Collecting Twitter data from the API using Python¶
Alex Hanna, University of Wisconsin-Madison
alex-hanna.com
@alexhanna
Today we're going to focus on collecting Twitter data using their API using Python. You can use another language to collect data but Python makes it rather straightforward without having to know many other details about the API.
Using APIs¶
The way that researchers and other people who want to get large publically available Twitter datasets is through their API. API stands for Application Programming Interface and many services that want to start a developer community around their product usually releases one. Facebook has an API that is somewhat restrictive, while Klout has an API to let you automatically look up Klout scores and all their different facets.
For instance, here are a list of different APIs of different services:
Facebook - https://developers.facebook.com/docs/reference/api/
YouTube - https://developers.google.com/youtube/getting_started
Accessing the Twitter API¶
The Twitter API has two different flavors: RESTful and Streaming. The RESTful API is useful for getting things like lists of followers and those who follow a particular user, and is what most Twitter clients are built off of. We are not going to deal with the RESTful API right now, but you can find more information on it here: https://dev.twitter.com/docs/api. Right now we are going to focus on the Streaming API (more info here: https://dev.twitter.com/docs/streaming-api). The Streaming API works by making a request for a specific type of data — filtered by keyword, user, geographic area, or a random sample — and then keeping the connection open as long as there are no errors in the connection.
Understanding Twitter Data¶
Once you’ve connected to the Twitter API, whether via the RESTful API or the Streaming API, you’re going to start getting a bunch of data back. The data you get back will be encoded in JSON, or JavaScript Object Notation. JSON is a way to encode complicated information in a platform-independent way. It could be considered the lingua franca of information exchange on the Internet. When you click a snazzy Web 2.0 button on Facebook or Amazon and the page produces a lightbox (a box that hovers above a page without leaving the page you’re on now), there was probably some JSON involved.
JSON is a rather simplistic and elegant way to encode complex data structures. When a tweet comes back from the API, this is what it looks like (with a little bit of beautifying):
"""
{
"contributors": null,
"truncated": false,
"text": "TeeMinus24's Shirt of the Day is Palpatine/Vader '12. Support the Sith. Change you can't stop. http://t.co/wFh1cCep",
"in_reply_to_status_id": null,
"id": 175090352598945794,
"entities": {
"user_mentions": [],
"hashtags": [],
"urls": [
{
"indices": [
95,
115
],
"url": "http://t.co/wFh1cCep",
"expanded_url": "http://fb.me/1isEdQJSq",
"display_url": "fb.me/1isEdQJSq"
}
]
},
"retweeted": false,
"coordinates": null,
"source": "<a href="\"http://www.facebook.com/twitter\"" rel="\"nofollow\"">Facebook</a>",
"in_reply_to_screen_name": null,
"id_str": "175090352598945794",
"retweet_count": 0,
"in_reply_to_user_id": null,
"favorited": false,
"user": {
"follow_request_sent": null,
"profile_use_background_image": true,
"default_profile_image": false,
"profile_background_image_url_https": "https://si0.twimg.com/images/themes/theme14/bg.gif",
"verified": false,
"profile_image_url_https": "https://si0.twimg.com/profile_images/1428484273/TeeMinus24_logo_normal.jpg",
"profile_sidebar_fill_color": "efefef",
"is_translator": false,
"id": 281077639,
"profile_text_color": "333333",
"followers_count": 43,
"protected": false,
"location": "",
"profile_background_color": "131516",
"id_str": "281077639",
"utc_offset": -18000,
"statuses_count": 461,
"description": "We are a limited edition t-shirt company. We make tees that are designed for the fan; movies, television shows, video games, sci-fi, web, and tech. We have it!",
"friends_count": 52,
"profile_link_color": "009999",
"profile_image_url": "http://a0.twimg.com/profile_images/1428484273/TeeMinus24_logo_normal.jpg",
"notifications": null,
"show_all_inline_media": false,
"geo_enabled": false,
"profile_background_image_url": "http://a0.twimg.com/images/themes/theme14/bg.gif",
"screen_name": "TeeMinus24",
"lang": "en",
"profile_background_tile": true,
"favourites_count": 0,
"name": "Vincent Genovese",
"url": "http://www.teeminus24.com",
"created_at": "Tue Apr 12 15:48:23 +0000 2011",
"contributors_enabled": false,
"time_zone": "Eastern Time (US & Canada)",
"profile_sidebar_border_color": "eeeeee",
"default_profile": false,
"following": null,
"listed_count": 1
},
"geo": null,
"in_reply_to_user_id_str": null,
"possibly_sensitive": false,
"created_at": "Thu Mar 01 05:29:27 +0000 2012",
"possibly_sensitive_editable": true,
"in_reply_to_status_id_str": null,
"place": null
}"""
Let’s move our focus now to the actual elements of the tweet. Most of the keys, that is, the words on the left of the colon, are self-explanatory. The most important ones are “text”, “entities”, and “user”. “Text” is the text of the tweet, “entities” are the user mentions, hashtags, and links used in the tweet, separated out for easy access. “User” contains a lot of information on the user, from URL of their profile image to the date they joined Twitter.
