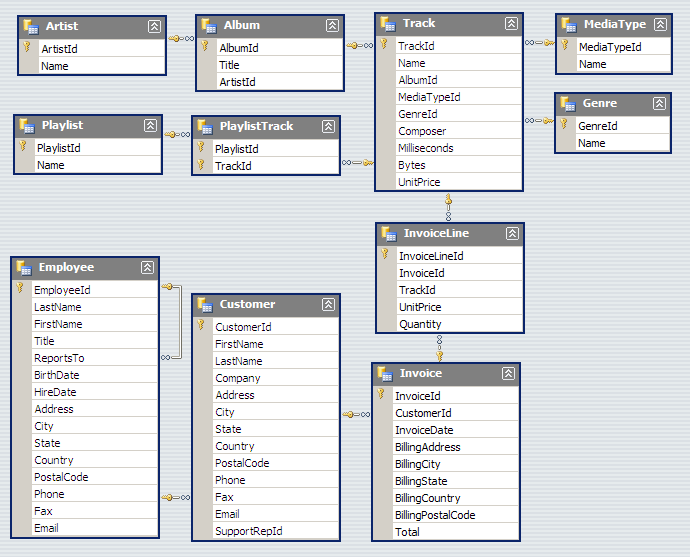
 # ## Example 1 - Total Revenue
#
# Ever written SQL like this?
# In[1]:
db = "split-apply-combine_resources/Chinook_Sqlite.sqlite"
import sqlite3
conn = sqlite3.connect(db)
curs = conn.cursor()
print curs.execute("SELECT SUM(UnitPrice*Quantity) FROM InvoiceLine;").fetchone()
# Or Python code like this?
# In[2]:
total_revenue = 0
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
total_revenue += UnitPrice*Quantity
print total_revenue
# ## Example 2 - Revenue per track
#
# Or how about some SQL with a GROUP BY?
# In[3]:
sql = ("SELECT TrackId, sum(UnitPrice*Quantity) "
"FROM InvoiceLine "
"GROUP BY TrackId "
"ORDER BY SUM(UnitPrice*Quantity) DESC, TrackId DESC limit 3;")
for row in curs.execute(sql):
print row
# Or Python where you use a dictionary to group items?
# In[4]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
invoice_revenue = UnitPrice*Quantity
track_revenues[TrackId] = track_revenues.get(TrackId, 0) + invoice_revenue
for track, revenue in sorted(track_revenues.iteritems(),
key=lambda item: (item[1], item[0]), reverse=True)[:3]:
print track, revenue
# # The Split-Apply-Combine Pattern
#
# ## Hadley Wickham
# ## Example 1 - Total Revenue
#
# Ever written SQL like this?
# In[1]:
db = "split-apply-combine_resources/Chinook_Sqlite.sqlite"
import sqlite3
conn = sqlite3.connect(db)
curs = conn.cursor()
print curs.execute("SELECT SUM(UnitPrice*Quantity) FROM InvoiceLine;").fetchone()
# Or Python code like this?
# In[2]:
total_revenue = 0
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
total_revenue += UnitPrice*Quantity
print total_revenue
# ## Example 2 - Revenue per track
#
# Or how about some SQL with a GROUP BY?
# In[3]:
sql = ("SELECT TrackId, sum(UnitPrice*Quantity) "
"FROM InvoiceLine "
"GROUP BY TrackId "
"ORDER BY SUM(UnitPrice*Quantity) DESC, TrackId DESC limit 3;")
for row in curs.execute(sql):
