Datamaglia Demo¶
Below we will briefly introduce the Datamaglia API and demonstrate how it can be used to generate recommendations. We will use Python because it is readable, and widely-known, you can use any language that can make HTTP requests.
You'll need to install the Requests library to use this notebook, which you can do with a quick pip install requests.
import requests
import json
In order to use the API, we need to first create an application, a subgraph (to describe the data model), and an API token (to allow us access). We've created these already for you to use with this notebook, but if you want to create your own you'll need to sign up for a Datamaglia account.
Below you can see an exmple of how to create a subgraph. The subgraph tells us what your data look like. Each subgraph has three components: a source, a target, and a relationship. These are explained briefly below.
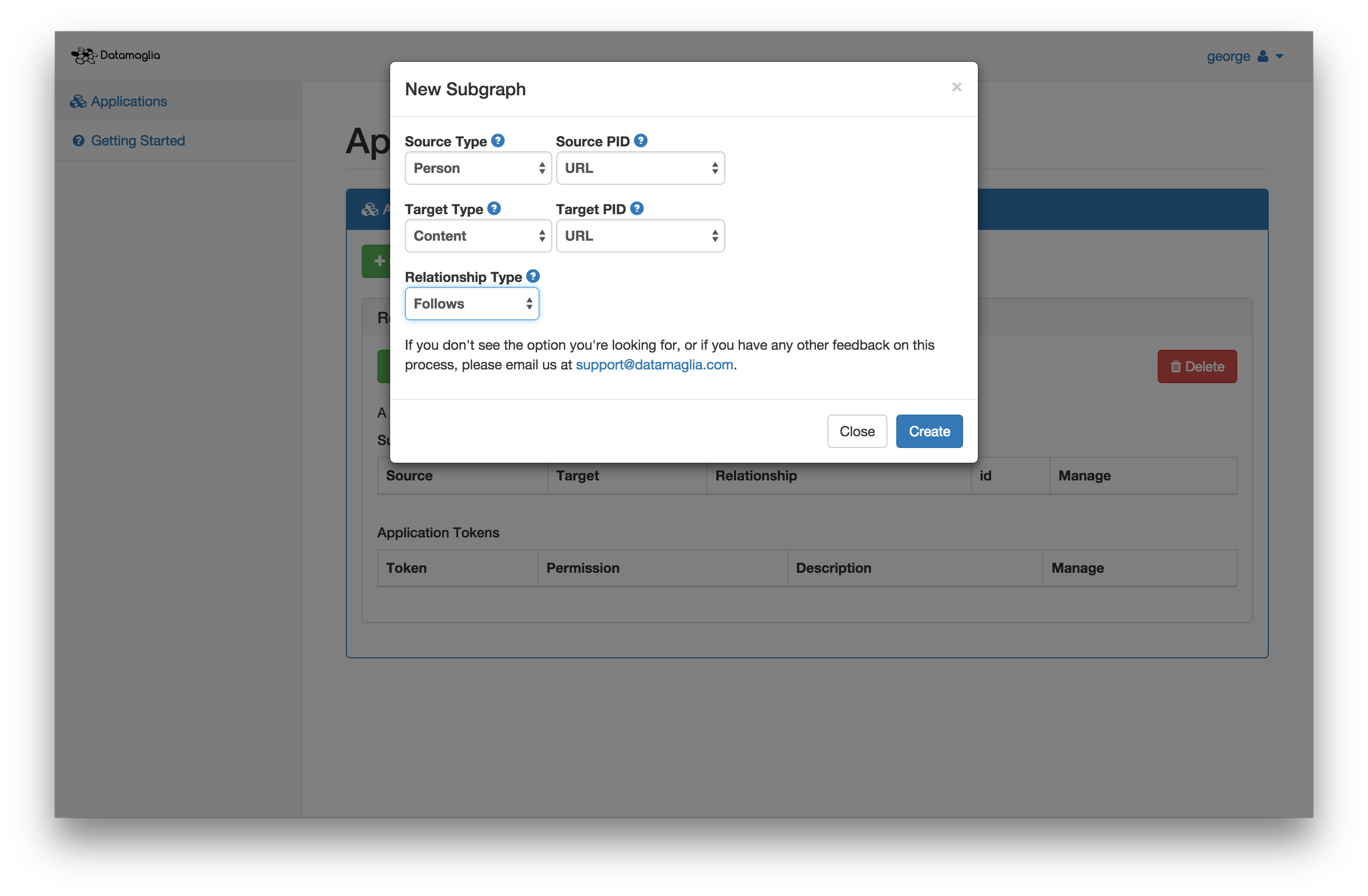
A source is the entity (almost always a person) for which you want to generate recommendations. This is probably a user of your product or service, but it might be someone else. The source usually takes some kind of action while using your application that informs us about his or her preferences. This could be "starring" a piece of content, making a social connection with another person, or even just visiting a web page.
A relationship is the how we track these user preferences. For example, if your application allows users to "star" pieces of content, we might use the "liked" or "followed" relationships because the action taken by the user indicates to us that he or she likes that content or wants to be updated about it in the future.