Now that you see what data you get with a tweet, you can envision interesting types of analysis that can emerge by analyzing a whole lot of them.
A Disclaimer on Collecting Tweets¶
Unfortunately, you do not have carte blanche to share the tweets you collect. Twitter restricts publicly releasing datasets according to their API Terms of Service (https://dev.twitter.com/terms/api-terms). This is unfortunately for collaboration when colleagues have collected very unique datasets. However, you can share derivative analysis from tweets, such as content analysis and aggregate statistics.
Logging into the remote server¶
The terminal (also called the command line) is how you access a UNIX-based machine remotely. For reasons
For now, we’re not going to access that cluster (and given that it’s not been setup yet, it’s not possible). Instead we’re going to connect to an old computer I have running out of my living room. Which means be very sympathetic to my bandwidth restrictions. Here is how you connect to it.
For Windows:
- Download PuTTy at http://www.chiark.greenend.org.uk/~sgtatham/putty/. Save and open it.
- Type in the “host” field ec2-54-225-7-147.compute-1.amazonaws.com
- Use the credential information that I give you in the workshop.
For Mac:
- Go to Applications -> Utilities -> Terminal and open Terminal.
- Type
ssh <username>@ec2-54-225-7-147.compute-1.amazonaws.com, where <username> is the username I give you. - Use the credential information I give you in the workshop.
Once you've done that, you need to check out the git repository for this workshop. You can do that by typing this command:
[hse0@ip-10-196-55-224 ~]$ git clone https://github.com/raynach/hse-twitter
Note: don't type [hse0@ip-10-196-55-224 ~]$</code>. This is the command-line identifier that I'm using so you know you're on the command line. Type everything after the $.
This will create the hse-twitter directory in your home directory. A directory is another name for a folder. Within the hse-twitter directory will be two more: bin and data. Get into the hse-twitter directory by typing the following:
[hse0@ip-10-196-55-224 ~]$ cd hse-twitter
Then get into the bin directory by typing:
[hse0@ip-10-196-55-224 hse-twitter]$ cd bin
If you want to move up a level, you can type:
[hse0@ip-10-196-55-224 bin]$ cd ..
If you want to see where you are, you can use the ls and the pwd commands. So for instance, once you are in the hse-twitter directory, do this:
[hse0@ip-10-196-55-224 hse-twitter]$ ls
And you should get this as output:
bin data README.md
Enter the bin directory and you can see where you are with pwd
[hse0@ip-10-196-55-224 hse-twitter]$ cd bin/
[hse0@ip-10-196-55-224 bin]$ pwd
/home/hse0/hse-twitter/bin
Editing and Writing FIles¶
First thing’s first — get a text editor. Go to http://www.jedit.org/ and download jEdit. jEdit is a free, open-source text editor written in Java. It has a ton of cool features and makes editing files on remote servers a snap. Which is why we are using it.
Once you have downloaded it and installed it, go to Plugins->Plugins Manager in the menu. You should get a screen that looks like this.

Click the "Install" tab and find the "FTP" plugin. Select the checkbox and click install. Once it installs, close the window. Now, select Plugin->FTP->Open from Secure FTP Server... from the menu. Type in all your information so looks like the screenshot below.

Now, once it loads, navigate to the "hse-twitter/bin" directory like you would with a GUI file manager. Open up streaming.py. This is the file we'll eventually get to editing.
However, before that, I need to give a little background on Python. Python is an interpreted script language. This is different from languages like Java or C, which are traditionally compiled into a language that the computer can read directly. Python is different. It reads files like a script -- line-by-line and executing commands in a procedural fashion.