print row
# Or Python where you use a dictionary to group items?
# In[4]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
invoice_revenue = UnitPrice*Quantity
track_revenues[TrackId] = track_revenues.get(TrackId, 0) + invoice_revenue
for track, revenue in sorted(track_revenues.iteritems(),
key=lambda item: (item[1], item[0]), reverse=True)[:3]:
print track, revenue
# # The Split-Apply-Combine Pattern
#
# ## Hadley Wickham  #
# [Hadley Wickham, the man who revolutionized R](http://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/)
#
# *If you don’t spend much of your time coding in the open-source statistical programming language R,
# his name is likely not familiar to you -- but the statistician Hadley Wickham is,
# in his own words, “nerd famous.” The kind of famous where people at statistics conferences
# line up for selfies, ask him for autographs, and are generally in awe of him.
# “It’s utterly utterly bizarre,” he admits.
# “To be famous for writing R programs? It’s just crazy.”*
# In[5]:
from IPython.display import HTML
HTML('')
# ## The Basic Pattern
#
# 1. **Split** the data by some **grouping variable**
# 2. **Apply** some function to each group **independently**
# 3. **Combine** the data into some output dataset
# ### Example 2 - revisited
# In[6]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
invoice_revenue = UnitPrice*Quantity
track_revenues[TrackId] = track_revenues.get(TrackId, 0) + invoice_revenue
print sorted(track_revenues.iteritems(), key=lambda item: (item[1], item[0]), reverse=True)[:3]
# In[7]:
def calc_revenue(row):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
return UnitPrice*Quantity
# In[8]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
track_revenues[row[2]] = track_revenues.get(row[2], 0) + calc_revenue(row)
print sorted(track_revenues.iteritems(), key=lambda item: (item[1], item[0]), reverse=True)[:3]
# # Pandas - Python Data Analysis Library
#
#
#
# [Hadley Wickham, the man who revolutionized R](http://priceonomics.com/hadley-wickham-the-man-who-revolutionized-r/)
#
# *If you don’t spend much of your time coding in the open-source statistical programming language R,
# his name is likely not familiar to you -- but the statistician Hadley Wickham is,
# in his own words, “nerd famous.” The kind of famous where people at statistics conferences
# line up for selfies, ask him for autographs, and are generally in awe of him.
# “It’s utterly utterly bizarre,” he admits.
# “To be famous for writing R programs? It’s just crazy.”*
# In[5]:
from IPython.display import HTML
HTML('')
# ## The Basic Pattern
#
# 1. **Split** the data by some **grouping variable**
# 2. **Apply** some function to each group **independently**
# 3. **Combine** the data into some output dataset
# ### Example 2 - revisited
# In[6]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
invoice_revenue = UnitPrice*Quantity
track_revenues[TrackId] = track_revenues.get(TrackId, 0) + invoice_revenue
print sorted(track_revenues.iteritems(), key=lambda item: (item[1], item[0]), reverse=True)[:3]
# In[7]:
def calc_revenue(row):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
return UnitPrice*Quantity
# In[8]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
track_revenues[row[2]] = track_revenues.get(row[2], 0) + calc_revenue(row)
print sorted(track_revenues.iteritems(), key=lambda item: (item[1], item[0]), reverse=True)[:3]
# # Pandas - Python Data Analysis Library
#
# ![]()
 #
# # MapReduce
#
# * If you want to process Big Data, you need some MapReduce framework like one of the following
#
#
# # MapReduce
#
# * If you want to process Big Data, you need some MapReduce framework like one of the following
#
# ![]() #
# ![]() #
#
 #
# The key to these frameworks is adopting a **functional** [programming] mindset. In Python this means, think **iterators**!
#
# See [The Structure and Interpretation of Computer Programs](https://mitpress.mit.edu/sicp/full-text/book/book.html)
# (the "*Wizard book*")
#
# * in particular [Chapter 2 Building Abstractions with Data](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-13.html#%_chap_2)
# * and [Section 2.2.3 Sequences as Conventional Interfaces](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-15.html#%_sec_2.2.3)
#
# Luckily, the Split-Apply-Combine pattern is well suited to this!
# ## Example 1 - revisited
# In[23]:
total_revenue = 0
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
total_revenue += UnitPrice*Quantity
total_revenue
# In[24]:
reduce(lambda x,y: x+y, map(calc_revenue, curs.execute("SELECT * FROM InvoiceLine;")))
# In[25]:
sum(calc_revenue(row) for row in curs.execute("SELECT * FROM InvoiceLine;"))
# What about **group by** operations?
#
# There is an `itertools.groupby` function in the standard library.
#
# However
#
# * it requires the data to be sorted,
# * returns iterables which are shared with the original iterable.
#
# Hence I find that I usually need to consult the [documentation](https://docs.python.org/2/library/itertools.html#itertools.groupby) to use it correctly.
