#!/usr/bin/env python
# coding: utf-8
# # TensorFlow
#
# ## Sobre TensoFlow
#
# [TensorFlow](https://www.tensorflow.org/) es una biblioteca open source desarrollada por Google que nos permite realizar cálculos numéricos usando diagramas de flujo de datos. Los nodos del gráfico representan operaciones matemáticas, mientras que los bordes del gráfico representan los arreglos de datos multidimensionales (tensores) comunicados entre ellos. Esta arquitectura flexible le permite realizar los cálculos en más de un CPU o GPU utilizando la misma API.
#
# ## ¿Qué es un diagrama de flujo de datos?
#
# Los diagramas de flujo de datos describen cálculos matemáticos con un gráfico de direcciones de nodos y bordes. Los nodos normalmente implementan operaciones matemáticas, pero también pueden representar los puntos para alimentarse de datos, devolver resultados, o leer / escribir variables persistentes. Los bordes describen las relaciones de entrada / salida entre los nodos. Estos bordes están representados por los arreglos de datos multidimensionales o tensores. El flujo de los tensores a través del gráfico es de donde [TensorFlow](https://www.tensorflow.org/) recibe su nombre. Los nodos se asignan a los dispositivos computacionales y se ejecutan de forma asincronica y en paralelo una vez que todos los tensores en los bordes de entrada están disponibles.
#
# 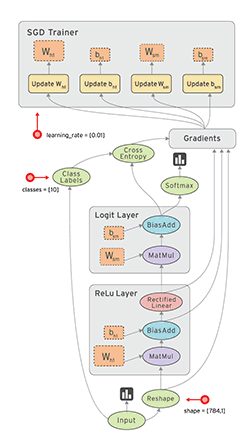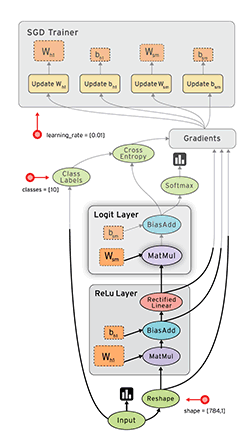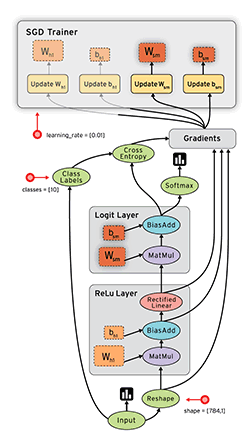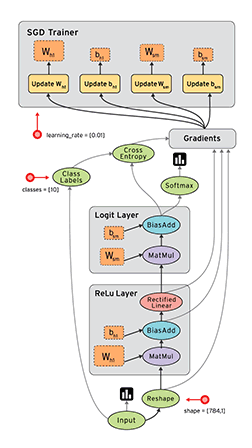 # ## Operaciones básicas con TensorFlow
