugins.PluginBase):
"""Plugin for moving toolbar to top of figure"""
JAVASCRIPT = """
mpld3.register_plugin("toptoolbar", TopToolbar);
TopToolbar.prototype = Object.create(mpld3.Plugin.prototype);
TopToolbar.prototype.constructor = TopToolbar;
function TopToolbar(fig, props){
mpld3.Plugin.call(this, fig, props);
};
TopToolbar.prototype.draw = function(){
// the toolbar svg doesn't exist
// yet, so first draw it
this.fig.toolbar.draw();
// then change the y position to be
// at the top of the figure
this.fig.toolbar.toolbar.attr("x", 150);
this.fig.toolbar.toolbar.attr("y", 400);
// then remove the draw function,
// so that it is not called again
this.fig.toolbar.draw = function() {}
}
"""
def __init__(self):
self.dict_ = {"type": "toptoolbar"}
#create data frame that has the result of the MDS plus the cluster numbers and titles
df = pd.DataFrame(dict(x=xs, y=ys, label=clusters, title=titles))
#group by cluster
groups = df.groupby('label')
#define custom css to format the font and to remove the axis labeling
css = """
text.mpld3-text, div.mpld3-tooltip {
font-family:Arial, Helvetica, sans-serif;
}
g.mpld3-xaxis, g.mpld3-yaxis {
display: none; }
"""
# Plot
fig, ax = plt.subplots(figsize=(14,6)) #set plot size
ax.margins(0.03) # Optional, just adds 5% padding to the autoscaling
#iterate through groups to layer the plot
#note that I use the cluster_name and cluster_color dicts with the 'name' lookup to return the appropriate color/label
for name, group in groups:
points = ax.plot(group.x, group.y, marker='o', linestyle='', ms=18, label=cluster_names[name], mec='none', color=cluster_colors[name])
ax.set_aspect('auto')
labels = [i for i in group.title]
#set tooltip using points, labels and the already defined 'css'
tooltip = mpld3.plugins.PointHTMLTooltip(points[0], labels,
voffset=10, hoffset=10, css=css)
#connect tooltip to fig
mpld3.plugins.connect(fig, tooltip, TopToolbar())
#set tick marks as blank
ax.axes.get_xaxis().set_ticks([])
ax.axes.get_yaxis().set_ticks([])
#set axis as blank
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
ax.legend(numpoints=1) #show legend with only one dot
mpld3.display() #show the plot
#uncomment the below to export to html
#html = mpld3.fig_to_html(fig)
#print(html)
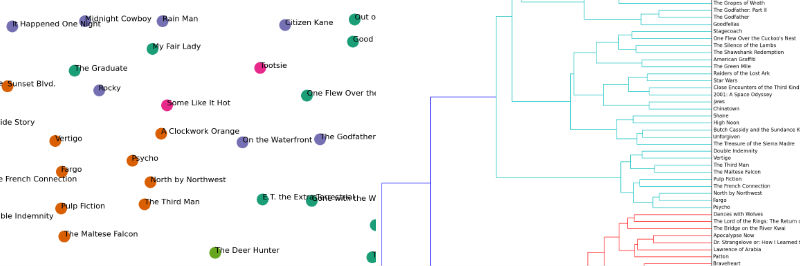
Hierarchical document clustering¶
from scipy.cluster.hierarchy import ward, dendrogram
linkage_matrix = ward(dist) #define the linkage_matrix using ward clustering pre-computed distances
fig, ax = plt.subplots(figsize=(15, 20)) # set size
ax = dendrogram(linkage_matrix, orientation="right", labels=titles);
plt.tick_params(\
axis= 'x', # changes apply to the x-axis
which='both', # both major and minor ticks are affected
bottom='off', # ticks along the bottom edge are off
top='off', # ticks along the top edge are off
labelbottom='off')
plt.tight_layout() #show plot with tight layout
#uncomment below to save figure
plt.savefig('ward_clusters.png', dpi=200) #save figure as ward_clusters

plt.close()
Latent Dirichlet Allocation¶
#strip any proper names from a text...unfortunately right now this is yanking the first word from a sentence too.
import string
def strip_proppers(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent) if word.islower()]
return "".join([" "+i if not i.startswith("'") and i not in string.punctuation else i for i in tokens]).strip()
#strip any proper nouns (NNP) or plural proper nouns (NNPS) from a text
from nltk.tag import pos_tag
def strip_proppers_POS(text):
tagged = pos_tag(text.split()) #use NLTK's part of speech tagger
non_propernouns = [word for word,pos in tagged if pos != 'NNP' and pos != 'NNPS']
return non_propernouns
#Latent Dirichlet Allocation implementation with Gensim
from gensim import corpora, models, similarities
#remove proper names
preprocess = [strip_proppers(doc) for doc in synopses]
%time tokenized_text = [tokenize_and_stem(text) for text in preprocess]
%time texts = [[word for word in text if word not in stopwords] for text in tokenized_text]
CPU times: user 15.4 s, sys: 142 ms, total: 15.6 s Wall time: 19 s CPU times: user 4.38 s, sys: 22.2 ms, total: 4.4 s Wall time: 4.6 s
#print(len([word for word in texts[0] if word not in stopwords]))
print(len(texts[0]))
1839
dictionary = corpora.Dictionary(texts)
dictionary.filter_extremes(no_below=1, no_above=0.8)
corpus = [dictionary.doc2bow(text) for text in texts]
len(corpus)
100
%time lda = models.LdaModel(corpus, num_topics=5, id2word=dictionary, update_every=5, chunksize=10000, passes=100)
CPU times: user 9min 48s, sys: 3.98 s, total: 9min 52s Wall time: 11min 43s
print(lda[corpus[0]])
[(1, 0.14010786617821663), (2, 0.2389980721391618), (3, 0.080853026271803449), (4, 0.53991713521730689)]
topics = lda.print_topics(5, num_words=20)
topics_matrix = lda.show_topics(formatted=False, num_words=20)
topics_matrix = np.array(topics_matrix)
topics_matrix.shape
(5, 20, 2)
topic_words = topics_matrix[:,:,1]
for i in topic_words:
print([str(word) for word in i])
print()
['famili', 'murder', 'prison', 'work', 'kill', 'life', 'guard', 'way', "n't", 'two', 'meet', 'would', 'death', 'say', 'll', 'vote', 'becom', 'ask', 'guilti', 'peopl'] ['love', 'marri', 'go', 'home', 'friend', 'show', 'day', 'father', 'meet', 'want', "n't", 'night', 'doe', 'apart', 'famili', 'work', 'film', 'first', 'sing', 'come'] ['kill', 'meet', 'arriv', 'first', 'two', 'order', 'escap', 'friend', 'say', 'famili', 'ask', 'call', 'attempt', 'father', 'later', 'refus', "n't", 'offer', 'name', 'away'] ['kill', 'soldier', 'men', 'order', 'shark', 'command', 'attack', 'water', 'war', 'offic', 'arriv', 'boat', 'die', 'wound', 'two', 'attempt', 'villag', 'fire', 'battl', 'shoot'] ['car', 'ask', 'polic', 'home', "n't", 'go', 'say', 'kill', 'run', 'hous', 'goe', 'two', 'friend', 'day', 'call', 'come', 'drive', 'meet', 'doe', 'away']