#
# Use the `toolz` library rather!
# In[26]:
HTML('')
# # PyToolz
# In[27]:
HTML('')
# ## Example 2 - revisited
# In[28]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
track_revenues[row[2]] = track_revenues.get(row[2], 0) + calc_revenue(row)
print sorted(track_revenues.iteritems(), key=lambda item: (item[1], item[0]), reverse=True)[:3]
# In[29]:
from toolz import groupby, valmap
sorted(valmap(sum,
valmap(lambda lst: map(calc_revenue, lst),
groupby(lambda row: row[2],
curs.execute("SELECT * FROM InvoiceLine")))
).iteritems()
, key=lambda t: (t[1], t[0]), reverse=True)[:3]
# In[30]:
from toolz.curried import pipe, groupby, valmap, map, get
pipe(curs.execute("SELECT * FROM InvoiceLine"),
groupby(get(2)),
valmap(map(calc_revenue)),
valmap(sum),
lambda track_revenues: sorted(track_revenues.iteritems(), key=lambda t: (t[1], t[0]), reverse=True)[:3]
)
# In[31]:
HTML('')
# In[32]:
from toolz.curried import reduceby
pipe(curs.execute("SELECT * FROM InvoiceLine"),
reduceby(get(2),
lambda track_revenue, row: track_revenue + calc_revenue(row),
init=0
),
lambda track_revenues: sorted(track_revenues.iteritems(), key=lambda t: (t[1], t[0]), reverse=True)[:3]
)
# ## toolz example - multiprocessing
# In[33]:
import glob
files = glob.glob('C:/ARGO/ARGO/notebooks/articles/github_archive/*')
print len(files), files[:3]
N = len(files) # 10
# In[34]:
def count_types(filename):
import gzip
import json
from collections import Counter
try:
with gzip.open(filename) as f:
return dict(Counter(json.loads(line)['type'] for line in f))
except Exception, e:
print "Error in {!r}: {}".format(filename, e)
return {}
print count_types(files[0])
# In[35]:
from collections import Counter
def update_counts(total_counts, file_counts):
total_counts.update(file_counts)
return total_counts
# In[36]:
get_ipython().run_cell_magic('time', '', 'pmap = map\nprint reduce(update_counts,\n pmap(count_types, files[:N]),\n Counter())\n')
# In[37]:
get_ipython().run_cell_magic('time', '', 'from IPython.parallel import Client\np = Client()[:]\npmap = p.map_sync\nprint reduce(update_counts,\n pmap(count_types, files[:N]),\n Counter())\n')
# # Next time
#
# ## [Blaze](http://blaze.pydata.org/en/latest/)
#
#
#
# The key to these frameworks is adopting a **functional** [programming] mindset. In Python this means, think **iterators**!
#
# See [The Structure and Interpretation of Computer Programs](https://mitpress.mit.edu/sicp/full-text/book/book.html)
# (the "*Wizard book*")
#
# * in particular [Chapter 2 Building Abstractions with Data](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-13.html#%_chap_2)
# * and [Section 2.2.3 Sequences as Conventional Interfaces](https://mitpress.mit.edu/sicp/full-text/book/book-Z-H-15.html#%_sec_2.2.3)