Collecting Data¶
Collecting data is pretty straightforward with tweepy. The first thing to do is to create an instance of a tweepy StreamListener to handle the incoming data. The way that I have mine set up is that I start a new file for every 20,000 tweets, tagged with a prefix and a timestamp. I also keep another file open for the list of status IDs that have been deleted, which are handled differently than other tweet data. I call this file slistener.py. You should have a copy of it.
from tweepy import StreamListener
import json, time, sys
class SListener(StreamListener):
def __init__(self, api = None, fprefix = 'streamer'):
self.api = api or API()
self.counter = 0
self.fprefix = fprefix
self.output = open('../data/' + fprefix + '.'
+ time.strftime('%Y%m%d-%H%M%S') + '.json', 'w')
self.delout = open('../data/delete.txt', 'a')
def on_data(self, data):
if 'in_reply_to_status' in data:
self.on_status(data)
elif 'delete' in data:
delete = json.loads(data)['delete']['status']
if self.on_delete(delete['id'], delete['user_id']) is False:
return False
elif 'limit' in data:
if self.on_limit(json.loads(data)['limit']['track']) is False:
return False
elif 'warning' in data:
warning = json.loads(data)['warnings']
print warning['message']
return false
def on_status(self, status):
self.output.write(status + "\n")
self.counter += 1
if self.counter >= 20000:
self.output.close()
self.output = open('../data/' + self.fprefix + '.'
+ time.strftime('%Y%m%d-%H%M%S') + '.json', 'w')
self.counter = 0
return
def on_delete(self, status_id, user_id):
self.delout.write( str(status_id) + "\n")
return
def on_limit(self, track):
sys.stderr.write(track + "\n")
return
def on_error(self, status_code):
sys.stderr.write('Error: ' + str(status_code) + "\n")
return False
def on_timeout(self):
sys.stderr.write("Timeout, sleeping for 60 seconds...\n")
time.sleep(60)
return
Next, we need the script that does the collecting itself. I call this file streaming.py. You can collect on users, keywords, or specific locations defined by bounding boxes. The API documentation has more information on this. For now, let’s just track some popular keywords — "obama" and "egypt" (keywords are case-insensitive).
from slistener import SListener
import time, tweepy, sys
## auth.
## TK: Edit the username and password fields to authenticate from Twitter.
username = ''
password = ''
auth = tweepy.auth.BasicAuthHandler(username, password)
api = tweepy.API(auth)
## Eventually you'll need to use OAuth. Here's the code for it here.
## You can learn more about OAuth here: https://dev.twitter.com/docs/auth/oauth
#consumer_key = ""
#consumer_secret = ""
#access_token = ""
#access_token_secret = ""
# OAuth process, using the keys and tokens
#auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
#auth.set_access_token(access_token, access_token_secret)
def main( mode = 1 ):
track = ['obama', 'egypt']
follow = []
listen = SListener(api, 'test')
stream = tweepy.Stream(auth, listen)
print "Streaming started on %s users and %s keywords..." % (len(track), len(follow))
try:
stream.filter(track = track, follow = follow)
#stream.sample()
except:
print "error!"
stream.disconnect()
if __name__ == '__main__':
main()
You need to change the username and password variables in the code above for it to work. You can do that by accessing the file through jEdit and making the changes there. Use your personal Twitter username and password, or create one for the workshop and use it there.
Once you've changed the username and password, you can start collecting data. Run the following command:
[hse0@ip-10-196-55-224 bin]$ python streaming.py
To stop this script from running, press Ctrl + C.
Note: if we run this all at once we may get an error from Twitter. If you can a 421 error, that is what is probably happening. So only run this for a second and then quit out of it.
You can see the data collected by going to the data directory. If you are in bin, you can type cd ../data. Then type ls -l to see something like this.
[hse0@ip-10-196-55-224 bin]$ cd ../data
[hse0@ip-10-196-55-224 data]$ ls -l
total 1496
-rw-rw-r-- 1 hse0 hse0 0 Aug 16 00:12 delete.txt
-rw-rw-r-- 1 hse0 hse0 0 Aug 16 00:12 placeholder
-rw-rw-r-- 1 hse0 hse0 208409 Aug 16 00:14 test.20130816-001357.json
The file that ends with "json" is the Twitter data. If you type "more <filename>" you can see some of the raw JSON.