# In[3]:
# importamos librerias
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
# ### Constantes en TensorFlow
# In[3]:
# Creación de Constantes
# El valor que retorna el constructor es el valor de la constante.
# creamos constantes a=2 y b=3
a = tf.constant(2)
b = tf.constant(3)
# In[4]:
# Todo en TensorFlow ocurre dentro de una Sesión
# creamos la sesion y realizamos algunas operaciones con las constantes
# y lanzamos la sesión
with tf.Session() as sess:
print("Suma de las constantes: {}".format(sess.run(a+b)))
print("Multiplicación de las constantes: {}".format(sess.run(a*b)))
print("Constante elevada al cubo: {}".format(sess.run(a**3)))
# ### Variables simbólicas en TensorFlow
# In[5]:
# Utilizando variables simbólicas en los grafos
# El valor que devuelve el constructor representa el la salida de la
# variable (la entrada de la variable se define en la sesion)
# Creamos dos variables de tipo integer
a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
# In[6]:
# Defininimos algunas operaciones con estas variables
suma = tf.add(a, b)
mult = tf.mul(a, b)
# In[7]:
# Iniciamos la sesion
with tf.Session() as sess:
# ejecutamos las operaciones con cualquier imput que quisiésemos
print("suma con variables: {}".format(sess.run(suma,
feed_dict={a: 4, b: 5})))
print("Multiplicación con variables: {}".format(sess.run(mult,
feed_dict={a: 4, b: 5})))
# ### Operaciones con matrices
# In[8]:
# Creamos las matrices como constantes
# matrices de 3x3
matriz1 = tf.constant([[1, 3, 2],
[1, 0, 0],
[1, 2, 2]])
matriz2 = tf.constant([[1, 0, 5],
[7, 5, 0],
[2, 1, 1]])
# suma de matrices
suma = tf.add(matriz1, matriz2)
# producto de matrices
mult = tf.matmul(matriz1, matriz2)
# In[9]:
# lanzamos la sesion
with tf.Session() as sess:
print("Suma de matrices: \n{}".format(sess.run(suma)))
print("Producto de matrices: \n{}".format(sess.run(mult)))
# ## Ejemplos de TensorFlow con MNIST dataset
#
#
# ## MNIST dataset
#
# [MNIST](http://colah.github.io/posts/2014-10-Visualizing-MNIST/) es un simple conjunto de datos para reconocimiento de imágenes por computadora. Se compone de imágenes de dígitos escritos a mano como los siguientes:
#
#
# ## Operaciones básicas con TensorFlow
# In[3]:
# importamos librerias
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
# ### Constantes en TensorFlow
# In[3]:
# Creación de Constantes
# El valor que retorna el constructor es el valor de la constante.
# creamos constantes a=2 y b=3
a = tf.constant(2)
b = tf.constant(3)
# In[4]:
# Todo en TensorFlow ocurre dentro de una Sesión
# creamos la sesion y realizamos algunas operaciones con las constantes
# y lanzamos la sesión
with tf.Session() as sess:
print("Suma de las constantes: {}".format(sess.run(a+b)))
print("Multiplicación de las constantes: {}".format(sess.run(a*b)))
print("Constante elevada al cubo: {}".format(sess.run(a**3)))
# ### Variables simbólicas en TensorFlow
# In[5]:
# Utilizando variables simbólicas en los grafos
# El valor que devuelve el constructor representa el la salida de la
# variable (la entrada de la variable se define en la sesion)
# Creamos dos variables de tipo integer
a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
# In[6]:
# Defininimos algunas operaciones con estas variables
suma = tf.add(a, b)
mult = tf.mul(a, b)
# In[7]:
# Iniciamos la sesion
with tf.Session() as sess:
# ejecutamos las operaciones con cualquier imput que quisiésemos
print("suma con variables: {}".format(sess.run(suma,
feed_dict={a: 4, b: 5})))
print("Multiplicación con variables: {}".format(sess.run(mult,
feed_dict={a: 4, b: 5})))
# ### Operaciones con matrices
# In[8]:
# Creamos las matrices como constantes
# matrices de 3x3
matriz1 = tf.constant([[1, 3, 2],
[1, 0, 0],
[1, 2, 2]])
matriz2 = tf.constant([[1, 0, 5],
[7, 5, 0],
[2, 1, 1]])
# suma de matrices
suma = tf.add(matriz1, matriz2)
# producto de matrices
mult = tf.matmul(matriz1, matriz2)
# In[9]:
# lanzamos la sesion
with tf.Session() as sess:
print("Suma de matrices: \n{}".format(sess.run(suma)))
print("Producto de matrices: \n{}".format(sess.run(mult)))
# ## Ejemplos de TensorFlow con MNIST dataset
#
#
# ## MNIST dataset
#
# [MNIST](http://colah.github.io/posts/2014-10-Visualizing-MNIST/) es un simple conjunto de datos para reconocimiento de imágenes por computadora. Se compone de imágenes de dígitos escritos a mano como los siguientes:
#
#  #
# Para más información sobre el dataset visitar el siguiente [enlace](http://colah.github.io/posts/2014-10-Visualizing-MNIST/)
# In[4]:
# importando el dataset
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# ## Explorando MNIST dataset