The target is what the source can express preferences about. In the example above, this would be the content that can be "starred".
The source and target each have a PID. This just tells us how you plan to identify these pieces of the subgraph. For instance, you might identify users by an email address, or a Twitter handle, or you might identify a piece of content using its URL. In this example, we're using the URL for both since Reddit users each have a profile page.
Now that we have a subgraph created, we need an API key (called an Application Token). This allows our application to access the Datamaglia service. You can create read (generate recommendations), write (insert data from which recommendations can be generated), or read/write (both) tokens. This lets you customize the level of access that a particular piece of the application should have. For example, your backend server might need read/write, but your frontend mobile application might only need read permission.
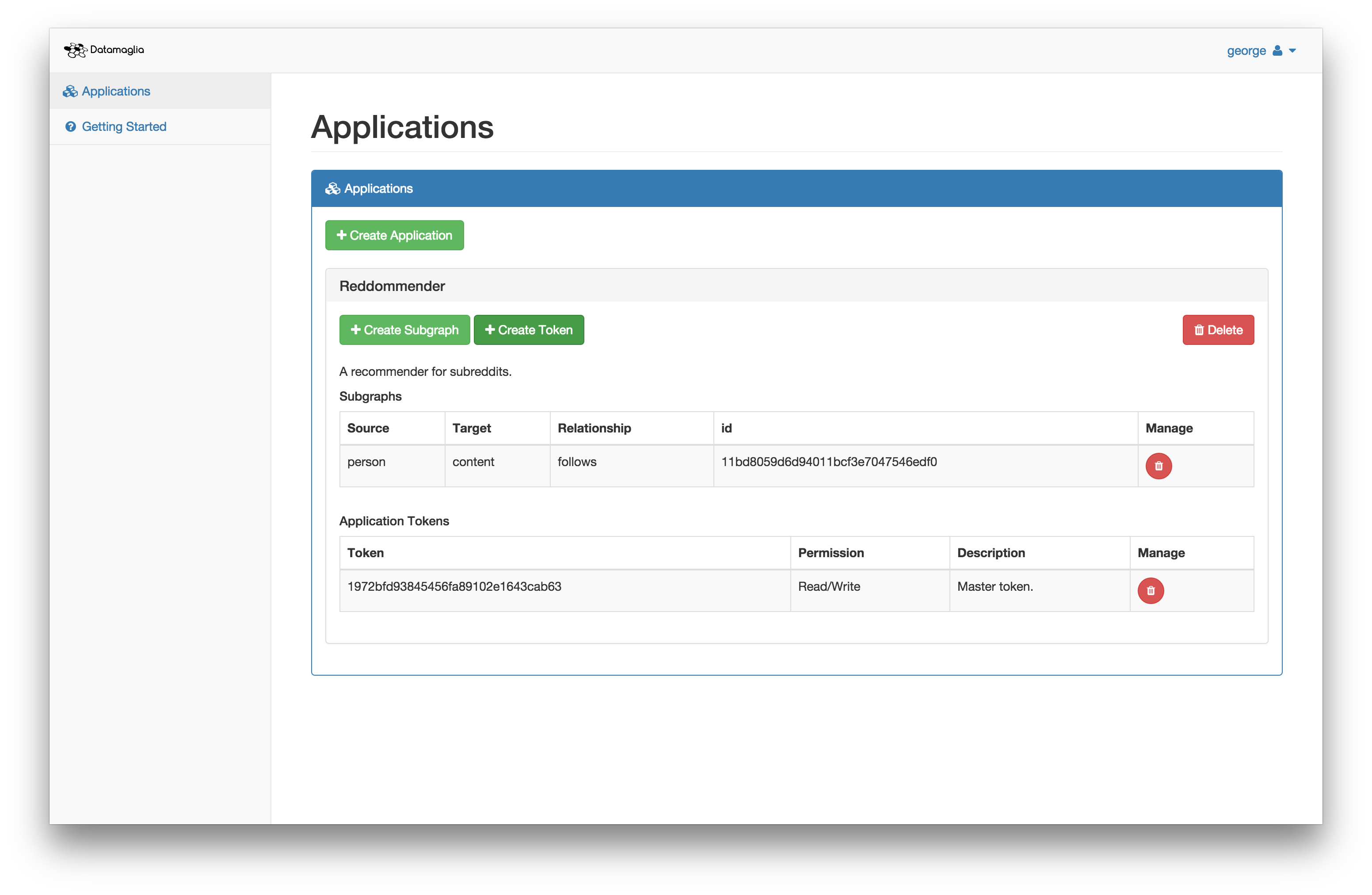
There are two important values that come from this process. First, you'll need the subgraph ID in order to make requests to the Datamaglia API. This tells us which subgraph to insert data into and which subgraph we should use for generating a recommendation. Second, you'll need a token that has appropriate access.
Note that the subgraph ID and token values above are different than the ones used here, that isn't a problem, we re-created the application since the screenshots were taken.
SUBGRAPH_ID = '42464879f61b4ce7baee411eae57baed'
API_KEY = 'a840c726507e4bc6810976320abcf583'
For convenience, we'll define some values to use later. These are just for convenience.