Getting Network Data¶
Once we've actually collected some Twitter data, we need to get network data out of it somehow. For the current analysis we are just going to look at mention networks. The way that tweets are structured, we can easily pull out mentions of other users.
The networked part of Twitter JSON looks like this:
"""{
"id_str":"265631953204686848",
"text":"@AllenVaughan In all fairness that \"talented\" team was 5-6...",
"in_reply_to_user_id_str":"166318986",
...
"entities":{
"urls":[],
"hashtags":[],
"user_mentions":[
{
"id_str":"166318986",
"indices":[0,13],
"name":"Allen Vaughan",
"screen_name":"AllenVaughan",
"id":166318986
}
]}
...
}"""
A potential pitfall of pulling out mentions this way is that retweets are also recorded like this, so we could be measuring both retweets and mentions. However, we can bracket this considering right now. There are ways of filtering out retweets that we can cover in future modules. For now, we will focus on how to create mention networks.
To process these mentions we will create a file called mentionMapper.py. The algorithm for producing these networks is pretty straightforward. It looks like the following pseudocode:
for each tweet:
user1 = current user
for each mention of another user (user2):
emit user1, user2, 1
#!/usr/bin/env python
import json, sys
def main():
for line in sys.stdin:
line = line.strip()
data = ''
try:
data = json.loads(line)
except ValueError as detail:
sys.stderr.write(detail.__str__() + "\n")
continue
if 'entities' in data and len(data['entities']['user_mentions']) > 0:
user = data['user']
user_mentions = data['entities']['user_mentions']
for u2 in user_mentions:
print "\t".join([
user['id_str'],
u2['id_str'],
"1"
])
if __name__ == '__main__':
main()
To run this, we use a few UNIX commands to tie the output of one UNIX command to be the input of another. First, make sure that you are in the bin directory. Next, we'll use the cat command and the | character to pipe the Twitter data into the Python file. You'll need to replace "../data/test.20130816-004221.json" with the name of the file that tweepy generated for you.
[hse0@ip-10-196-55-224 bin]$ cat ../data/test.20130816-004221.json | python mentionMapper.py
634645657 386260483 1
228023890 312739659 1
34344598 420452993 1
539484750 20909329 1
1411163412 1614375631 1
152158738 80330381 1
...
You'll probably get a lot of output here. To redirect this to a file, you can use the > character.
[hse0@ip-10-196-55-224 bin]$ cat ../data/test.20130816-004221.json | python mentionMapper.py > network-data.csv
Updated, 2013-08-17
If you weren't able to collect your own tweets, you can grab a test dataset of 10,000 tweets by typing this:
[hse0@ip-10-196-55-224 bin]$ wget http://ssc.wisc.edu/~ahanna/sampleTweets.json
This will download a file which you can run the mentionMapper.py file on:
[hse0@ip-10-196-55-224 bin]$ cat sampleTweets.json | python mentionMapper.py > network-data.csv
End Update
And voila! Now you have an edgelist that you can give to NodeXL, Gephi, or R. You can connect to the server using a tool like CyberDuck (http://cyberduck.ch/) or WinSCP (http://winscp.net/eng/index.php) to download the file and plug it into your favorite statistical package.
This is, of course, a very basic sort of method to gather connections. We can also filter user mentions on whether it is a user mention (e.g. @alexhanna hi!) or a retweet. We can also count how many interactions users have between each other within a given amount of time to quantify tie strength. But this analysis is a basic building block of this kind of analysis.
Much of this workshop has been based off of this tutorial, which contains a few more details and displays a network graph surrounding the US presidential election.
Appendix: How to get your OAuth keys for tweepy¶
@jsajuria put together this tutorial of how to get OAuth keys for the script above.
First, go into dev.twitter.com and login using your Twitter account details. You will now activate your account to work as a Twitter developer.