# In[11]:
# forma del dataset 55000 imagenes
mnist.train.images.shape
# In[88]:
# cada imagen es un array de 28x28 con cada pixel
# definido como escala de grises.
digito1 = mnist.train.images[0].reshape((28, 28))
# In[42]:
# visualizando el primer digito
plt.imshow(digito1, cmap = cm.Greys)
plt.show()
# In[18]:
# valor correcto
mnist.train.labels[0].nonzero()[0][0]
# In[12]:
# 2da imagen como escala de grises
sns.heatmap(mnist.train.images[1].reshape((28, 28)), linewidth=0,
xticklabels=False, yticklabels=False)
plt.show()
# In[19]:
# valor correcto
mnist.train.labels[1].nonzero()[0][0]
# In[82]:
# visualizando imagenes de 5 en 5
def visualizar_imagenes(dataset, cant_img):
img_linea = 5
lineas = int(cant_img / img_linea)
imagenes = []
for i in range(lineas):
datos = []
for img in dataset[img_linea* i:img_linea* (i+1)]:
datos.append(img.reshape((28,28)))
imgs = np.hstack(datos)
imagenes.append(imgs)
data = np.vstack(imagenes)
plt.imshow(data, cmap = cm.Greys )
plt.show()
# In[89]:
# visualizando los primeros 30 dígitos
plt.figure(figsize=(8, 8))
visualizar_imagenes(mnist.train.images, 30)
# ## Ejemplo con perceptron multicapa
#
# Un [peceptron multicapa](https://es.wikipedia.org/wiki/Perceptr%C3%B3n) es una de las redes neuronales más simples.
# In[12]:
# Parametros
learning_rate = 0.001
training_epochs = 15
batch_size = 100
display_step = 1
model_path = "/home/raul/python/notebooks/perceptron.ckpt"
logs_path = "/home/raul/python/notebooks/tensorflow_logs/perceptron"
# Parametros de la red
n_hidden_1 = 256 # 1ra capa de atributos
n_hidden_2 = 256 # 1ra capa de atributos
n_input = 784 # datos de MNIST(forma img: 28*28)
n_classes = 10 # Total de clases a clasificar (0-9 digitos)
# input para los grafos
x = tf.placeholder("float", [None, n_input], name='DatosEntrada')
y = tf.placeholder("float", [None, n_classes], name='Clases')
# In[13]:
# Creamos el modelo
def multilayer_perceptron(x, weights, biases):
# Función de activación de la capa escondida
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Función de activación de la capa escondida
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Salida con activación lineal
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# In[14]:
# Definimos los pesos y sesgo de cada capa.
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
with tf.name_scope('Modelo'):
# Construimos el modelo
pred = multilayer_perceptron(x, weights, biases)
with tf.name_scope('Costo'):
# Definimos las funciones de optimización
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
with tf.name_scope('optimizador'):
# optimización
optimizer = tf.train.AdamOptimizer(
learning_rate=learning_rate).minimize(cost)
with tf.name_scope('Precision'):
# Evaluar el modelo
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calcular la precisión
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# Inicializamos todas las variables
init = tf.initialize_all_variables()
# Crear sumarización para controlar el costo
tf.scalar_summary("Costo", cost)
# Crear sumarización para controlar la precisión
tf.scalar_summary("Precision", accuracy)
# Juntar los resumenes en una sola operación
merged_summary_op = tf.merge_all_summaries()
# Para guardar el modelo
saver = tf.train.Saver()
# In[15]:
# Lanzamos la sesión
with tf.Session() as sess:
sess.run(init)
# op to write logs to Tensorboard
summary_writer = tf.train.SummaryWriter(
logs_path, graph=tf.get_default_graph())
# Entrenamiento
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Optimización por backprop y funcion de costo
_, c, summary = sess.run([optimizer, cost, merged_summary_op],
feed_dict={x: batch_x, y: batch_y})
# escribir logs en cada iteracion
summary_writer.add_summary(summary, epoch * total_batch + i)
# perdida promedio
avg_cost += c / total_batch
# imprimir información de entrenamiento
if epoch % display_step == 0:
print("Iteración: {0: 04d} costo = {1:.9f}".format(epoch+1,
avg_cost))
print("Optimización Terminada!\n")
print("Precisión: {0:.2f}".format(accuracy.eval({x: mnist.test.images,
y: mnist.test.labels})))
# guardar el modelo, luego lo podemos cargar con saver.restore
save_path = saver.save(sess, model_path)
print("Modelo guardado en archivo: {}".format(save_path))
print("Ejecutar el comando:\n",
"--> tensorboard --logdir=/home/raul/python/notebooks/tensorflow_logs ",
"\nLuego abir http://0.0.0.0:6006/ en el navegador")
# ## [Red neuronal convolucional de multiples capas](https://es.wikipedia.org/wiki/Redes_neuronales_convolucionales)
# In[16]:
# Parametros
learning_rate = 0.001
training_iters = 200000
batch_size = 128
display_step = 10
model_path = "/home/raul/python/notebooks/red_conv.ckpt"
logs_path = "/home/raul/python/notebooks/tensorflow_logs/red_conv"
# Parametros de la red
n_input = 784 # datos de MNIST (forma img: 28*28)
n_classes = 10 # Total de clases a clasificar (0-9 digitos)
dropout = 0.75 # descarte, probabilidad para mantener las unidades
# input para los grafos
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32) # para descarte
# In[17]:
# Creando funciones auxiliares y el modelo
def conv2d(x, W, b, strides=1):
# Conv2D con sesgo y activación relu.
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def maxpool2d(x, k=2):
# MaxPool2D
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME')
# Creando la rede
def conv_net(x, weights, biases, dropout):
# cambiando la forma de la imagen
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# capa de convulción 1
conv1 = conv2d(x, weights['wc1'], biases['bc1'])
# Max Pooling
conv1 = maxpool2d(conv1, k=2)
# capa de convulción 2
conv2 = conv2d(conv1, weights['wc2'], biases['bc2'])
# Max Pooling
conv2 = maxpool2d(conv2, k=2)
# capa de conexiones
fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
# aplicando el descarte
fc1 = tf.nn.dropout(fc1, dropout)
# Salida, predicción de la clase.
out = tf.add(tf.matmul(fc1, weights['out']), biases['out'])
return out
# In[18]:
# Definimos los pesos y sesgo de cada capa.
weights = {
# 5x5 conv, 1 entrada, 32 salidas
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
# 5x5 conv, 32 entradas, 64 salidas
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
# totalmente conectada, 7*7*64 entradas, 1024 salidas
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
# 1024 entradas, 10 salidas (prediccion)
'out': tf.Variable(tf.random_normal([1024, n_classes]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# Construcción del modelo
pred = conv_net(x, weights, biases, keep_prob)
# definiendo las funciones de optimización
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Evaluando el modelo
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Inicializando las variables
init = tf.initialize_all_variables()
# Para guardar el modelo
saver = tf.train.Saver()
# In[19]:
# Lanzando la sesion
with tf.Session() as sess:
sess.run(init)
step = 1
# mantener entrenando hasta alcanzar el maximo de iteraciones
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y,
keep_prob: dropout})
if step % display_step == 0:
# Calcular la perdida y la precisión del lote
loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x,
y: batch_y,
keep_prob: 1.})
print("Iteración {0:}, perdida = {1:.6f}, Precisión = {2:.5f}"
.format(str(step*batch_size), loss, acc))
step += 1
print("Optimización terminada!")