#
# Luckily, the Split-Apply-Combine pattern is well suited to this!
# ## Example 1 - revisited
# In[23]:
total_revenue = 0
for row in curs.execute("SELECT * FROM InvoiceLine;"):
InvoiceLineId, InvoiceId, TrackId, UnitPrice, Quantity = row
total_revenue += UnitPrice*Quantity
total_revenue
# In[24]:
reduce(lambda x,y: x+y, map(calc_revenue, curs.execute("SELECT * FROM InvoiceLine;")))
# In[25]:
sum(calc_revenue(row) for row in curs.execute("SELECT * FROM InvoiceLine;"))
# What about **group by** operations?
#
# There is an `itertools.groupby` function in the standard library.
#
# However
#
# * it requires the data to be sorted,
# * returns iterables which are shared with the original iterable.
#
# Hence I find that I usually need to consult the [documentation](https://docs.python.org/2/library/itertools.html#itertools.groupby) to use it correctly.
#
# Use the `toolz` library rather!
# In[26]:
HTML('')
# # PyToolz
# In[27]:
HTML('')
# ## Example 2 - revisited
# In[28]:
track_revenues = {}
for row in curs.execute("SELECT * FROM InvoiceLine;"):
track_revenues[row[2]] = track_revenues.get(row[2], 0) + calc_revenue(row)
print sorted(track_revenues.iteritems(), key=lambda item: (item[1], item[0]), reverse=True)[:3]
# In[29]:
from toolz import groupby, valmap
sorted(valmap(sum,
valmap(lambda lst: map(calc_revenue, lst),
groupby(lambda row: row[2],
curs.execute("SELECT * FROM InvoiceLine")))
).iteritems()
, key=lambda t: (t[1], t[0]), reverse=True)[:3]
# In[30]:
from toolz.curried import pipe, groupby, valmap, map, get
pipe(curs.execute("SELECT * FROM InvoiceLine"),
groupby(get(2)),
valmap(map(calc_revenue)),
valmap(sum),
lambda track_revenues: sorted(track_revenues.iteritems(), key=lambda t: (t[1], t[0]), reverse=True)[:3]
)
# In[31]:
HTML('')
# In[32]:
from toolz.curried import reduceby
pipe(curs.execute("SELECT * FROM InvoiceLine"),
reduceby(get(2),
lambda track_revenue, row: track_revenue + calc_revenue(row),
init=0
),
lambda track_revenues: sorted(track_revenues.iteritems(), key=lambda t: (t[1], t[0]), reverse=True)[:3]
)
# ## toolz example - multiprocessing
# In[33]:
import glob
files = glob.glob('C:/ARGO/ARGO/notebooks/articles/github_archive/*')
print len(files), files[:3]
N = len(files) # 10
# In[34]:
def count_types(filename):
import gzip
import json
from collections import Counter
try:
with gzip.open(filename) as f:
return dict(Counter(json.loads(line)['type'] for line in f))
except Exception, e:
print "Error in {!r}: {}".format(filename, e)
return {}
print count_types(files[0])
# In[35]:
from collections import Counter
def update_counts(total_counts, file_counts):
total_counts.update(file_counts)
return total_counts
# In[36]:
get_ipython().run_cell_magic('time', '', 'pmap = map\nprint reduce(update_counts,\n pmap(count_types, files[:N]),\n Counter())\n')
# In[37]:
get_ipython().run_cell_magic('time', '', 'from IPython.parallel import Client\np = Client()[:]\npmap = p.map_sync\nprint reduce(update_counts,\n pmap(count_types, files[:N]),\n Counter())\n')
# # Next time
#
# ## [Blaze](http://blaze.pydata.org/en/latest/)
#
#  #
#
# ## [Dask](http://dask.pydata.org/en/latest/)
#
#
#
#
# ## [Dask](http://dask.pydata.org/en/latest/)
#
#  # In[38]:
HTML('')
# # Thank you!
#
# ## If this stuff interests you, let's chat!
# In[38]:
HTML('')
# # Thank you!
#
# ## If this stuff interests you, let's chat!