Then, click on your Twitter avatar (upper right-hand corner) and a menu will display. Click on "My Applications"

Once there, you will have to click the "Create new application" button
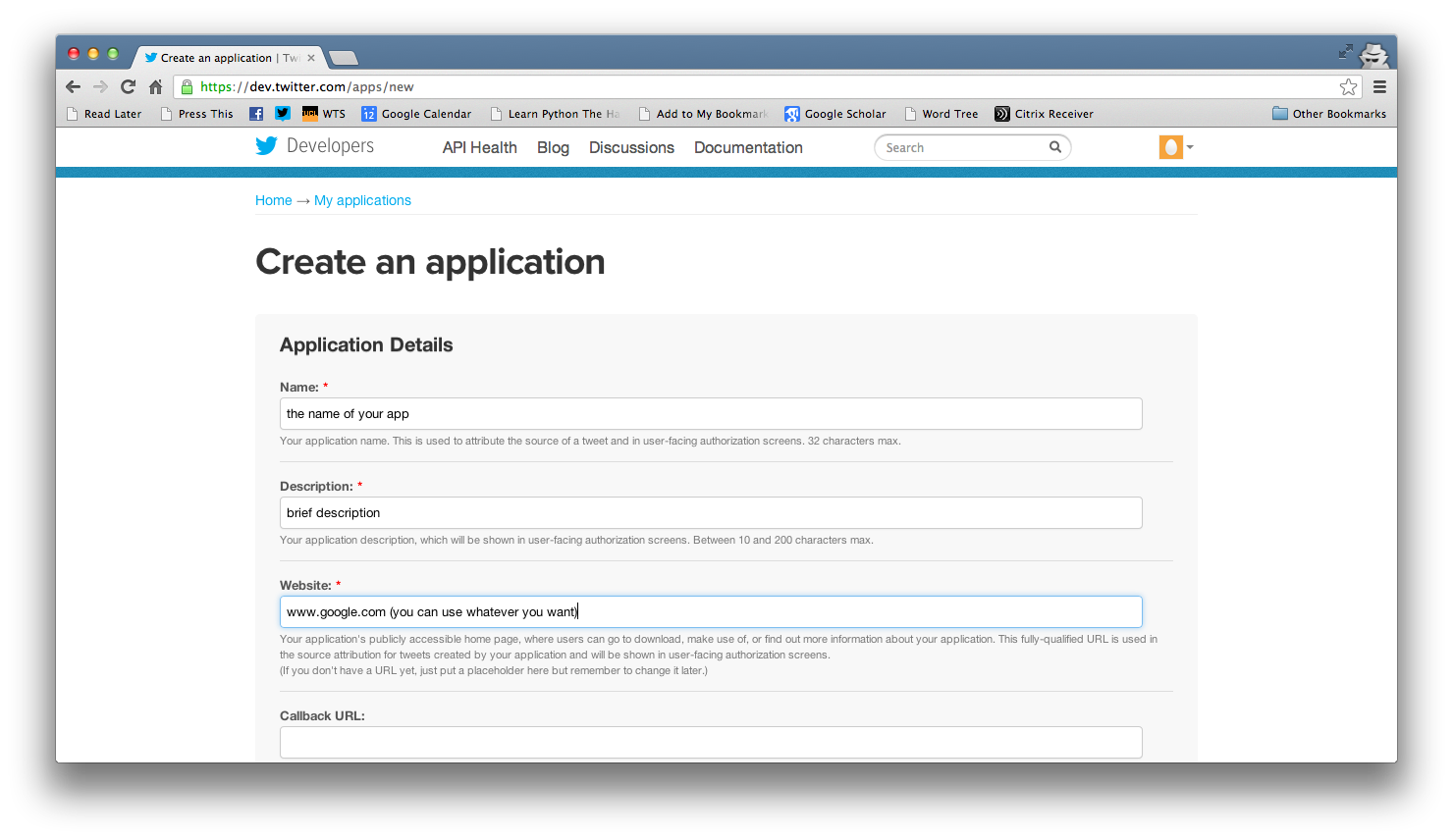
You'll get a form with the basic data of your app. Create a name and a short description, and enter any URL (you won't need a custom URL for using tweepy)
Now, you have your new app, and can ask Twitter to create your keys. You can access this site to get instructions on how to create them. Once you have them, open the streaming.py on jEdit and change the code in the following way:
Remove the # signs on the code lines referring to the OAuth process and enter your details (consumer key, token, and their respective secrets), as shown below:
## Eventually you'll need to use OAuth. Here's the code for it here.`
## You can learn more about OAuth here: https://dev.twitter.com/docs/auth/oauth`
consumer_key = "YOUR CONSUMER KEY HERE"
consumer_secret = "YOUR CONSUMER SECRET HERE"
access_token = "YOUR TOKEN HERE"
access_token_secret = "YOUR TOKEN SECRET HERE"
# OAuth process, using the keys and tokens
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
Once finished, remember to save it, go back to the terminal, and type
python streaming.py
That should do it!