# Calcular la precisión sobre el dateset de evaluación.
print("Testing Accuracy: {0: .2f}".format(
sess.run(accuracy, feed_dict={x: mnist.test.images[:256],
y: mnist.test.labels[:256],
keep_prob: 1.})))
# guardar el modelo, luego lo podemos cargar con saver.restore
save_path = saver.save(sess, model_path)
print("Modelo guardado en archivo: {}".format(save_path))
# ## Ejemplo con Regresión Softmax
# La [regresión softmax](https://es.wikipedia.org/wiki/Regresi%C3%B3n_log%C3%ADstica_multinomial) es una generalización del clásico modelo de [regresión logística](https://es.wikipedia.org/wiki/Regresi%C3%B3n_log%C3%ADstica) para los casos en que tenemos que clasificar más de dos *clases*. Con [TensorFlow](https://www.tensorflow.org/) se puede implementar de forma muy sencilla.
# In[20]:
# definimos la variable simbólica para para realizar los computos
x = tf.placeholder(tf.float32, [None, 784])
# In[21]:
# definimos dos variables para los parámetros y los iniciamos con ceros
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# In[22]:
# definimos el modelo de regresion multinominal.
y = tf.nn.softmax(tf.matmul(x, W) + b)
# ### Entrenamiento
# In[23]:
# definimos una variable simbólica para los resultados.
y_ = tf.placeholder(tf.float32, [None, 10])
# aplicamos entropia cruzada
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),
reduction_indices=[1]))
# definimos el proceso de entrenamiento aplicando el algoritmo de
# gradiente descendiente optimizando al mínimo la entropia cruzada
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# iniciamos todas las variables
init = tf.initialize_all_variables()
# In[24]:
# lanzamos la sesion
with tf.Session() as sess:
sess.run(init)
# entrenamos el modelo
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# evaluamos el modelo
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# imprimimos precision
print("Precisión: {0: .2f}".format(sess.run(accuracy,
feed_dict={x: mnist.test.images, y_: mnist.test.labels})))
#
# Para más información sobre el dataset visitar el siguiente [enlace](http://colah.github.io/posts/2014-10-Visualizing-MNIST/)
# In[4]:
# importando el dataset
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# ## Explorando MNIST dataset
# In[11]:
# forma del dataset 55000 imagenes
mnist.train.images.shape
# In[88]:
# cada imagen es un array de 28x28 con cada pixel
# definido como escala de grises.
digito1 = mnist.train.images[0].reshape((28, 28))
# In[42]:
# visualizando el primer digito
plt.imshow(digito1, cmap = cm.Greys)
plt.show()
# In[18]:
# valor correcto
mnist.train.labels[0].nonzero()[0][0]
# In[12]:
# 2da imagen como escala de grises
sns.heatmap(mnist.train.images[1].reshape((28, 28)), linewidth=0,
xticklabels=False, yticklabels=False)
plt.show()
# In[19]:
# valor correcto
mnist.train.labels[1].nonzero()[0][0]
# In[82]:
# visualizando imagenes de 5 en 5
def visualizar_imagenes(dataset, cant_img):
img_linea = 5
lineas = int(cant_img / img_linea)
imagenes = []
for i in range(lineas):
datos = []
for img in dataset[img_linea* i:img_linea* (i+1)]:
datos.append(img.reshape((28,28)))
imgs = np.hstack(datos)
imagenes.append(imgs)
data = np.vstack(imagenes)
plt.imshow(data, cmap = cm.Greys )
plt.show()
# In[89]:
# visualizando los primeros 30 dígitos
plt.figure(figsize=(8, 8))
visualizar_imagenes(mnist.train.images, 30)