BASE_URL = 'https://api.datamaglia.com/v1{}'
SRC_URL = BASE_URL.format('/subgraphs/' + SUBGRAPH_ID + '/data/sources/')
TARG_URL = BASE_URL.format('/subgraphs/' + SUBGRAPH_ID + '/data/targets/')
REL_URL = BASE_URL.format('/subgraphs/' + SUBGRAPH_ID + '/data/relationships/')
REC_URL = BASE_URL.format('/recommendations/subgraphs/' + SUBGRAPH_ID + '/member')
HEADERS = {'Auth-Token': API_KEY, 'Content-Type': 'application/json'}
First, let's create some (fake) Reddit users. We've selected random names, any resemblence to actual users is purely coincidental.
names = ['miguel', 'adam', 'julie', 'steve', 'caroline', 'ingrid']
entities = [
{
'id': 'https://www.reddit.com/u/{}'.format(name),
'properties': [
{'key': 'name', 'value': name}
]
} for name in names
]
payload = {'entities': entities}
resp = requests.post(SRC_URL, headers=HEADERS, data=json.dumps(payload))
print resp # Should be 204
<Response [204]>
Now we have inserted some users. Note that we were able to insert several at once, this makes things a little quicker and more flexible, but we could have inserted them one at a time too. A 204 response means everything worked, so now let's add some subreddits that these users might follow.
# Now, let's add some (real) subreddits.
subreddits = ['programming', 'askreddit', 'askscience', 'books', 'dataisbeautiful']
entities = [
{
'id': 'https://www.reddit.com/r/{}'.format(subreddit)
} for subreddit in subreddits
]
payload = {'entities': entities}
resp = requests.post(TARG_URL, headers=HEADERS, data=json.dumps(payload))
print resp # Should be 204
<Response [204]>
Great! Now we have some users, and some subreddits, so it is time to link them together with relationships. Notice that we didn't have to add any relationships. This is by design. There might very well be content or people in your application that haven't been "liked" or "followed" or "purchased" by anyone... yet. But once one of those things happens, we want to be ready.
# Now let's make some of our users follow some subreddits. This is what will allow us to generate recommendations later.
follows = [
('miguel', 'programming'),
('miguel', 'askscience'),
('miguel', 'books'),
('adam', 'programming'),
('adam', 'dataisbeautiful'),
('adam', 'books'),
('julie', 'books'),
('julie', 'askscience'),
('steve', 'askscience'),
('steve', 'askreddit'),
('caroline', 'books'),
('caroline', 'askreddit'),
('ingrid', 'programming'),
('ingrid', 'dataisbeautiful'),
]
entities = [
{
'weight': 0,
'source': 'https://www.reddit.com/u/{}'.format(name),
'target': 'https://www.reddit.com/r/{}'.format(subreddit)
} for (name, subreddit) in follows
]
payload = {'entities': entities}
resp = requests.post(REL_URL, headers=HEADERS, data=json.dumps(payload))
print resp # Should be 204
<Response [204]>
Look at all our happy Redditors! Now let's find out which other subreddits some of our users would enjoy following!
# Now let's see which subreddits might interest Steve.
r = requests.get(REC_URL, params={'id': 'https://www.reddit.com/u/steve', 'limit': 3}, headers={'Auth-Token': API_KEY})
print json.dumps(json.loads(r.text), indent=4)
{
"entities": []
}
# Or Ingrid. Note that we recommend Ingrid check out r/books because of her similiarity with Adam,
# the two of them are very similar, so this makes sense.
r = requests.get(REC_URL, params={'id': 'https://www.reddit.com/u/ingrid', 'limit': 3}, headers={'Auth-Token': API_KEY})
print json.dumps(json.loads(r.text), indent=4)
{
"entities": [
{
"score": 0.9166666666666666,
"relationship": {
"source": {
"id": {
"key": "url",
"value": "https://www.reddit.com/u/ingrid"
},
"properties": [
{
"key": "name",
"value": "ingrid"
}
]
},
"type": "follows",
"target": {
"id": {
"key": "url",
"value": "https://www.reddit.com/r/books"
},
"properties": []
},
"weight": 0.0
}
},
{
"score": 0.25,
"relationship": {
"source": {
"id": {
"key": "url",
"value": "https://www.reddit.com/u/ingrid"
},
"properties": [
{
"key": "name",
"value": "ingrid"
}
]
},
"type": "follows",
"target": {
"id": {
"key": "url",
"value": "https://www.reddit.com/r/askscience"
},
"properties": []
},
"weight": 0.0
}
}
]
}
A couple notes about the results here are in order. First, the "score" reflects the strength of the recommendation. Higher values mean more relevant matches. We're still fiddling with how we compute the score, so stay tuned, but the overall idea won't change. Next, we return all three parts of the subgraph for each recommendation. This is because you, as the developer, might want to use the information in your UI.
Thanks for reading through this demo and tutorial! We hope to improve it as we continue to build out the Datamaglia service. If you have questions (or, even better, suggestions) you can send us an email at support@datamaglia.com.