# ## Ejemplo con perceptron multicapa
#
# Un [peceptron multicapa](https://es.wikipedia.org/wiki/Perceptr%C3%B3n) es una de las redes neuronales más simples.
# In[12]:
# Parametros
learning_rate = 0.001
training_epochs = 15
batch_size = 100
display_step = 1
model_path = "/home/raul/python/notebooks/perceptron.ckpt"
logs_path = "/home/raul/python/notebooks/tensorflow_logs/perceptron"
# Parametros de la red
n_hidden_1 = 256 # 1ra capa de atributos
n_hidden_2 = 256 # 1ra capa de atributos
n_input = 784 # datos de MNIST(forma img: 28*28)
n_classes = 10 # Total de clases a clasificar (0-9 digitos)
# input para los grafos
x = tf.placeholder("float", [None, n_input], name='DatosEntrada')
y = tf.placeholder("float", [None, n_classes], name='Clases')
# In[13]:
# Creamos el modelo
def multilayer_perceptron(x, weights, biases):
# Función de activación de la capa escondida
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Función de activación de la capa escondida
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Salida con activación lineal
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# In[14]:
# Definimos los pesos y sesgo de cada capa.
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
with tf.name_scope('Modelo'):
# Construimos el modelo
pred = multilayer_perceptron(x, weights, biases)
with tf.name_scope('Costo'):
# Definimos las funciones de optimización
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
with tf.name_scope('optimizador'):
# optimización
optimizer = tf.train.AdamOptimizer(
learning_rate=learning_rate).minimize(cost)
with tf.name_scope('Precision'):
# Evaluar el modelo
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calcular la precisión
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# Inicializamos todas las variables
init = tf.initialize_all_variables()
# Crear sumarización para controlar el costo
tf.scalar_summary("Costo", cost)
# Crear sumarización para controlar la precisión
tf.scalar_summary("Precision", accuracy)
# Juntar los resumenes en una sola operación
merged_summary_op = tf.merge_all_summaries()
# Para guardar el modelo
saver = tf.train.Saver()
# In[15]:
# Lanzamos la sesión
with tf.Session() as sess:
sess.run(init)
# op to write logs to Tensorboard
summary_writer = tf.train.SummaryWriter(
logs_path, graph=tf.get_default_graph())
# Entrenamiento
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Optimización por backprop y funcion de costo
_, c, summary = sess.run([optimizer, cost, merged_summary_op],
feed_dict={x: batch_x, y: batch_y})
# escribir logs en cada iteracion
summary_writer.add_summary(summary, epoch * total_batch + i)
# perdida promedio
avg_cost += c / total_batch
# imprimir información de entrenamiento
if epoch % display_step == 0:
print("Iteración: {0: 04d} costo = {1:.9f}".format(epoch+1,
avg_cost))
print("Optimización Terminada!\n")
print("Precisión: {0:.2f}".format(accuracy.eval({x: mnist.test.images,
y: mnist.test.labels})))
# guardar el modelo, luego lo podemos cargar con saver.restore
save_path = saver.save(sess, model_path)
print("Modelo guardado en archivo: {}".format(save_path))
print("Ejecutar el comando:\n",
"--> tensorboard --logdir=/home/raul/python/notebooks/tensorflow_logs ",
"\nLuego abir http://0.0.0.0:6006/ en el navegador")
# ## [Red neuronal convolucional de multiples capas](https://es.wikipedia.org/wiki/Redes_neuronales_convolucionales)
# In[16]:
# Parametros
learning_rate = 0.001
training_iters = 200000
batch_size = 128
display_step = 10
model_path = "/home/raul/python/notebooks/red_conv.ckpt"
logs_path = "/home/raul/python/notebooks/tensorflow_logs/red_conv"
# Parametros de la red
n_input = 784 # datos de MNIST (forma img: 28*28)
n_classes = 10 # Total de clases a clasificar (0-9 digitos)
dropout = 0.75 # descarte, probabilidad para mantener las unidades
# input para los grafos
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32) # para descarte
# In[17]:
# Creando funciones auxiliares y el modelo
def conv2d(x, W, b, strides=1):
# Conv2D con sesgo y activación relu.
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
def maxpool2d(x, k=2):
# MaxPool2D
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME')
# Creando la rede
def conv_net(x, weights, biases, dropout):
# cambiando la forma de la imagen
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# capa de convulción 1
conv1 = conv2d(x, weights['wc1'], biases['bc1'])
# Max Pooling
conv1 = maxpool2d(conv1, k=2)
# capa de convulción 2
conv2 = conv2d(conv1, weights['wc2'], biases['bc2'])
# Max Pooling
conv2 = maxpool2d(conv2, k=2)
# capa de conexiones
fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1'])
fc1 = tf.nn.relu(fc1)
# aplicando el descarte
fc1 = tf.nn.dropout(fc1, dropout)
# Salida, predicción de la clase.
out = tf.add(tf.matmul(fc1, weights['out']), biases['out'])
return out
# In[18]:
# Definimos los pesos y sesgo de cada capa.
weights = {
# 5x5 conv, 1 entrada, 32 salidas
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
# 5x5 conv, 32 entradas, 64 salidas
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
# totalmente conectada, 7*7*64 entradas, 1024 salidas
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
# 1024 entradas, 10 salidas (prediccion)
'out': tf.Variable(tf.random_normal([1024, n_classes]))
}
biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# Construcción del modelo
pred = conv_net(x, weights, biases, keep_prob)
# definiendo las funciones de optimización
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Evaluando el modelo
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Inicializando las variables
init = tf.initialize_all_variables()
# Para guardar el modelo
saver = tf.train.Saver()
# In[19]:
# Lanzando la sesion
with tf.Session() as sess:
sess.run(init)
step = 1
# mantener entrenando hasta alcanzar el maximo de iteraciones
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y,
keep_prob: dropout})
if step % display_step == 0:
# Calcular la perdida y la precisión del lote
loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x,
y: batch_y,
keep_prob: 1.})
print("Iteración {0:}, perdida = {1:.6f}, Precisión = {2:.5f}"
.format(str(step*batch_size), loss, acc))
step += 1
print("Optimización terminada!")
# Calcular la precisión sobre el dateset de evaluación.
print("Testing Accuracy: {0: .2f}".format(
sess.run(accuracy, feed_dict={x: mnist.test.images[:256],
y: mnist.test.labels[:256],
keep_prob: 1.})))
# guardar el modelo, luego lo podemos cargar con saver.restore
save_path = saver.save(sess, model_path)
print("Modelo guardado en archivo: {}".format(save_path))
# ## Ejemplo con Regresión Softmax
# La [regresión softmax](https://es.wikipedia.org/wiki/Regresi%C3%B3n_log%C3%ADstica_multinomial) es una generalización del clásico modelo de [regresión logística](https://es.wikipedia.org/wiki/Regresi%C3%B3n_log%C3%ADstica) para los casos en que tenemos que clasificar más de dos *clases*. Con [TensorFlow](https://www.tensorflow.org/) se puede implementar de forma muy sencilla.
# In[20]:
# definimos la variable simbólica para para realizar los computos
x = tf.placeholder(tf.float32, [None, 784])
# In[21]:
# definimos dos variables para los parámetros y los iniciamos con ceros
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# In[22]:
# definimos el modelo de regresion multinominal.
y = tf.nn.softmax(tf.matmul(x, W) + b)
# ### Entrenamiento
# In[23]:
# definimos una variable simbólica para los resultados.
y_ = tf.placeholder(tf.float32, [None, 10])
# aplicamos entropia cruzada
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),
reduction_indices=[1]))
# definimos el proceso de entrenamiento aplicando el algoritmo de
# gradiente descendiente optimizando al mínimo la entropia cruzada
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# iniciamos todas las variables
init = tf.initialize_all_variables()
# In[24]:
# lanzamos la sesion
with tf.Session() as sess:
sess.run(init)
# entrenamos el modelo
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# evaluamos el modelo
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# imprimimos precision
print("Precisión: {0: .2f}".format(sess.run(accuracy,
feed_dict={x: mnist.test.images, y_: mnist.test.labels})))